この記事はエイチームブライズ/エイチームコネクト/エイチーム引越し侍 Advent Calendar 2018 5日目の記事です。
概要
こんにちは、データアナリストの@k_0120です。
データ分析界隈ではとても有名な「TJO」こと尾崎隆さんご出演の動画。
【自己紹介】
— TJO (bereavement leave) (@TJO_datasci) 2018年11月24日
これまでの来歴については以下の5つのリンクをご参照ください。Twitterでは何一つ有益な情報を発信しておりませんので、ブログの方をお読みください。https://t.co/BywtEfnMdXhttps://t.co/r0KRHNthfUhttps://t.co/4pVgogSJBShttps://t.co/EZ9VO9bH7Ehttps://t.co/7BzFg96ctl
今回はこちらの動画で紹介されている手法を推測した上で、実装までの流れと実装方法を紹介します。
※あくまで推測です。
※筆者は機械学習初心者のため、間違いなどございましたらコメントにてご指摘いただけますと幸いです。
忙しい人向けに動画の内容をまとめると、
やっていることは単純で、Google Natural Language APIで広告タイトル・広告文を単語レベルに分解してBoWを作り、これを特徴量としてモデリングした上でパフォーマンス向上に寄与する順に単語をリストアップする仕組みです。あとはそれに従ってクリエイティブを作るだけ https://t.co/24N6rycRUt
— TJO (@TJO_datasci) 2018年6月16日
ということです。
必要なもの
- GCP(GoogleCloudPlatform)のアカウント
- GoogleAdWordsのアカウント
全体の流れ
- BigQueryにAdWordsのデータを転送する
- 転送したAdWordsのデータを元に、必要なデータを抽出したビューを作成する
- CloudDatalab上でモデル作成用のデータフレームを作成する
- 目的変数をCVR、説明変数を単語の出現回数として回帰分析のモデルを作成して、パフォーマンス向上に寄与する順に出力
1. BigQueryにAdWordsのデータを転送する
GCPよりBigQueryへアクセスします。
後はコチラの公式サイトの手順をご参考ください。
2. 転送したAdWordsのデータを元に、必要なデータを抽出したビューを作成する
今回、AdWordsのデータ抽出用に書いたクエリが下記になります。
select
a.HeadlinePart1, -- 広告見出し1
a.HeadlinePart2, -- 広告見出し2
a.Description, -- 説明文
sum(ads.Impressions) as Impression, -- 合計広告表示回数
sum(ads.Clicks) as Click, -- 合計広告クリック回数
sum(ads.Conversions) as Conversion, -- 合計コンバージョン数
round((cast(sum(ads.Clicks) as float64) / cast(nullif(sum(ads.Impressions), 0) as float64)) * 100, 2) as Ctr, -- クリック率
round((cast(sum(ads.Conversions) as float64) / cast(nullif(sum(ads.Clicks), 0) as float64) * 100), 2) as Cvr -- コンバージョン率
from
`{GCPのプロジェクトID}.{転送したデータセット名}.p_Ad_{カスタマーID}` as a
inner join
`{GCPのプロジェクトID}.{転送したデータセット名}.p_AdStats_{カスタマーID}` as ads
on
a.AdGroupId = ads.AdGroupId
and a.CampaignId = ads.CampaignId
and a.CreativeId = ads.CreativeId
and ads.Device = 'HIGH_END_MOBILE' -- スマホに限る
and ads.Date >= date_sub(current_date, INTERVAL 3 MONTH) -- 直近3ヶ月分のデータに限る
where
a.Status = 'ENABLED' -- 利用中の広告に限る
and a.Description is not null -- 説明文が空欄の広告を除く
group by
a.HeadlinePart1, a.HeadlinePart2, a.Description
having
sum(ads.Impressions) > 0 -- 広告表示回数が0より大きい
and sum(ads.Clicks) > 0 -- 広告クリック回数が0より大きい
and sum(ads.Conversions) > 0 -- コンバージョン数が0より大きい
order by
Cvr desc, Ctr desc
上記クエリにより抽出した結果をビューとして保存します。
※この後登場するCloudDatalab上で上記クエリを記載してもいいのですが、CloudDatalab上の記述を出来る限りシンプルにしたかったので、今回はビューを作成することにしました。
3. CloudDatalab上でモデル作成用のデータフレームを作成する
GCP上でコンソールを開き、
$ datalab create インスタンス名
$ datalab connect インスタンス名
で、CloudDatalabへアクセスします。
続いて、notebook上での作業となります。
まずはGoogleNaturalLanguageAPIを利用して広告文を品詞分解していきます。
分解したものの中から名詞のみを抽出し、広告ごとに名詞の出現回数とCVRをデータフレームに格納していきます。
※日本語を品詞分解する場合、MeCabの方が精度は高いのですが、今回は手軽さを優先しGoogleNaturalLanguageAPIを採用することにしました。
カーネルをpython3とした上で、
import pandas as pd
import numpy as np
from pandas.io import gbq
# GCPのプロジェクトID
projectId = {GoogleCloudPlatformのプロジェクトID}
# BigQueryに格納されているAdWordsのデータを抽出するクエリ
query = '''\
select \
* \
from \
`{GCPのプロジェクトID}.{転送したデータセット名}.{手順2で作成したビュー名}` \
'''
# データ抽出
result = pd.read_gbq(query, projectId, dialect='standard')
import requests
from collections import Counter
# APIキー
apiKey = '{GCP上で発行したAPIキー}'
# NaturalLanguageAPIのURL
url = 'https://language.googleapis.com/v1/documents:analyzeSyntax?key=' + apiKey
header = {
'Content-Type': 'application/json'
}
# モデル作成用のデータフレームを作成
df = pd.DataFrame()
# BoWを作成
for index, row in results.iterrows():
text = str(row['HeadlinePart1']) + ' ' + str(row['HeadlinePart2']) + ' ' + str(row['Description'])
body = {
"document": {
"type": "PLAIN_TEXT",
"language": "JA",
"content": text
},
"encodingType": "UTF8"
}
# json形式で結果を受け取る
response = requests.post(url, headers=header, json=body).json()
# 行追加用のデータフレーム作成
concatDf = pd.DataFrame()
# 名詞のみ抽出し、データフレームに格納
for i in response['tokens']:
if i['partOfSpeech']['tag'] == 'NOUN':
if not i['text']['content'] in concatDf:
concatDf[i['text']['content']] = [1]
else:
concatDf[i['text']['content']] = concatDf[i['text']['content']] + np.array([1])
concatDf['cvr'] = row['Cvr']
df = pd.concat([df, concatDf], ignore_index=True)
# 欠損値を0埋め
df = df.fillna(0)
4. 目的変数をCVR、説明変数を単語の出現回数として回帰分析のモデルを作成して、パフォーマンス向上に寄与する順に出力
import statsmodels.formula.api as smf
# 目的変数と説明変数に分離
y = df['cvr']
df = df.drop('cvr', axis=1)
x = df
# 重回帰分析のモデル作成
model = smf.OLS(y,x)
result = model.fit()
# 偏回帰係数、t値、p値のデータフレームを作成
coef = np.fabs(result.params)
coefDf = pd.DataFrame({'coef':coef})
tval = np.fabs(result.tvalues)
tvalDf = pd.DataFrame({'tval':tval})
pvalDf = pd.DataFrame({'pval':result.pvalues})
resultDf = pd.concat([coefDf, tvalDf, pvalDf], axis=1)
# 偏回帰係数を降順として出力
print(resultDf.sort_values('coef', ascending=False)
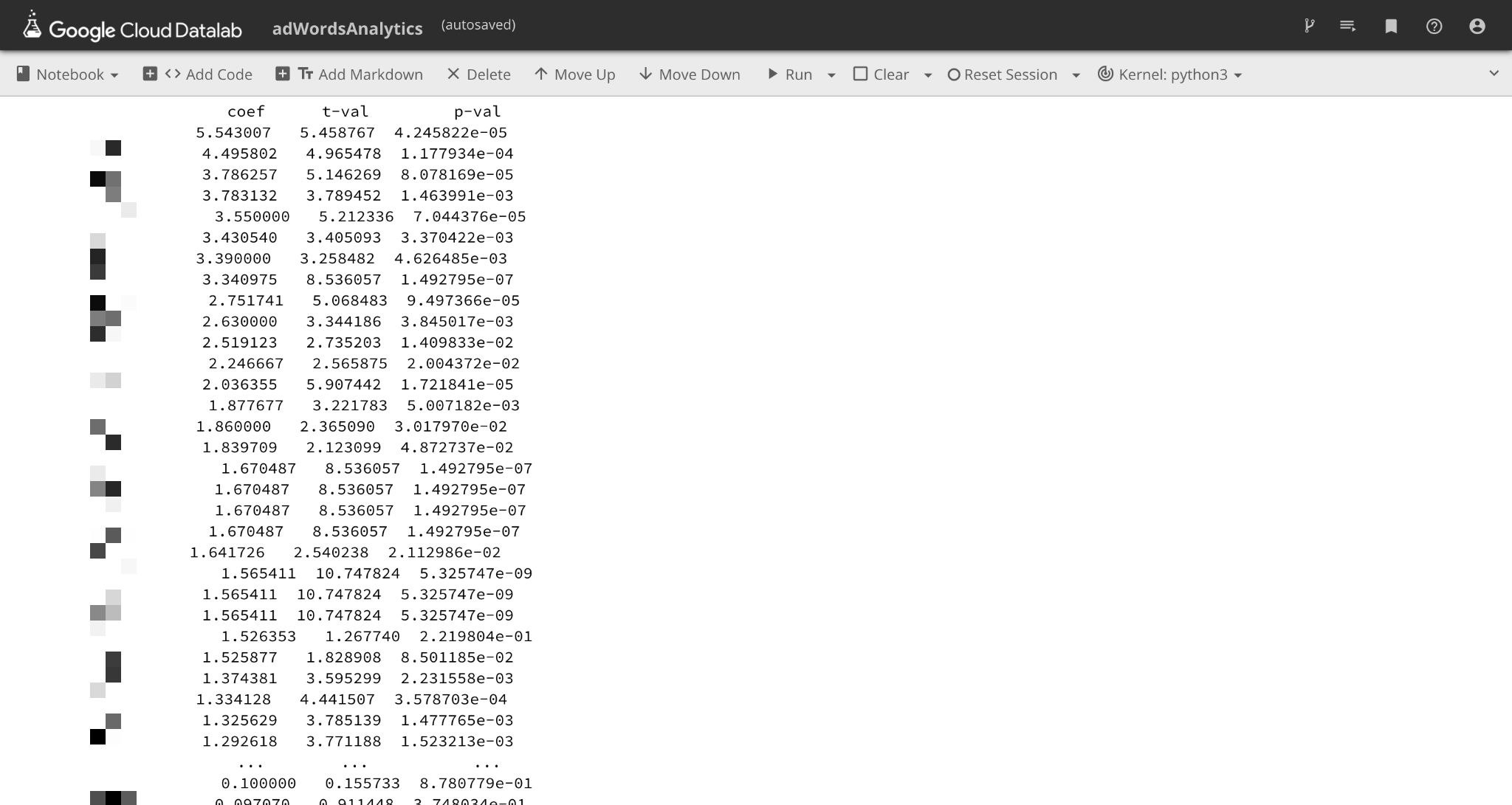
出力結果
各単語に対して、偏回帰係数の絶対値、t値の絶対値、p値を出力しています。
※会社の都合上、単語の開示ができないためモザイクをかけさせていただいております。
まとめ
残念ながら今回は本記事の執筆に追われてしまい、出力結果をもとに検証を行う時間をとることができませんでした。
しかし出力結果を見てみると、上位に出てきて当然の単語もあれば、想定していなかった以外な単語もでてきており、新しい視点でのリスティング広告改善ができそうです!
そして、エンジニアではない自分でもアドベントカレンダーに参加させてくれた会社に対して感謝すると共に、今回の記事を執筆する上で相談相手になってくださった@phigasuiさんに「ありがとう」を伝えたいと思います。
お知らせ
エイチームグループでは一緒に活躍してくれる優秀な人材を募集中です。
興味のある方はぜひともエイチームグループ採用ページ(Webエンジニア詳細ページ)よりお問い合わせ下さい。
明日
明日は新卒エンジニアの@fussy113さんです。
何やらRubyとVue.jsを使って面白いものを作るらしい。
たまにドラえもんのようなコントラストの服を着てくるので、ひみつ道具のようなお役立ちコンテンツなんだろうなー。(チラッ