概要
今回はモデル学習の一通りの流れを実施します。
メモ的なものとしてみていただければと思います。
モデル学習の準備
インポート
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
from sklearn.linear_model import LinearRegression as LR
データの分割
scikit-learnライブラリのtrain_test_split関数
X_train, X_test, y_train, y_test = train_test_split(説明変数、目的変数, random_state=num, test_size=sizeNum)
random_state:毎回同じように分割(過学習を防止)
test_size:分割割合を指定(0.2の場合、全データのうち、80%を学習用データ、20%を評価用データ)
学習データ75%、評価データ25%となるように分割
評価関数の定義
RMSE(Root Mean Squared Error)
MSEは予測誤差の絶対値をとるが、RMSEでは予測誤差を2乗する。そのため、MSEよりも解釈が難しいが、大きな予測誤差を出さないモデル傾向となる
1.numpyのみライブラリでの実装
# データの生成
actual = np.array([4,6,8]) # 実績値
pred = np.array([2,8,10]) # 予測値
# numpyのarray型同士を引き算すると各要素ごとに引き算が実行
a = actual - pred
print(a) # [ 2 -2 -2]
# 累乗はnp.power関数を使用。引数にはn乗のnの値
b = np.power(a, 2)
print(b) # [ 8 -8 -8]
# 要素同士の足し算にはnp.sum関数を使用
c = np.sum(b)
print(c) # -8
# cの値をデータのサイズで割り算
d = c / 3
print('d',d) # -4.0
# np.sqrt関数で平方根を取る
e = np.sqrt(d)
# 計算結果の表示
print(e) # 2.0
↓ 1行で記述すると
RMSE = np.sqrt(np.mean(np.power(actual-pred,2)))
- scikit-learnライブラリでの実装
scikit-learnにはRMSEが未実装のため、RMSEの平方根を取る前の値であるMSE(Mean Squared Error)を利用し、RMSEを算出
np.sqrt(MSE(実績値, 予測値))
モデルの学習
線形回帰モデル
- 単回帰モデル:y = ax + b、aが傾き、bが切片
- 重回帰モデル:y = a1x1 + a2x2 + … + b、 aが各説明変数の係数、bは切片
重回帰モデルの作成
scikit-learnライブラリのLinearRegressionで重回帰モデルの作成が可能
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X(説明変数), y(被説明変数), random_state=32)
# モデルの生成
lr = LR()
# モデルの学習
lr.fit(X_train, y_train)
モデルの精度評価
予測値の取得
skleanライブラリのpredictで予測値を取得可能
y_pred_train = lr.predict(X_train)
↓ 結果の例
# numpyの配列を表すndarray型で返ってくる
[25.22182295 22.71044791 33.42986757 23.12417403 21.86445237 20.96844498
27.32922 25.61715159 15.64848023 18.74273426 26.67452757 25.33549792]
RMSE
学習データのRMSE
# MSEの算出
mse = MSE(y_train(実績値), y_pred_train(予測値))
# RMSEの算出
rmse_train = np.sqrt(mse)
↓
7.777777777777777
汎用化性能の検証
評価データへの予測値
# X_testに対する予測値を算出
y_pred_test = lr.predict(X_test)
過学習の検証
過学習が発生している場合、学習データへの予測精度は高いが、評価データへの予測精度が著しく低い
<正常>
学習データのRMSE = 0.64
評価データのRMSE = 0.55
<過学習>
学習データのRMSE = 0.00
評価データのRMSE = 0.91
*RMSEは値が小さいほど誤差が小さい
評価データのRSME
# MSEの算出
mse_test = MSE(y_test, y_pred_test)
# RMSEの算出
rmse_test = np.sqrt(mse_test)
予測精度の可視化
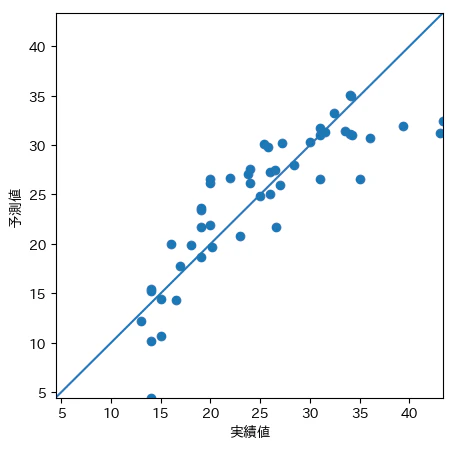
具体的な予測値の傾向として、予測値が小さい時に外しやすいのか、大きい時に外しやすいのかを把握することができれば、予測モデルを改良するアプローチを検討するためのヒントとなる。その可視化方法として、縦軸を予測値、横軸を実測値とした散布図を利用。
手順
- グラフのサイズを指定して、グラフの大きさを正方形になるように設定
- 横軸を実測値、縦軸を予測値として、散布図を描画
- y_test、y_pred_testの両方を見た上での最小値と最大値を算出
- 最小値と最大値を使い、x軸およびy軸の値域を指定し、揃える
- 対角線を描画
正方形の散布図
matplotlibライブラリのplt.figure関数でグラフのサイズを指定、plt.scatter関数で散布図を描画
# サイズ指定
plt.figure(figsize=(横幅, 縦幅))
# 散布図
plt.scatter(y_test(X軸), y_pred_test(Y軸))
# 可視化
plt.show()
最大値と最小値
numpyのnp.max関数とnp.min関数、np.maximum関数とnp.minimum関数で算出可能
# y_testの最小値・最大値を算出
test_min = np.min(y_test)
test_max = np.max(y_test)
# y_pred_testの最小値・最大値を算出
pred_min = np.min(y_pred_test)
pred_max = np.max(y_pred_test)
# 値を比較し、最終的な最小値・最大値を算出
min_value = np.minimum(test_min, pred_min)
max_value = np.maximum(test_max, pred_max)
最大値と最小値を適用
matplotlibライブラリのplt.xlim関数でx軸、plt.ylim関数でy軸の指定
# 今回は正方形を作成するので、xlimとylimの値は同じ
# plt.xlim([xmin, xmax])
plt.xlim([min_value, max_value])
# plt.ylim([ymin, ymax])
plt.ylim([min_value, max_value])
対角線の描画
matplotlibライブラリのplt.plot関数
# plt.plot([x1,x2],[y1,y2])
plt.plot([min_value, max_value],[min_value, max_value])
最終的なイメージ
下記のようなグラフから実績値が小さいもの時に比べて、実績値が大きい時に予測誤差が大きい傾向があることがわかり、予測モデルの改善に繋げることが可能
予測精度の改善
ダミー変数
- 質的データを量的データに変換
Pandasのpd.get_dummies関数でダミー変数を生成可能
sample = pd.DataFrame({'index':[0,1,2],'果物':['みかん','いちご','メロン'],'個数':[100,200,300]})
dummy = pd.get_dummies(sample)
↓ One-Hot表現:1カラムだけを「1」としてデータを表す方法
# 自動的に質的データのみをダミー変数化
index 個数 果物_いちご 果物_みかん 果物_メロン
0 0 100 0 1 0
1 1 200 1 0 0
2 2 300 0 0 1
RSMEを再度算出して、再検証可能となる
対数化
- ある値を対数変換
- 指数関数に線形回帰モデルが当てはめることができないため、指数関数を対数化し、直線にする
numpyライブラリのlog関数で対数化
# DataFrameにはないカラム名を指定して値を代入した場合、新しいカラムとしてDataFrameに追加
DataFrame['新たなカラム名'] = np.log(DataFrame['対数化するカラム名'])
RSMEを再度算出して、再検証可能となる
コードのまとめ
# ライブラリのimport
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression as LR
from sklearn.metrics import mean_squared_error as MSE
# データの読み込み
data = pd.read_csv('data.tsv', sep='\t')
# idの削除
data = data.drop(columns=['id'])
# 欠損値を含む行の削除
data = data.dropna()
# 対数化
data['new_column']= np.log(data['column'])
# 目的変数及び説明変数を表す変数の準備
y = data['obj_column'] # 目的変数
X = data[['sbj_column1','sbj_column2']] # 説明変数
X = pd.get_dummies(X) # 各説明変数のダミー変数化
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 1)
# モデルの箱の準備および学習
lr = LR()
lr.fit(X_train, y_train)
# 予測値の算出
y_pred_train = lr.predict(X_train)
y_pred_test = lr.predict(X_test)
# MSEの算出
mse_train = MSE(y_train, y_pred_train)
mse_test = MSE(y_test, y_pred_test)
# RMSEの算出
rmse_train = np.sqrt(mse_train)
rmse_test = np.sqrt(mse_test)
最後に
今回は予測モデルの基本的な作成手順・方法についてのメモとして書きました。
こちらでは、実際のデータを用いて予測モデルを作成し、SIGNATEに提出するところまで行っていますので、合わせてご覧いただけると良いかと思います。
- Miyata Koki - O:inc.でAmplify×React×React Nativeを使用して開発しています。大学のゼミでは統計学をPythonで行っています。 インターンやゼミで学んだ情報を発信していくので、フォロバもしますのでぜひこちらのアカウントのフォローお願いします!