0. はじめに
第2回 金融データ活用チャレンジ(金融データの活用可能性を深化させる業界を挙げた超実践プログラム)のコンペに参加しました。本コンペについては、第1回も参加したのですが、前回はDatabricksの環境のみでデータ参照・コード開発ができないという条件となっていました。当初は、環境に慣れることができず機能も理解できなかったのですが、終了10日前くらいになり、MLFlowのモデル管理など大変便利な機能があることを知り驚きました。今回は、是非様々な機能を活用してみたいなと思い臨んだのですが、MLクラスターが使える様になったのが2024−02−09からであったこともあり、あまり時間がとれませんでした。
今回は、[第2回 金融データ活用チャレンジ]のデータやその参照元となったShould This Loan be Approved or Denied?ではなく、U.S. Small Business
AdministrationがFOIA(Freedom of Information Act: 情報自由法)に基づき公開しているhttps://data.sba.gov/dataset/7-a-504-foiaをDatabricksで分析しながら、コンペのインサイトが得られるか実践してみます。(=> 結果的に関係があまりなく、得られてなかった。)
ところで、Should This Loan be Approved or Denied?はhttps://data.sba.gov/dataset/7-a-504-foiaと異なるデータ構造であり、過年度https://data.sba.gov/dataset/7-a-504-foiaにおいて公開されていたデータなのか不明ですが、ライセンスがCC BY-SA 4.0となっているため、コンペのルールにもCC BY-SA 4.0である旨明示すべきなのでは?と思いました。
こういうライセンスの部分については、特に気を使って頂かないと大きな問題になるので、もう少し丁寧にすべきでは?と感じるところです。
1. SBAの公開するデータセット
https://data.sba.gov/dataset/7-a-504-foiaには、二つの融資プログラムが存在し、それぞれ公開されていることがわかります。7(a)プログラムと504プログラムが存在します。2024−01−06にChatGPTv4に次の様に質問してみたところ
U.S. Small Business Administrationの7(a) & 504 FOIAとはどの様なものか教えてください。
ChatGPTの回答
アメリカ合衆国の小規模企業庁(Small Business Administration、SBA)の7(a)プログラムと504プログラムは、小規模企業に資金を提供するための2つの主要な融資プログラムです。それらは異なる方法で小規模企業を支援します。
-
7(a)融資プログラム: これはSBAの最も一般的な融資プログラムで、小規模企業に広範な資金調達ニーズを満たすための資金を提供します。このプログラムを通じて、SBAは銀行や他の金融機関によって発行された融資の一部を保証します。これにより、融資機関はよりリスクの高い小規模企業への融資をしやすくなります。7(a)融資は、運転資金、設備購入、不動産購入、事業の買収や拡張など、様々な目的に使用できます。
-
504融資プログラム: このプログラムは、主に不動産や重要な設備の購入や改善のための長期固定資産融資を提供します。504融資は、経済開発と雇用創出を促進することを目的としています。これらの融資は、通常、SBA、金融機関、および借り手の3者間で分担されます。SBAはプロジェクトコストの一部を保証し、低い金利での資金調達を可能にします。
また、FOIAとは「Freedom of Information Act(情報自由法)」の略で、アメリカ合衆国の連邦政府に関する情報の公開を規定する法律です。この法律に基づき、市民は政府機関に情報公開を要求する権利を持ちます。SBAの7(a)や504プログラムに関連する情報も、FOIAの下で公開請求が可能です。これにより、これらのプログラムの運用に関する透明性が確保され、公共の監視が行われます。
生成元データとSBAのデータセットの差異に対する分析と考察
SBAのデータセットにある二つの融資プログラムは、似たデータ構造ですが、細部が異なっています。特に、7(a)融資プログラムではBankNameからBankZipとなっている部分が、504融資プログラムでは、CDC_NameからCDC_Zipとなっています(CDC: Certified Development Company)。504融資プログラムは、ChatGPTの回答にもあるようにSBA、金融機関、および借り手の3者間となっているため、ThirdPartyDollarsというカラムが存在し、7(a)融資プログラムに存在するカラムSBAGuaranteedApprovalがありません。
しかし、Should This Loan be Approved or Denied?には、前述の様な項目がないため、7(a)融資プログラムのみが元になっているのかと思って、BorrNameやGrossApprovalなどの項目を使って紐づけてみたのですが、あまり紐づきませんでした(あまり正規化などを考慮していないのが原因かもしれません。20万件程度)。逆に、504融資プログラムも同様に紐づけを試みるたところ、こちらも数万件が紐づきました。
どうやら、Should This Loan be Approved or Denied?は7(a)融資プログラムと504融資プログラムを混ぜこぜにしている様子です。
リスクプロファイルも異なりそうだし、そもそも融資が三者で構成されている504融資プログラムの情報を適当な形で一つにしているこの生成元データは、あまり信頼ができないなー
ということで、やはりSBAのデータセットであるhttps://data.sba.gov/dataset/7-a-504-foiaを確認していくことがモデル開発の大きなヒントになるのでは?と考えてみました。
2. 7(a)融資プログラムデータの取得と格納
手元で作成していたコードを少し改修して、7(a)融資プログラムデータの取得と格納をDatabricksの環境で行います。もっと簡単に取り込める方法とかあるかもしれませんが、今回はわからず次で取得・格納を行いました。(URIやURLを指定するだけでよきにはからって、Databricks SQL Warehouseとかに格納する機能とかあったりしそうですが、調べる時間ありませんでした)
import os
import sys
import re
import io
import glob
import gzip
import warnings
import pandas as pd
import numpy as np
import requests as req
from IPython.display import display_markdown
warnings.filterwarnings('ignore')
pd.options.display.max_rows = 300
pd.options.display.max_columns = None
dispmd = lambda txt: display_markdown(txt, raw=True)
ROOT_URL = 'https://data.sba.gov/dataset/0ff8e8e9-b967-4f4e-987c-6ac78c575087/resource'
URI_LIST = [
f'{ROOT_URL}/6c270f4e-546c-4717-94b8-c4f4ffb7baa7/download/foia-7afy1991-fy1999-asof-231231.csv',
f'{ROOT_URL}/d108aa1d-8bf8-4746-8dc9-71ad17d592bf/download/foia-7afy2000-fy2009-asof-231231.csv',
f'{ROOT_URL}/40e6d1ef-5853-4bf6-866d-79d91722e2e1/download/foia-7afy2010-fy2019-asof-231231.csv',
f'{ROOT_URL}/3e4231a6-fd69-409f-ac4a-62b7b7592d84/download/foia-7afy2020-present-asof-231231.csv'
]
COL_TYPES = {
'AsOfDate': 'str',
'Program': 'str',
'BorrName': 'str',
'BorrStreet': 'str',
'BorrCity': 'str',
'BorrState': 'str',
'BorrZip': 'str',
'BankName': 'str',
'BankFDICNumber': 'str',
'BankNCUANumber': 'str',
'BankStreet': 'str',
'BankCity': 'str',
'BankState': 'str',
'BankZip': 'str',
'GrossApproval': 'float',
'SBAGuaranteedApproval': 'float',
'ApprovalDate': 'str',
'ApprovalFiscalYear': 'int',
'FirstDisbursementDate': 'str',
'DeliveryMethod': 'str',
'subpgmdesc': 'str',
'InitialInterestRate': 'float',
'TermInMonths': 'int',
'NaicsCode': 'str',
'NaicsDescription': 'str',
'FranchiseCode': 'str',
'FranchiseName': 'str',
'ProjectCounty': 'str',
'ProjectState': 'str',
'SBADistrictOffice': 'str',
'CongressionalDistrict': 'str',
'BusinessType': 'str',
'BusinessAge': 'str',
'LoanStatus': 'str',
'PaidInFullDate': 'str',
'ChargeOffDate': 'str',
'GrossChargeOffAmount': 'float',
'RevolverStatus': 'str',
'JobsSupported': 'str',
'Soldsecmrtind': 'str'
}
df = []
read_opts = {
'encoding': 'latin1',
'dtype': COL_TYPES,
'parse_dates': [
'FirstDisbursementDate', 'ApprovalDate',
'PaidInFullDate', 'ChargeOffDate',
]
}
for uri in URI_LIST:
print(uri)
with req.get(uri, verify=False) as req_get:
file_name = uri.split('/')[-1] + '.gz'
if req_get.status_code != 200:
continue
df.append(pd.read_csv(io.BytesIO(req_get.content), **read_opts))
with gzip.open(file_name, 'wb') as gw:
gw.write(req_get.content)
df = pd.concat(df, axis=0)
dispmd(f'### DataFrame Shape = ROWS: {df.shape[0]:,}, COLUMNS: {df.shape[1]}')
# 過去のデータがないので、AsOfDateは今回はdropする。
df.drop(columns=['AsOfDate'], inplace=True)
# 完済済とそうでないものだけ抽出する
df = df.query('LoanStatus in ("PIF", "CHGOFF")')
dispmd(f'### DataFrame Shape = ROWS: {df.shape[0]:,}, COLUMNS: {df.shape[1]}')
display(df)
取得したデータをsparkを使って、テーブルとして書き込みます。
ここで、'ws_fduacmp_001.[USER_ACCOUNT].7a_PGM_LOAN'の[USER_ACCOUNT]部分は、今回払い出してもらったユーザー名となります。
spark_df = spark.createDataFrame(df)
spark_df.write\
.mode('overwrite')\
.saveAsTable('ws_fduacmp_001.[USER_ACCOUNT].7a_PGM_LOAN')
3. pyspark.sqlを使用してSQLで簡易に分析
前回、Databricksの環境を使って地味に一番便利だなと思ったのは、一つのNotebookのマジックコマンドがよくできていて、Python/R/SQLを切り替えて使え、さらにGUIで簡易にダッシュボードをプチプチっと作成できる(もっとすごい機能がいっぱいなのは重々承知しているのですが)点でした。
この点で色々とSQLクエリーを書きながら、アイデアを出せたらいいなと。日々の業務では、数百行にわたる謎のSQLを書いているため、どうしてもデータの処理・分析の思考法がSQLになってしまいます。このため、この様にSQLとPythonを同時に記述して、同じ様に可視化できるのは非常にありがたいです。
ただ、pyspark.sqlではRDBMSのSQLで実装されSTORED PROCEDUREなどで動作するWHILEなどはないため、プログラムとクエリーを組み合わせて複雑な処理を構築する必要があるので、その点についてはちょっと痒いところに手が届きにくい(本来、SQLであまりプログラマブルなことをするなのですが)なと感じました。
まずは、どの程度完済PIF(Pay In Full)と債務不履行(CHGOFF: Charge OFF)が存在するか確認してみます。
SELECT
LoanStatus,
COUNT(*) AS TOTAL_COUNT
FROM
ws_fduacmp_001.[USER_ACCOUNT].7a_PGM_LOAN
GROUP BY
LoanStatus
;
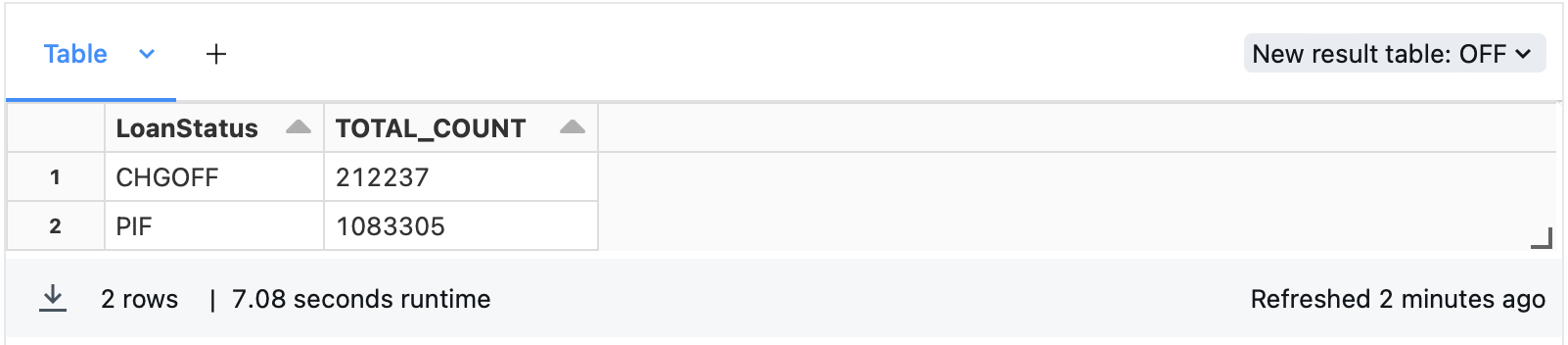
うーん、結構CHGOFFの件数ありますね。
次にNaicsCodeの先頭2文字を取って、NAICSセクター別にPIF/CHGOFFの分布を確認してみます。Visualizationを使って積み上げ棒で描画してみました。
3.1 Naics Sector別のデフォルト確認
SELECT
substring(NaicsCode, 1, 2) AS NAICS_Sector,
COUNT(*) AS TOTAL_COUNT,
SUM(iff(LoanStatus = 'PIF', 1, 0)) AS PIF_COUNT,
SUM(iff(LoanStatus = 'CHGOFF', 1, 0)) AS CHGOFF_COUNT
FROM
ws_fduacmp_001.[USER_ACCOUNT].7a_PGM_LOAN
GROUP BY
substring(NaicsCode, 1, 2)
ORDER BY
NAICS_Sector
;
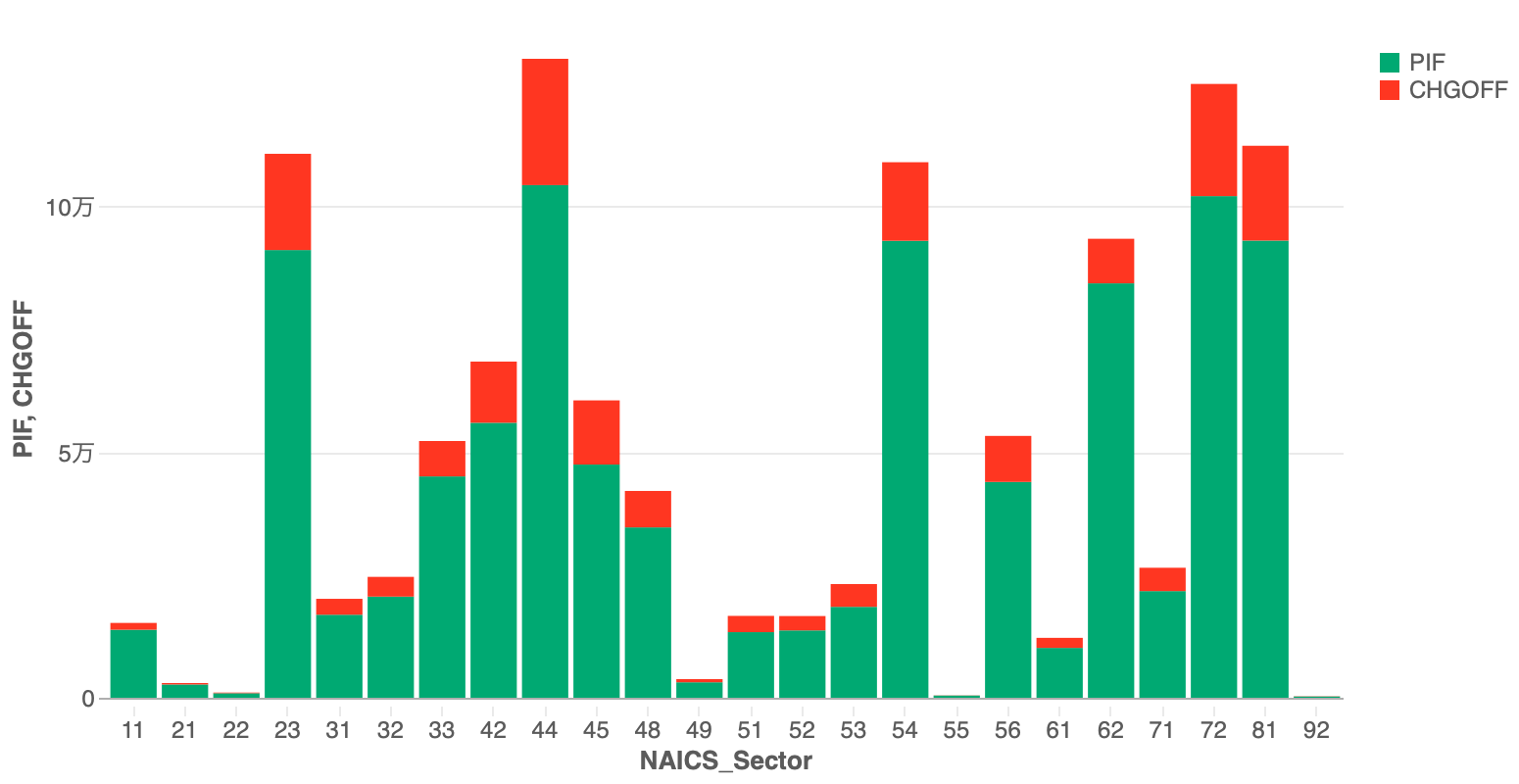
これを使って、ターゲットにエンコーディングができるかもしれません。これを数年刻みでマトリクスを作成し、出題のtrainデータと結合してみました。
結果は精度が下がりました。
うーん
3.2 Cityの正規化検討
今回のtrainデータのCityを参照すると、Saint LouisがSAINT LOUISやSt. Louisだったりと表記にばらつきがありました。このため、元データのBorrCityと比較しました。
SELECT
BorrName,
BorrStreet,
upper(BorrCity) AS BorrCity,
BorrState,
BorrZip
FROM
ws_fduacmp_001.[USER_ACCOUNT].7a_PGM_LOAN
WHERE
upper(BorrCity) LIKE 'LOS ANG%'
;
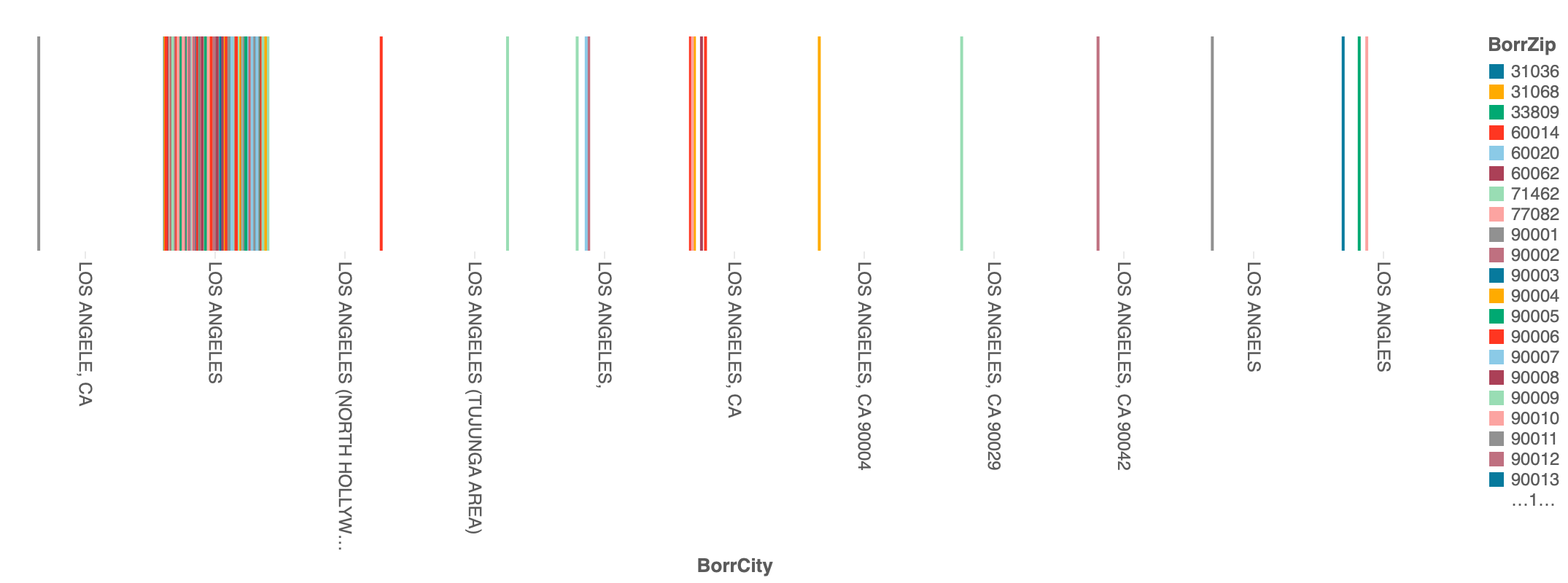
生成AIであるAssistantにどの様にすれば、この様な問題を解決できるか質問してみました。
BorrCityのデータを見ると地区名や表記の誤りがあります。これを正規化する方法を教えてください
すると次の様に回答してくれました。
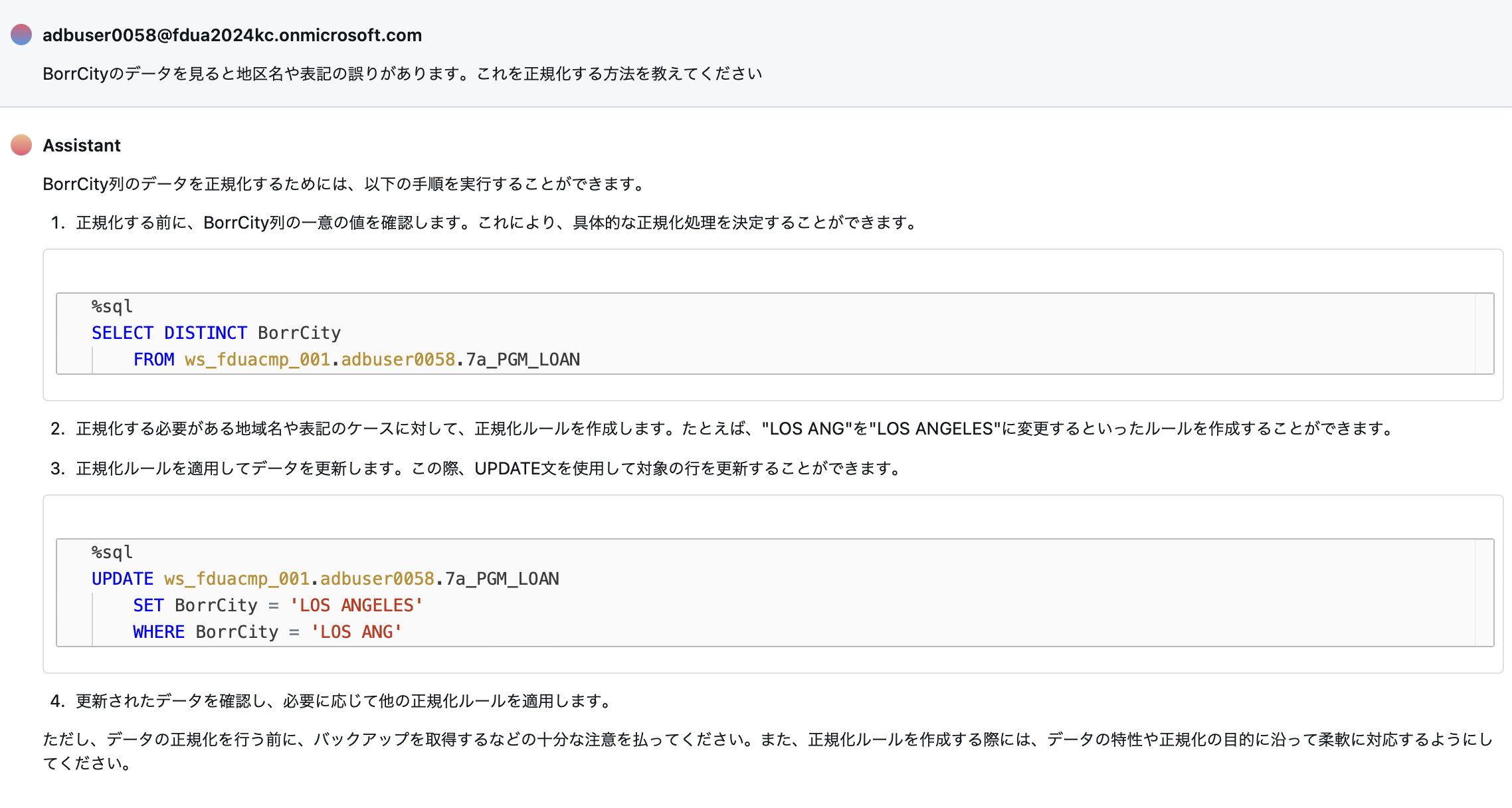
コンテキストを判断して、現在のSQLでどの様に正規化すれば良いか答えてくれています。upper(BorrCity) LIKE 'LOS ANG%'の部分を渡して、次の部分が返ってくるところ本当に生成AIだなと感じました。
UPDATE ws_fduacmp_001.adbuser0058.7a_PGM_LOAN
SET BorrCity = 'LOS ANGELES'
WHERE BorrCity = 'LOS ANG'
しかしながら、単純なUPDATE節ですし、この程度のことなら聞かなくても知っているので、助けにはなりませんでした。そこで、次の様にBorrZip(債務者のZIPコードがNew York市となっているもの)クエリーを実行して、コンテキストを読み取ってくれることを期待しました。
SELECT
BorrName,
BorrStreet,
upper(BorrCity) AS BorrCity,
BorrState,
BorrZip
FROM
ws_fduacmp_001.adbuser0058.7a_PGM_LOAN
WHERE
/* New York Cityのzip code */
BorrZip BETWEEN '10001' AND '10048'
;
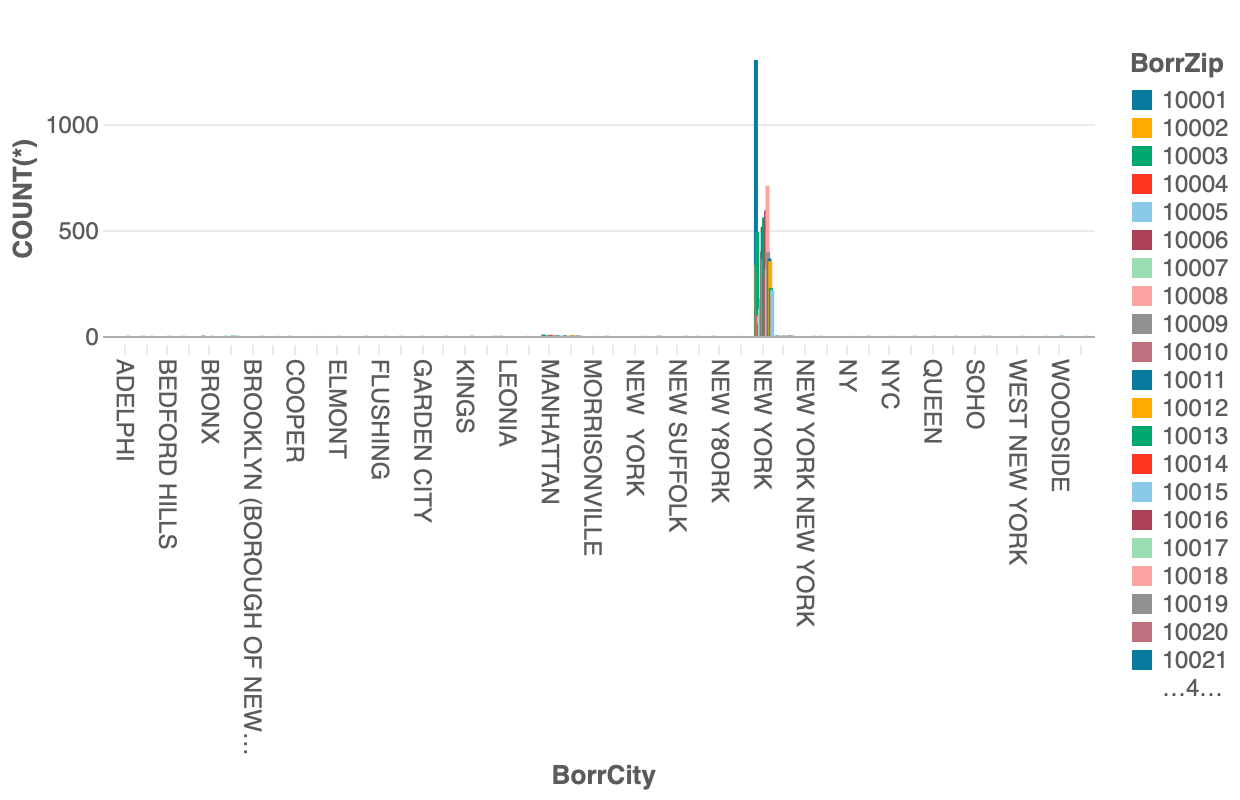
New Yorkを構成する5のBoroughsであるBRONX, QUEEN, BROOKLYN, MANHATTANなどの他にも様々な地名が存在することがわかります。さらに、入力しようとして、8も一緒に入ってしまったのでしょうか、NEW Y8ORKというのもある様子です。New York以外の大都市でも同じ様な状況が見られ、CityにはCountyやTownの粒度で情報があったりと、これをそのまま使うのは相当に難儀しそうです。また、今回の出題データのtrainでも同様の状況が見られましたので、やはりこれらの情報がそのまま現れている様子です。
そこで、改めてAssistantさんに次の様な質問をしてみます。
次の様にNew York CityのZip Codeと思われる10001から10048を確認すると先ほど教えていただいた正規化の手法では対応できなさそうです。外部データや機械学習を使って誤り訂正や正規化する方法を教えてください。
すると次の様な回答がありました。
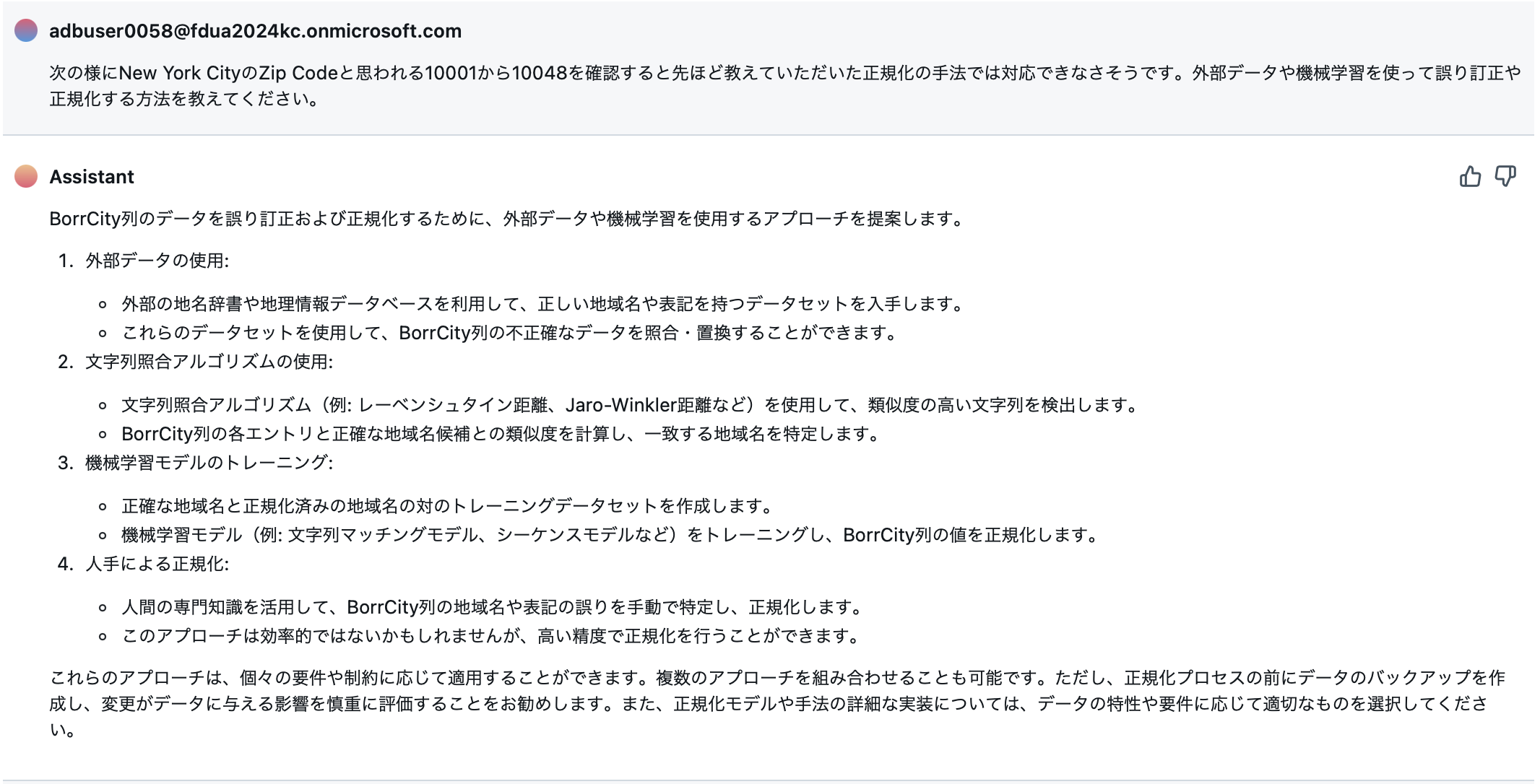
この後で、2についてのプログラムを紹介してもらったのですが、簡単には適用できなさそうでした。このため今回は1と4を組み合わせて、ZIP CodeからCityを正規化する作戦をとることにしました。オープンなZip Codeの対応表を入手し、BorrCity -> BorrZip -> 正規化されたCityを作成して、BorrCityと正規化されたCityの対応表を作成することができる。
これを出題データのCityカラムにその対応表を適用すれば、表記揺れが解消できるのではないか?この手法の正規化処理を行って、Cityをカテゴリカル変数として処理して学習を行いました。
結果は精度が下がりました。
おそらく、表記が揺れた個別のCity名に対して、デフォルト率に紐づいているのではないでしょうか。これによって得られたデータで緯度・経度を追加することとしました。
3.3 Maturity Dateの算出と年の相関
出題データにも本データにも融資実行日と融資期間が存在すため、FirstDisbursementDateとTermInMonthsについて確認してみたいと思います。
FirstDisbursementDateにTermInMonths月数分だけ足せば、おそらくMaturityDateになるはずです。
せっかくなので、早速Assistantさんに尋ねてみます。
FirstDisbursementDateからTermInMonths数の月数後のMaturityDateを算出したいのですが、SQLクエリーだとどの様に記述すればよいですか?
次の様な回答がありました。
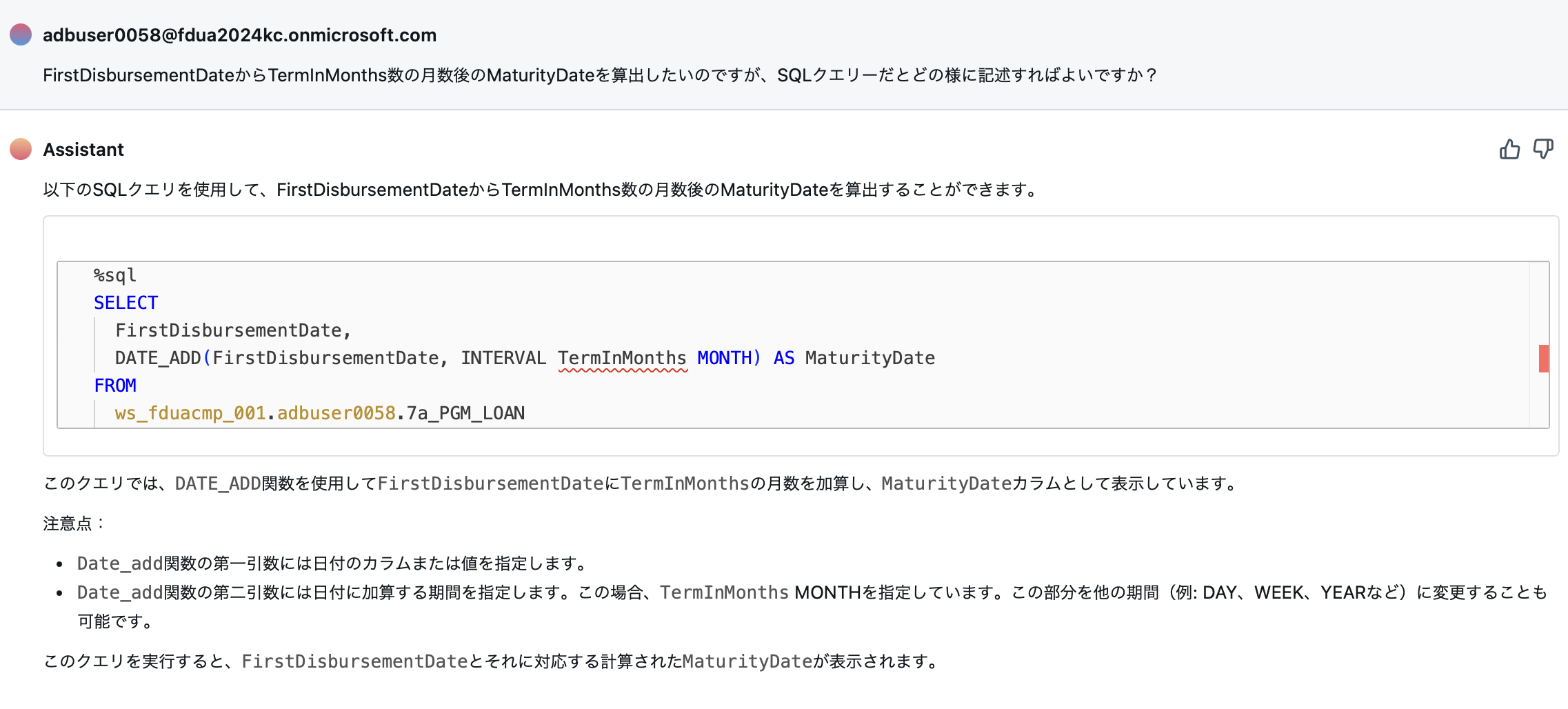
うーん。これだと動作しません。そもそもコードのシンタックスハイライターが赤くなってんじゃん。date_add functionを参照して、次の様なクエリーを作成してみました。
Years別に集約していない状態で結果の出力を行い、チャートを描画する際にYearsで集約してみたいと思います。件数が少ないとぶれるため、HAVING COUNT(*) >= 10をつけてみます。
%sql
SELECT
FirstDisbursementDate,
CASE
WHEN ChargeOffDate IS NOT NULL THEN
ChargeOffDate
ELSE
DATE_ADD(MONTH, TermInMonths, FirstDisbursementDate)
END AS MaturityDate,
-- DATE_ADD(MONTH, TermInMonths, FirstDisbursementDate) AS MaturityDate,
COUNT(*) AS TOTAL_COUNT,
SUM(CASE WHEN LoanStatus = 'PIF' THEN 1 ELSE 0 END) AS PIF_COUNT,
SUM(CASE WHEN LoanStatus = 'CHGOFF' THEN 1 ELSE 0 END) AS CHGOFF_COUNT,
SUM(CASE WHEN LoanStatus = 'CHGOFF' THEN 1 ELSE 0 END) / COUNT(*) AS CHGOFF_RATIO
FROM
ws_fduacmp_001.adbuser0058.7a_PGM_LOAN
GROUP BY
FirstDisbursementDate,
CASE
WHEN ChargeOffDate IS NOT NULL THEN
ChargeOffDate
ELSE
DATE_ADD(MONTH, TermInMonths, FirstDisbursementDate)
END
HAVING
COUNT(*) >= 10
ORDER BY
TOTAL_COUNT DESC
;
この結果をヒートマップにして内容をみてみます。
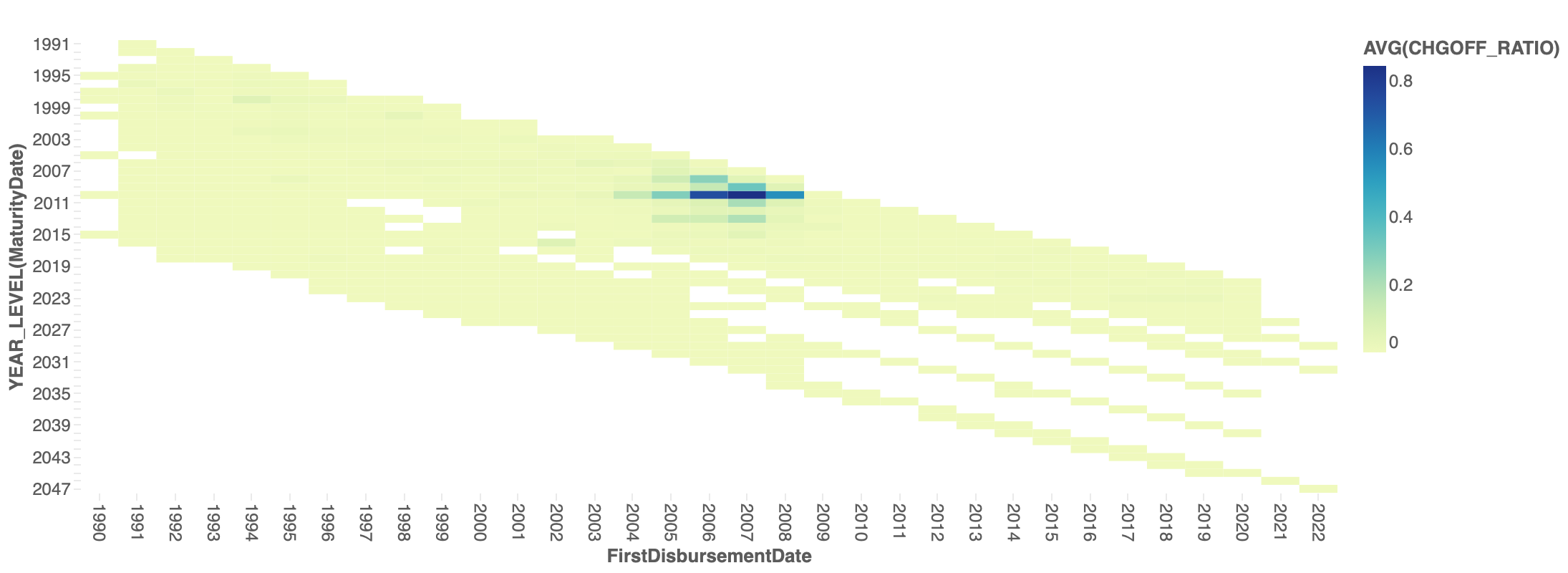
やはり、2007年から2008年に起きた金融危機の前後に高いCHGOFF率を記録しています。融資期間が長いものはそもそも件数が少ないですが、CHGOFF率はそこまで高くない様子です。
同様ものを出題データのtrainに対しても同じことをしてみますが...
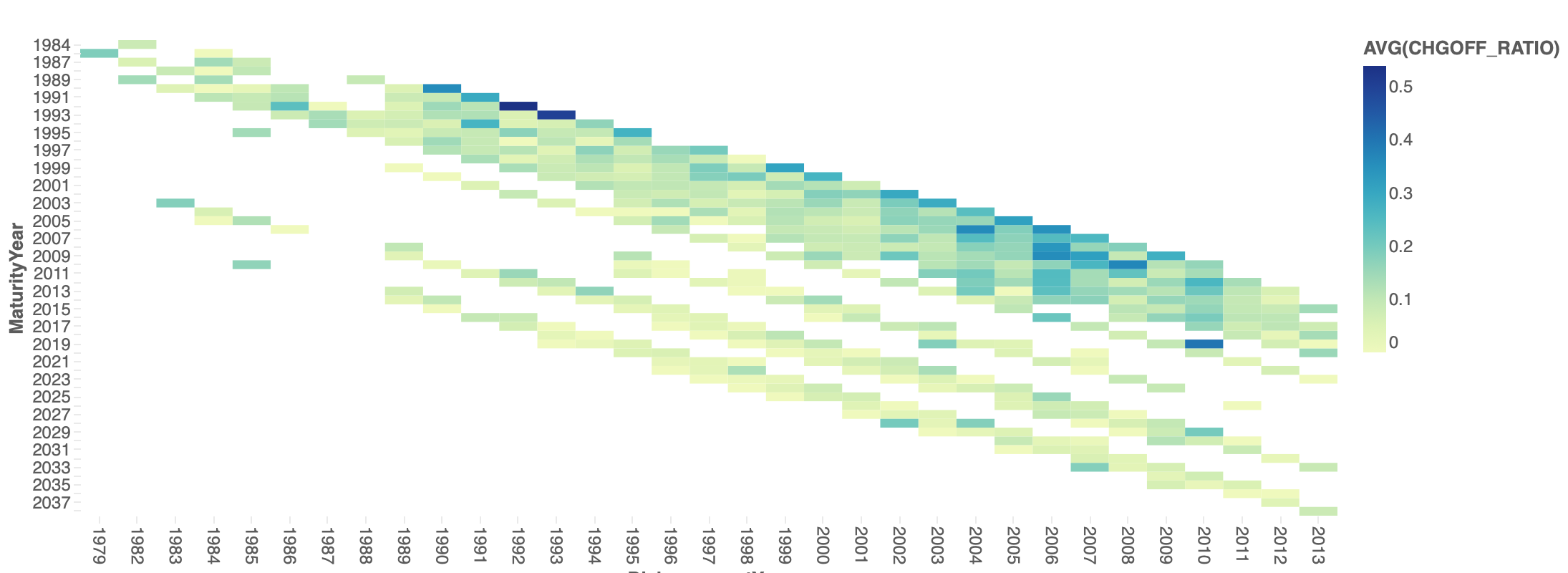
あまり相関がなさそうな気がする...
4. 最後に
尻切れ蜻蛉で誠に申し訳ございませんが、コンペがまもなく終了ということもあり、ここでの話は終了となります。
Databricksでモデル構築まで進めたかったのですが、ここまでのことをしていたら、2024−02−13となってしまい、Databricksでの機械学習モデルの構築まで辿りつけませんでした。しかし、Assistantの力を借りながら効率的にEDAができる点は大変便利であることを実感できました。もし第3回でもこの様な環境が利用できれば、次こそはもっと実践的なことをやってみたいなと思いました。(職場でも使えたらいいのですが...)
運営に携わっている皆様、素敵な環境が利用できたこと大変感激いたしました。誠にありがとうございます。