「文豪みたいな人の名言みたいなもの」を生成するプログラムを開発しました。
サンプルや文章の一部は以前デモサイトをvercelではなくnetlifyにデプロイしていた際の内容になっています。
開発結果
こちらが成果確認用のデモサイト「エセ文豪 エセ名言集」です
デモサイトのサンプル
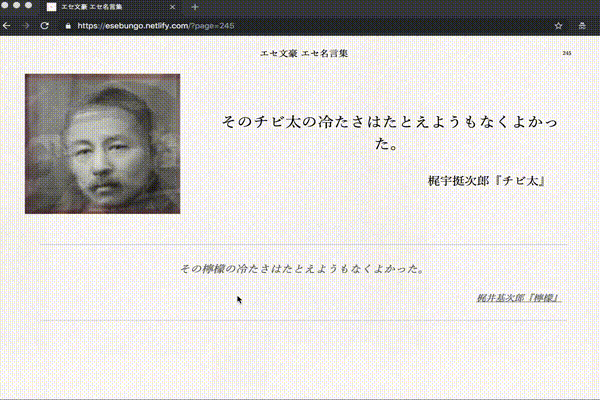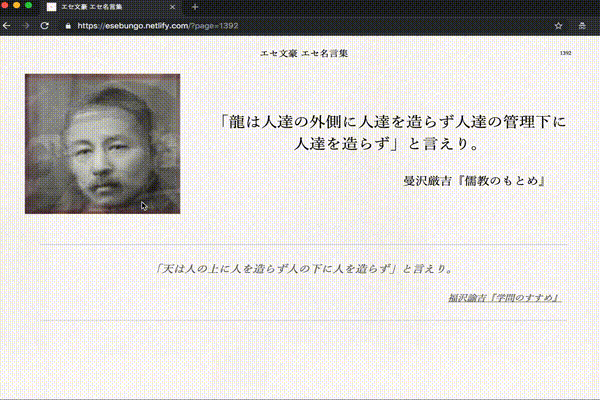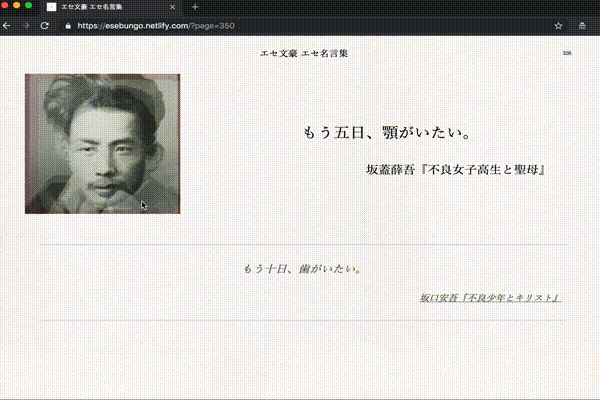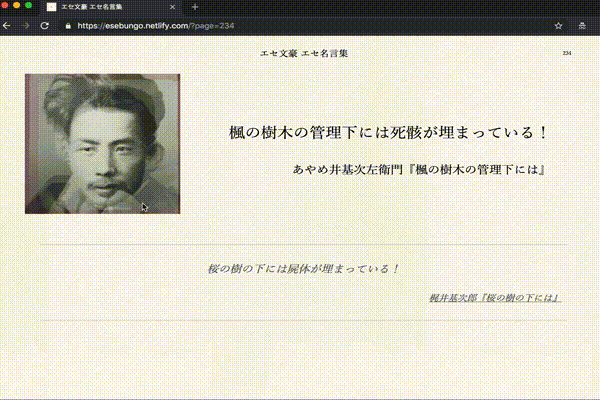



こんな感じの文章を生成するプログラムを作りました。画像の生成は別です。
(デモサイトのデータは入れ替わる可能性ありなので、同じページ番号でも別の内容になる可能性があります。)
Twitterでも、同じプログラムを利用して1時間に1度名言のようなものをつぶやいています。 (運用停止中)
この記事の内容
「文豪みたいな人の名言みたいなもの」生成プログラム開発の技術的な詳細や、それによって何を狙ったのかをまとめておこうと思います。主につまづいたところや、判断に迷ったところ、変更(チューニング)の余地のある点について書きます。
Word2Vecを使用していますが、自分は東北大学 乾・岡崎研究室の学習済みモデルを使わせてもらっただけです。なので、以下の詳細には「機械学習」に関する独自の試行錯誤は一切でてきません。
また、MeCabで形態素分析を行なっていますが、ちゃんとOchasenのアウトプットのパターンを理解せずに使った部分が多々あるので、非効率もしくは不正確な事をしているかもしれません。発見しましたらご指摘いただけるとありがたいです。
ソース(python3系)はこちらです。
背景
2週間ほど前にinaniaw3さんの作品群(偶然短歌や小説時計、その他ツイッターでの投稿)を知り、それに感化され、自分もエンジニアリングを使って何か面白いものを作りたいという欲に駆られました。
開発期間は1週間ほど(平日の仕事終わりの時間から寝るまで+週末)です。
試したかったアイデアと開発の目的
「全然知らない人がいかにも名言っぽいことを言ってたら面白いのでは?」と思い、そのアイデアを実証することにしました。
なので、
1. 名言っぽい事を生成させる
2. 結果が面白い
の2つの達成を目的としました。
あと開発の外側の目的として、諦めず完成させて、人に見せて、技術ブログも書く、とこまでやろうと思っていました。
達成度を測る基準が主観しかないのが残念ですが、個人的には及第点かと思っています。現在記事は非公開化済みですが、noteでも紹介して、暖かいフィードバックを数名からもらえました。ただ、開発終えてこの記事を書きながら試し損ねたパターンに気づいたりもしていて、まだまだ全然やれることあるなぁという思いです。
プログラムで面白いことを狙うのは、滑ったらプログラムのせいにできるので、気が楽です。実際、全部プログラムのせいです。
目的をどうやって実現するか(手段)
今回とった手段は「元となる文章をインプットとし、その中の名詞を別の類似の名詞に置き換えたものをアウトプットとする」です。
他の方法、例えば「機械学習で名言の傾向を学ばせて生成させる」の方が今の時代的にもあっていて、課題としてチャレンジングとは思うのですが、
- 自分のスキル・経験的に、たとえ長い時間をかけても完成するか不明
- そもそも「面白い」ものになるのか結果が全く読めない
という理由からそのような方向は選びませんでした。
「元となる文章の置き換え」であれば
- 実装が比較的容易
- 「元の文章のパロディを作成する」というわかりやすいユーモアになりそう
という点で今回の目的により合致していました。
これまで、なんども作りかけのアプリに飽きて捨てるを繰り返してきたので、簡単ですぐ完成しそうという点は重要なポイントでした。
また、「名詞部分」だけ置き換えるとしたのは、元の文章の名フレーズとしてのキレのよさや「名言っぽさ」の維持を行うためです。パロディとしての精度を上げるため、と言い換えても良いかもしれません。
作ったものは「パロディの面白さを再現するためのプログラム」とも言えます。なので「これはパロディとして成立してるのか」という「パロディ感」を自問自答しながらの実装になりました。
変換元データ: 青空文庫
元データは青空文庫から選びました。
作品は機械的に選んだのではなく、有名作品の有名フレーズを基準に人力で選んでいます。元ネタが広く知られている方が、パロディとして面白みが増すと考えたためです。
ただ例外として、別に有名でなくとも適当に選んで結果が面白かったもの(主観)も含まれています。
このデータ選択基準のデメリットは、データの追加がめちゃくちゃめんどくさいことです。もしちゃんとWebサービスとして運用するならこんな方法は取らなかったと思います。運用を考えないワンショットの準備という前提で、質(主観)をあげるためにこの方法を選択しました。
選んだものがこちらです。現時点(2019/1/21 日本20時半ごろ)で13著者、26作品、38の文章があります。
実装について
以下実装について、概略と、実装時につまづいた点(そして今もあまり自信がない点)の詳細を書きます。
どうやって元の文章から別の文章を生成するか
やっていることは単純なのですが、以下のことを行なっています。
1. もとの文章から名詞を抜き出す(形態素分析にMeCabを使用)
2. その名詞に類似した単語たちをWord2Vecで取得し、その中で名詞のみを置き換え候補として残す
3. 文章中の全名詞を置き換え候補で置換する。どの置き換え候補が使われるかはランダムだが、一回の出力において、一度置き換えた名詞は同じ名詞で置き換える。
上のような処理を行うことで
変換前:「天は人の上に人を造らず」
を
変換後:「龍は人びとの外側に人びとを造らず」
という風に変換しています。
1-2をsimilar_word_finder.pyにて行ない、
3をese_bungo_generator.pyで行なっています。
その他共通の処理をutil.pyに、定数をconst.pyに入れています。
(その他のファイル、tweet_generator.py、app.pyはtwitter bot用です)
対象となる名詞をどうやって判定するか
使用したMeCabの辞書
MeCabデフォルトのシステム辞書を使用しています。固有名詞に強いmecab-ipadic-NEologdは使用していません。
デフォルトを使ったのは、たとえば「我輩は猫である」のような有名な作品名を1つの固有名詞として扱うことを避けるためです。固有名詞ではなく、「吾輩」「は」「猫」「で」「ある」と分割して、「吾輩」と「猫」を置き換えの対象にする必要がありました。
mecab-ipadic-NEologdは固有名詞に強いために、「吾輩は猫である。名前はまだない。」という文章の最初の「我輩は...」も作品名(固有名詞)と判断してしまうため、今回の用途にはあいませんでした。
辞書にない単語は置き換えをスキップしています。
名詞判定1:単語自身の品詞の判定
MeCabで分割した単語の品詞(part)を以下のように判定しています。
def is_target_noun(part):
# 全ての名詞を対象にはしない。
# 接頭詞-名詞接続 「老夫婦」の「老」(これは続く単語がすべて名詞なら対象にしてもいいが、現在はそのチェックなし)
# 名詞-接尾-一般 「反逆罪」の「罪」
# 名詞-接尾-形容動詞語幹 「がち」
# 名詞-代名詞-一般 「これ」
# 名詞-副詞可能「正午」「ここ」など
# などは単体で役割の違うものに変換すると文がくずれる可能性が高いので対象外
# '名詞-サ変接続'「翻訳する」の「翻訳」など
# '名詞-非自立-副詞可能'「人の上」のように「の」あとの「上」など
# '名詞-形容動詞語幹' 「不滅 」「幸福」など
return '名詞-一般' in part \
or '名詞-固有' in part \
or '名詞-数' in part \
or '名詞-サ変接続' in part \
or '名詞-非自立-副詞可能' in part \
or '名詞-形容動詞語幹' in part
==ではなくin で判定しているのは '名詞-固有名詞-地域-国' のような品詞も対象に含むためです。
'名詞-固有名詞-地域-国'の例:「アメリカ」をMeCab+Ochasenでparseした結果
>>> tagger.parse('アメリカ')
'アメリカ\tアメリカ\tアメリカ\t名詞-固有名詞-地域-国\t\t\nEOS\n'
==だと上のような結果が拾えません。
ただもしかしたら、固有名詞以外は、単純に == でいけるかもしれません。
全体的に、Ochasenの結果のパターンを深く理解してないので、無駄なことをしている可能性ありです。
('名詞-非自立-副詞可能', ' '名詞-形容動詞語幹''のパターンについては、デモサイトリリース後、この記事書いてる時に漏れに気づきました。まだ漏れがある可能性ありです)
名詞判定2:類似語候補の名詞判定
類似語候補はWord2Vecのmost_similar関数で取得しています。
置き換え対象の方は上述のis_target_nounの判定で問題なさそうだったのですが、Word2Vecがmost_similar関数で返す類似語の方は「一語単体」とは限らないので、複数単語が帰ってきた場合用のチェックが必要でした。
例えば「人」であれば類似度top7はこんな感じです。
[('人たち', 0.6503018140792847),
('人が', 0.6207061409950256),
('人達', 0.609580934047699),
('万人', 0.5998476147651672),
('人々', 0.5922404527664185),
('人びと', 0.5528509020805359),
('[日本人]', 0.551566481590271)]
このうち「人が」のように「名詞+格助詞」のパターンは、置き換え後の文章を崩してしまうため除外の必要がありました。
このあたり実装汚いですが、こんな感じです。
# 候補の単語の次の単語(post_similar_word)判定
# 名詞+助詞、という類義語のパターンは文章が崩れるのでスキップ
# ("人" => "人が" や、"桜" => "桜の" など)
#「基本的」のような「的」というパターンも名詞ではないのでスキップ
post_similar_word_detail = similar_word_details[1]
if has_part_length(post_similar_word_detail):
post_part = post_similar_word_detail.split('\t')[3]
if '助詞' in post_part:
continue
# 「-的」を対象外に
if '名詞-接尾-形容動詞語幹' in post_part:
continue
置き換え処理のループ
ここで結構バグって苦労したのですが最終的に以下のようにしました。効率が悪い方法だと思うので、もしもっといい方法があれば是非知りたいです。
0. (置き換え準備)置き換え対象名詞をKeyに、類似名詞のリストをつくっておく。
1. 置き換え対象の文章をMeCabでParseして分割、置き換え対象の名詞リストを作成する。
2. 置き換え対象の名詞リストの名詞をlengthが「長いもの」順にソート
3. ソートしたリストをループして、いったん一意のプレースホルダーに置換していく。一意のプレースホルダーと置き換え対象の名詞の関係はdictionaryにもっておく。
4. 一意のプレースホルダーに置換おわったテキストを、プレースホルダーから、類似名詞(ランダムで1っこ選ぶ)に置き換える
これらはese_bungo_generator.pyのreplace_noun_by_similar_word関数で行なっています。
長さ順のソートが必要な理由
上記2.のソートを行なっているのは、名詞を部分的に置き換えてしまわないためです。
たとえば「怪人二十面相」の本文
ふたり以上の人が顔をあわせさえすれば、まるでお天気のあいさつでもするように、怪人二十面相のうわさをしていました。
には「人」と「怪人」が含まれます。(「怪人二十面相」は固有名詞ではなく、「怪人」「二」「十」「面相」に分割されます。)
ここで「人」の方を先に置換してしまうと、「怪人」の一部分も置き換えされてしまい、例えば"「人」=>「日本人」"という変換なら「怪日本人」という置き換えがされてしまい、「怪人」の置き換えが正しくされません。
この問題を防ぐために、単語の長さ順(降順)にソートして、長いものから置き換えをしています。
置き換え対象の単語のインデックスを保持する方法もあるかな、と思ったのですが、より複雑になるだけで今の所メリットがなさそうなので、ソートにしました。
プレースホルダーへの一時置換が必要な理由
これは置き換え後の単語を再度置き換えてしまわないためです。
たとえば、「天は人の上に人を造らず」では、「天」の類似語に「天人」があります。なので、直接置き換えてしまうと
「天」の置き換え => 「天人は人の上に人を造らず」
「人」の置き換え => 「天日本人は日本人の上に日本人を造らず」
という再置き換えが発生してしまう可能性があります。
これを防ぐために最初は一意のプレースホルダーに置き換え、全てをプレースホルダーに置き換えした後に、プレースホルダーを類似語に置き換える、という2回のループを回しています。
上の例はプレースホルダーを使うことで以下のような2つのステップになります(プレースホルダーはイメージです)
プレースホルダーへの置き換えループ
「天」の置き換え => 「PLACEHOLDER_aaaaは人の上に人を造らず」
#同時に {'天' => 'PLACEHOLDER_aaaa'} 作成
「人」の置き換え => 「PLACEHOLDER_aaaaはPLACEHOLDER_bbbbの上にPLACEHOLDER_bbbbを造らず」
#同時に {'天' => 'PLACEHOLDER_aaaa', '人' => 'PLACEHOLDER_bbbb'} 作成
プレースホルダーへの置き換え終了後、プレースホルダーから類似語への置き換えループ
「PLACEHOLDER_aaaa」の置き換え => 「天人はPLACEHOLDER_bbbbの上にPLACEHOLDER_bbbbを造らず」
「PLACEHOLDER_bbbb」の置き換え => 「天人は人の上に人を造らず」
作者名はどうやって生成するか(名前のパロディとは?)
ここは技術的にどうこうというより、「名前のパロディをつくるにはどうするか」、という悩みがありました。
最終的に
1. 名前を漢字一字に分割し、その漢字ごとに類似の名詞群を取得(方法は上述の文章と同じ)
2. 名前の過半数(最低50%)を類似語で置換(置き換える文字数は名前の長さに依存。対象の文字はランダム)
3. 置き換え後の文字や長さは特に制限しない。カタカナも数字もOK。1文字じゃなくてもOK。
としました。
結果
坂口安吾 => 野道開口部安吾
北大路魯山人 => 北大ルート洛連山人
のように変換します。
1.の方法にしたため、カタカナ名の作者はこのプログラムの対象外です(カタカナはちょうどよいパロディ化のアイデアが思いつきませんでした。)
2.は、全部変えてしまったらパロディにならないし、元から離れすぎるのもわかりにくいし、と悩んで決めた部分です。
def get_max_replace_char_num(name):
#切り下げ。 最低でも名前の半分を変更
return len(name) // 2
というロジックで名前の長さによって何文字変えるかを決定しています。
ランダムで1字以上、というのもありだったのですが、質を安定させるために文字数は固定に指定しました。
ただここは正解がない部分なので、開発者の「パロディ感」次第かなと思います。
以前このプログラムの前身として、「米津玄師みたいな名前を呟くbot」を作った際は、名前の各文字を一定の確率で類似語に起き変えるというロジックを使っていましたが、正直どちらがより質のよいパロディなのか、答えは出ていません。
ただ、ロジックとしては現在のものの方が汎用性はあると思います。
3.は若干本物と遠ざけてでも意外性を狙った部分です。本物との近さは置き換える対象文字数で担保して、置き換え後文字は多少遊びを許しました。
作者名パロディの別パターン案
実装時に思いつかなかったのですが、単語の「音」に着目して、似た音の単語と似た音の単語を「合成」させる方法も、パロディ(もしくはダジャレ?)の王道なので、試してもよかったなと思います。
夏目漱石 => 夏目掃除機
のようなパターンです。
漱石(Souseki)のSouと掃除機(Soujiki)のSouがかかっています。面白いかどうかはともかく、確実にかかっています。カタカナの名前もこのパターンならいけるかもしれません。
余談ですが、このパターンに気がついたのはこの記事を書いてる途中にたまたまyoutubeで見た動画がきっかけでした。その動画で『「乳透け」+「米津玄師」=「乳透玄師」(ちちすけんし)』という発言があり、音でかけて合成するパターンを見落としていたことに気がつきました。何か作ると、アンテナが張られて気づくことが増えるという良い例だったと思います。
パロディ感のチューニング
前述したような「名詞の置き換え」という実装において、パロディ感をチューニングする余地について思いつくところを書きます。
1. 類似度:類似単語候補を取得する時、何番目に類似してる単語までを候補にするか( Word2Vecの`most_similar`関数の`topn`引数を何にするか)
2. ゴミ判定:候補の単語のうちどこまでを使えない候補(ゴミ)とみなすか
3. 単語の恣意的な選択:候補の単語のうち、使用しない単語を恣意的に決めるかどうか
類似度について
類似度を下げた方が原文から離れる可能性はあがります。
その方がより類似でも何でもない単語がでてくる可能性があがり、「意外性」という面白さは増すように思います。
開発中は変換結果を見まくるので慣れてきてしまい、どんどん意外な結果が欲しくなってくるのですが、パロディとしての質は「近いけど異なる」方が高いと考えたので、デモサイト用にはtopn=7,8程度にとどめました。
ゴミ判定について
今回は []やCategory:が文字に含まれた語をゴミとみなして削除しましたが、使用するモデルの学習ソースが事なればこの部分は変わりそうです。自動生成感をだすために、これらをあえて残す、というのもありだと思います。
また逆に、「猫」の類似語「ネコ」を今回はゴミとみなしてませんが、単に読み仮名に変えただけで同じ単語なので、ゴミという判断もできました。(ただ判定がめんどくさそうです。同音異義語を例外にする必要があるので。)
単語の恣意的な選択について
ここはやりたくなかったのですが、ある程度「面白さ」を達成することを目的にしたため、最低限「人種差別的な表現に感じられて不快感のあるもの」を恣意的に排除しました。
例えば「人の上に人をつくらず」を元に文章を生成する時、「人」を「日本人」に変えるのは、まぁそこまで不快感がないかと思うのですが(作者が日本人なので、自虐感はあっても他人を貶める内容ではない)、「別の国+人」の単語を使った時の置き換え結果が、なにか「他の国の人をバカにしているような文章」に感じて、私自身読んでいて少し不快でした。
なのでそういった語は置き換え候補から恣意的に省いています。ただここは気持ち的に踏ん切りのついてないとこもあり、一旦ハードコーディングで対応しています。
女性に対する表現はどうするか、性的な単語をどうするか、なども悩みましたが、上記の「人種差別を感じようと思えば感じられる表現」以外は一旦誰かが不快だとはっきりいうまでは対応なし、としています。
こんなくだらないものをつくる目的でまさか自分の倫理感が問われるとは思っていませんでしたが、この辺は自動生成的なことをさせる上で避けられないのかもしれません。
逆に、開発者が面白いと思った単語だけを極力選ぶ、という恣意性も発揮することが可能です。ただそれをすると、「自動生成されたこと」自体の面白みを損なうと同時に、スベった時にプログラムのせいにできないというリスクのある恣意性です。そのようなリスクを負う覚悟がある方のみに許されたチューニングでしょう。
実装の詳細はこんな感じです。迷ったところをだいたい全部書いてしまいました。
そして迷ったところは実装方法よりも主観的な質の部分だったので、今振り返って実装時の狙いを改めて書いていても、正解がわからないままです。迷いながらもとりあえず完成できたのは、深夜寝不足の中で開発することで、判断力が落ちて大体何でも面白く感じる状態になっていたおかげです。ライフハック。
結果をどうやって人に見せるか
エンジニアの人以外にも見せる前提でつくってたので、
- デモサイト
- TwitterBot
の両方を準備することにしました。
デモサイトについて
意識したのは以下のあたりです。
機能要件:あるいはせっかくなので、練習しときたかったこと
- レスポンシブ
- 動作が軽い(Chromeのauditのスコア90以上を目指す)
- 複数の結果を見られる(文例を1000以上は見せたい)
- デプロイに時間がかからない
- 機能は最小限。SNSシェアとかInputとかは無し
- 最低限ogタグはつけておく
html+js+cssのみでフレームワークを何も使ってません。デプロイ先はNetlifyにして、githubのmasterにpushしたらデプロイされるようにしています。
読み込みを短くするためにデプロイ後の環境で文章生成ではなく、ローカルで作った結果を読み込むだけにしました。DBへのアクセスはなく、結果を入れたJSONを一括で読んでいます。JSONは500KB以下を基準にしました。
結果は以下。この程度の規模のアプリならperformanceも100狙うべきかとも思うのですが、標は超えたし、体感でも速いので、よしとしました。
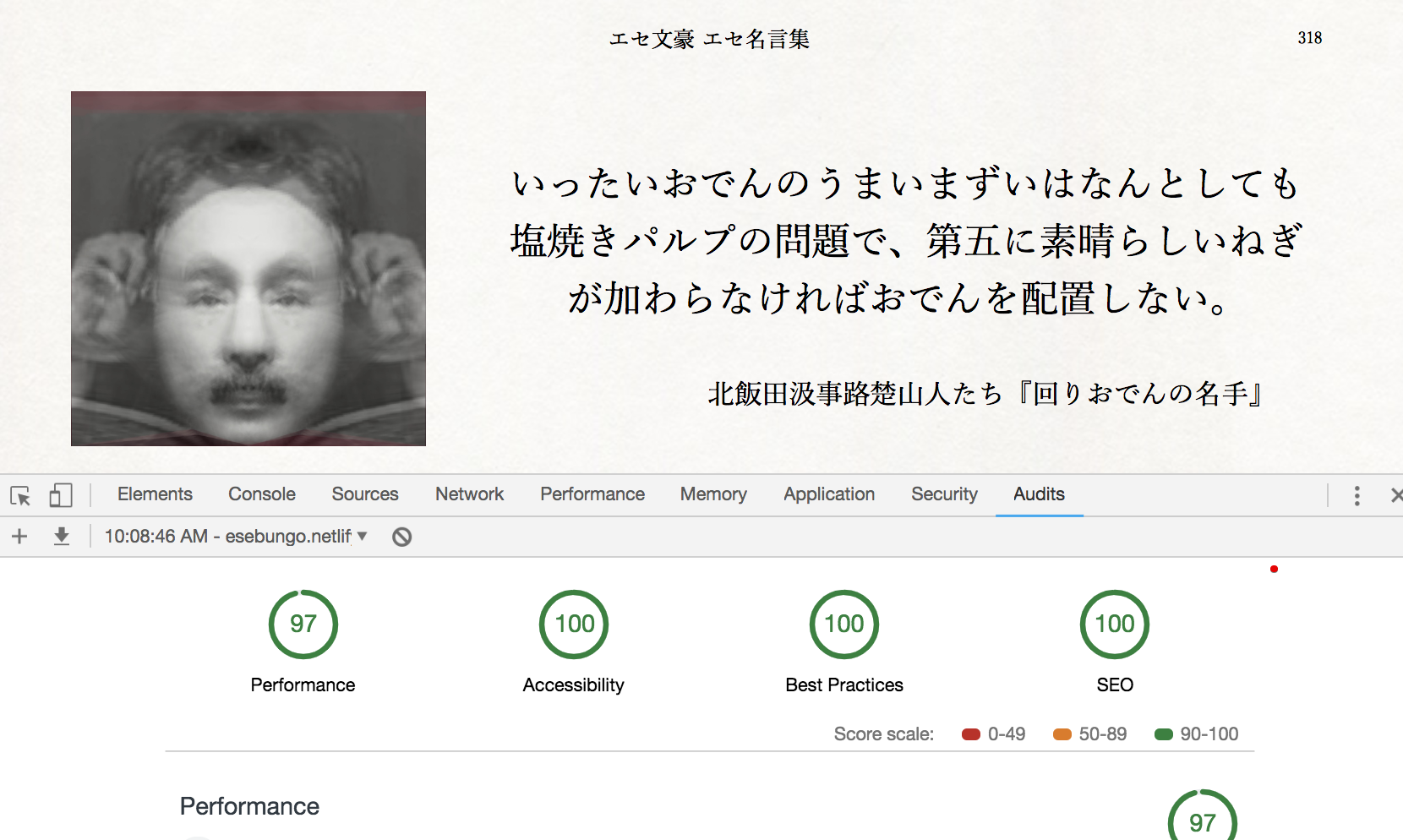
非機能要件:あるいは目的達成にあった方が良いと(最終的に)おもったこと
- 原文と比較できた方がパロディであることがわかりやすくて、面白いと思ってもらいやすそう
- 見た目に「本」としてのクラシック感が欲しい。内容のくだらなさとのギャップをねらうため
- 「文豪っぽい人」 がいると「誰やねん感」が増す。見た目もキャッチー
最初、ページの情報量を減らそうと思い原文比較なしで変換後の文章だけ載せてたのですが、原文とのが比較なしだと、置き換えの後の文に違和感がない時、単に「知らない人の知らない言葉」になりました。なので原文は載せることにしました。Twitterの方は文字数制限的に比較を諦めてます。
本っぽさ狙いで最初縦書きを試しましたが、そのままレスポンシブにするのがむずかしくて諦めました。この点は紙っぽい背景と明朝を使うことしかできていません。
最後の「文豪っぽい人」については文豪の顔写真を iOSアプリのAverage Face PROで適当に合成して、いくつかのバランスの「平均顔」を作成しました。
顔の部分は、名前と連動させたり、もっと頑張りようはあったかと思っています。あと、その場で顔の生成までできたら技術的にももっと面白いものになったかなと思っています。
デモサイト使い方
同じ作品を元にした結果は近くのページに固まっています
ランダムなページへ
文豪っぽい人(エセ文豪)の顔写真をタップまたはクリック、 もしくはエンターキーを押す
前のページまたは次のページへ
左右のキーまたは画面左上、画面右上、をクリック
モバイルだと文豪の左右をタップ
特定のページへ
"?page=:n" (:nは任意の数字)をURLにつける。
例: https://esebungo.netlify.com/?page=350
エセ文豪の写真変更
リロード。3種類からランダムでロードされます。
TwitterBot
こっちはHerokuにいます。その場で文章生成したかったのですが、mecab-python3のheroku上のinstallに失敗しまくり、おなじように失敗した記事は見つけても、力技以外の解決方法が見当たらなかったので、早々に諦めました。
プログラムと一緒に生成済みの内容をCSVでアップして、その中からランダムで一個呟くようにしています。Webアプリですらなく、 スケジューラで1時間に1度python app.py がrunされるだけの手抜き仕様です。
おわりに
こんなアホみたいなアウトプットのわりに結構悩んだところがあって我ながらびっくりします。この程度はせめて2-3日で作れるようになりたいです。もっと頑張ります。
ただ、文字通り寝食を忘れて夢中で作っていてとても楽しかったです。(あとエセ名言は深夜見ると面白みが増します。むしろ深夜以外はあんまりなので、深夜に見て欲しいです。)
今回のアイデアの発展系として作りながら頭にうかんだのは
- 一冊まるまる置き換える
- 英語版をつくる
- 名詞以外の置き換え
- 置き換え+ミックスでオリジナリティのある文章の作成をめざす
- パロディの別ルールを探す(音で合成、ダジャレ、など)
あたりです。
ただ今度は全然違うこと試したい気持ちもあります。人に見せる前提だと、画像をイジる系は見た目がキャッチーなので、もう少し挑戦したい気持ちが出てきました。
あと、普段の業務でPythonは使ってないのですが、自分の中でPyhtonは「手段のための言語」という感じがしていて、適当に書き散らかしても罪悪感がないので、とりあえず達成したいもののために気が楽にかけてよかったです。
知見(?)
今回自分が試みたように、「単語を機械的に変換するものが、結果的に人間の感覚からすると変になり、面白い」というのは、なんというか旧世代的で、いまだに「ロボはちょっとポンコツで変なことをするもの」という世界観から抜け出せていません。
「大喜利β」という人工知能にボケさせるプロジェクトがありますが、ああいうものこそがこれからの時代のエンジニアリング+お笑いなんだろうな、と思います。
後者のAIは面白さを理解させようとする試みですが、前者はいわば「天然ボケ」です。きっと「天然ボケ」のプログラムから(天然ではない)狙ってボケるプログラムへ、というのが時代の変化なのだろう、というのが今回図らずも得た知見です。
今後「狙ってボケるプログラム」の方が面白さの打率としては高くなっていくだろう、と思います。ただ、今回達成できたかは別にして、瞬間最大風速的な面白さ(見る側が突発的に笑う量)では、旧時代の天然ボケの方も何回に一回は勝てる余地が残るのではないか、という予想をしています。
長くなってしまいましたが以上です!
何かフィードバックなどいただけるととても嬉しいです。
お世話になったサイトたち
- 東北大学 乾・岡崎研究室: Word2Vecの日本版Wikipediaでの学習済みモデルを使わせていただきました
- Paper-co | 紙のテクスチャー素材を無料でダウンロードできるサイト: デモサイトの背景の白い紙画像をダウンロードさせてもらいました
- [Average Face PRO] (https://itunes.apple.com/us/app/average-face-pro/id560519978?mt=8): 「文豪っぽい人」の作成に使用。複数の文豪をこのアプリで合成。150円
- Netlify: デモサイトのデプロイ環境
- Heroku: TwitterBotのデプロイ環境
- Hatchful favionのロゴ作成に使用。あんまりデモのテイストにあってないのですが、このサービス自体はとてもいいです