はじめに
データベースを扱うとき、こんな悩みを感じたことはありませんか?
- データベースごとに文法が違うため、クエリを書き直すのが面倒である。
- 一度書いたクエリが再利用できない。
- 複数のデータソースを統合したいけれど、統一した操作方法がない。
ibis-frameworkを使用すれば上記の悩みを解決することができます!
ibis-frameworkとは
ibis-frameworkとはあらゆるデータシステムで動作するオープンソースのデータフレームライブラリです。
oracleやMySQLといった約20種類のバックエンドで同じAPIを使用することができます。

次の章で具体的な使い方を解説していきます。
ibisの使い方
ibisのインストール
$ pip install 'ibis-framework[mysql]'
[mysql]の部分は使いたいデータベースを選択してください。
ibisでMySQLに接続してみる
MySQLに接続してテーブルの中身を取得します。
con = ibis.mysql.connect()に必要な情報を入力して、MySQLに接続します。
import ibis
# MySQL接続
con = ibis.mysql.connect(
user = "root"
password = "password",
host = "ibis-mysql",
port = 3306,
database = "testdb"
)
# MySQLテーブルの取得
table = con.table('employees')
data = table.execute()
# 結果の表示
print(data)
employeesテーブルの中身が取得できました。
$python connect_mysql.py
employee_id first_name last_name hire_date
0 1 John Doe 2024-01-01
1 2 Jane Smith 2023-06-15
2 3 Bob Johnson 2022-11-22
ibisでPostgresに接続してみる
Postgresに接続してテーブルの中身を取得します。
con = ibis.mysql.connect()をcon = ibis.postgres.connect()に変更すれば、Postgresに接続できます。
import ibis
# Postgres接続
con = ibis.postgres.connect(
user = "root"
password = "password",
host = "ibis-postgres",
port = 5432,
database = "testdb"
)
# Postgresテーブルの取得
table = con.table('employees')
data = table.execute()
# 結果の表示
print(data)
employeesテーブルの中身が取得できました。
$python connect_postgres.py
first_name last_name hire_date
0 Bob Johnson 2022-11-22
1 Emma Davis 2024-02-01
2 Olivia Taylor 2023-05-20
このようにtable = con.table('employees')やdata = table.execute()の処理はMySQLやPostgresなどの使用するデータベースに関わらず、共通化されています。
他にもcreate_tableやgroup_byなど様々なクエリが共通化されています。
詳しくはhttps://ibis-project.org/backends/mysql.html を参照してください。
複数データベースにアクセスして、統合処理を行う。
MySQLとPostgresにアクセスしてテーブルの中身を取得し、pandasで統合します。
import ibis
# PostgreSQL接続
con_postgres = ibis.postgres.connect(
user="root",
password="password",
host="ibis-postgres",
port=5432,
database="testdb"
)
# MySQL接続
con_mysql = ibis.mysql.connect(
user="root",
password="password",
host="ibis-mysql",
port=3306,
database="testdb"
)
# PostgreSQLテーブルの取得
table_postgres = con_postgres.table('employees')
# MySQLテーブルの取得
table_mysql = con_mysql.table('employees')
# データをローカルに取得
data_postgres = table_postgres.execute()
data_mysql = table_mysql.execute()
# pandasを使用して統合
import pandas as pd
# PostgreSQL と MySQL のデータを pandas DataFrame に変換
df_postgres = pd.DataFrame(data_postgres)
df_mysql = pd.DataFrame(data_mysql)
# pandas の concat を使って統合
combined_df = pd.concat([df_postgres, df_mysql], ignore_index=True)
# 結果の表示
print(combined_df)
MySQLとPostgresのemployeesテーブルを統合することができました。
$ python union.py
first_name last_name hire_date
0 Bob Johnson 2022-11-22
1 Emma Davis 2024-02-01
2 Olivia Taylor 2023-05-20
3 John Doe 2024-01-01
4 Jane Smith 2023-06-15
5 Alice Brown 2022-11-22
このように異なるデータベースのデータを結合して分析することができます。
一度書いたクエリを再利用する
今までのプロジェクトで使っていたsqlスクリプトを再利用したい場面があると思います。
そのようなときはraw_sql()を使うことで簡単に再利用できます。
import ibis
# MySQL接続
con = ibis.mysql.connect(
user = "root"
password = "password",
host = "ibis-mysql",
port = 3306,
database = "testdb"
)
# SQL文の再利用
con.raw_sql("""
CREATE TABLE IF NOT EXISTS customers (
first_name VARCHAR(50),
last_name VARCHAR(50))
""")
# テーブルの取得
table_lists = con.tables
# テーブルの表示
print(table_lists)
customersテーブルが作成されました。
$ python reuse.py
Tables
------
- customers
- employees
また以下のようにMySQLのスクリプトをDuckDBに適用することもできます。
dialect="mysql"とすることでDuckDBにMySQLの文法でクエリを投げることができます。
しかしMySQLのAUTO INCREMENTをpostgresのSERIALに変換することはできなかったので、すべての文法の違いに対応してはいないことに注意です。
import ibis
import pandas as pd
# DuckDBに接続
con = ibis.duckdb.connect()
con.sql(
"""
SELECT
`species`,
`island`,
mad(`bill_length_mm`) AS bill_mad
FROM `penguins`
GROUP BY 1, 2
""",
dialect="mysql"
)
その他便利機能
GraphViz連携
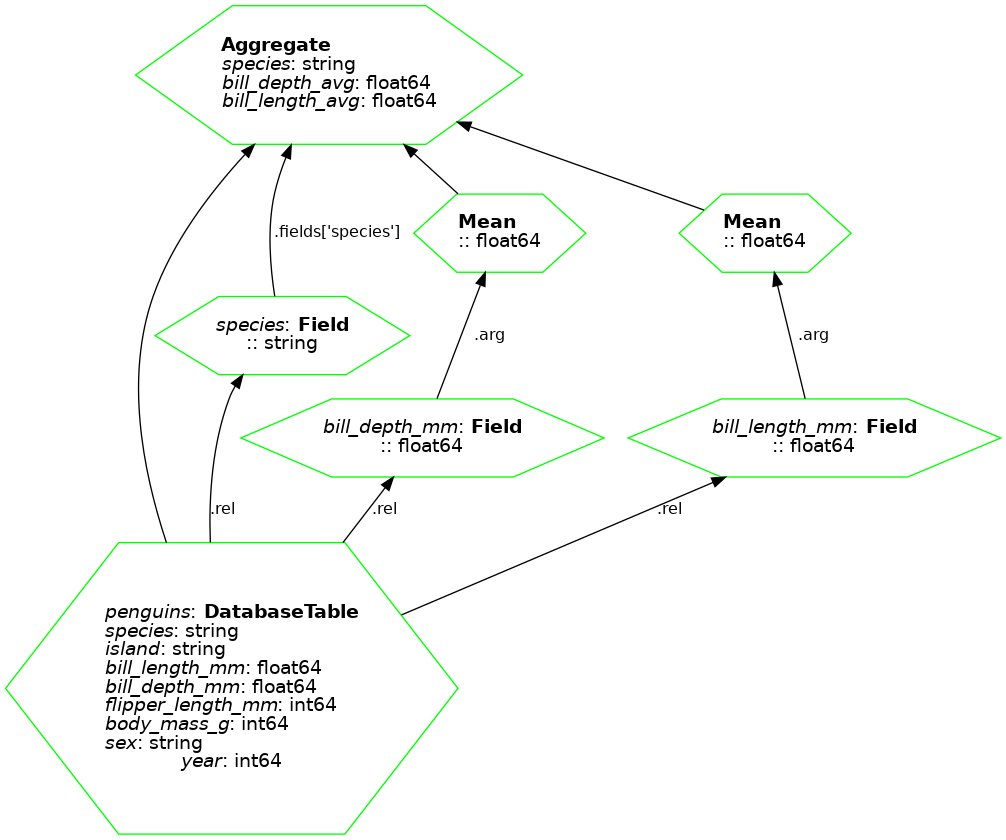
ibisのGraphViz連携は、Ibisのクエリ式を視覚化するための機能です。
この機能を使うことで、ibisの式を表現する内部データフローを有向グラフとして表示できます。
グラフは各ステップの処理内容やその依存関係を明確に表します。
下記コードではサンプルテーブルに対してmeanやgroup_byの処理が行われており、グラフとしてそのフローが可視化されていることが分かると思います。
他にもstreamlitやseabornなどの可視化ライブラリとも連携ができるので、興味があれば調べてみてください。
import ibis
from ibis import _
from ibis.expr.visualize import to_graph
t = ibis.examples.penguins.fetch()
expr = (
t.group_by(_.species)
.agg(
bill_depth_avg=_.bill_depth_mm.mean(),
bill_length_avg=_.bill_length_mm.mean(),
)
)
to_graph(expr,label_edges=True,
node_attr={"shape": "hexagon", "color": "green", "fontname": "Roboto Mono"},
edge_attr={"fontsize": "12", "fontname": "Comic Sans MS"})
まとめ
- ibis.database-name.connect()のdatabase-nameを変えるだけで、異なるデータベースにアクセスすることができます。
- 異なるデータベースのデータを結合して分析することができます。
- raw_sql()を使用することで、スクリプトを再利用することができます。
- dialectを指定することで異なるデータベースの文法を吸収することができるが、全てには対応していないことに注意してください。
- GraphViz連携により、ibisのクエリを可視化することができます。