はじめに
Quantum Espresso(QE)(QE)は無料で使える電子密度汎関数法による電子構造計算プログラムである。バージョン6.8以降のソースコードはNVIDIAのGPGPUにも対応していることからNVIDIA HPC SDKがインストールされたLinux環境でビルドできる。
NVIDIA TeslaなどGPGPUボードはスーパーコンピューター用などと説明されていることもありGPGPU版QEのインストール記事はスパコン環境用の記述が多く小規模ワークステーション用の日本語記事が少ない。Configure時に必要な知識に関するページも見当たらないためメモ書きする。
インストール前に
事前にNVIDIA HPC SDKをインストール済みであることを前提。手順は前にこちらにメモ書き済み。
GPGPUボードドライバを当てるとディスプレイ表示に異常が出る場合がある。この対策として事前に固定IP設定、sshおよびxrdpをインストールしておく。またWindowsリモートデスクトップからUbuntuデスクトップへリモート接続できるようWindows Pro版がインストールされているマシンを準備しておくのがよい。
倍精度計算対応のデータセンター用GPGPUの取り付けとドライバはインストール済みであることが前提。Ubuntuの場合はデータセンター用GPGPUのドライバは公式サイトからダウンロードするのではなく下記コマンドで最新版をインストールできる。
$ > sudo ubuntu-drivres autoinstall
インストール後、再起動。ターミナルから下記コマンドを入力しボード情報が表示されていれば使用できる。
$ > nvidia-smi
Intel One APIもインストールされている場合は~/.bashrcにあるOne API設定をコメントアウトしNVIDIA HPC SDKのみをロードしておく。
Quantum Espressoソースコードダウンロード
こちらのサイト上部のdownloadを押すとログイン画面が現れる。登録していない場合は"register"から必要な情報を入力、"privacy policy”にチェックを入れれば無料で登録できる。登録後、downloadページからメアド、パスワード、表示されているsecurity codeを入力すると複数バージョンのダウンロードURLが表示される。
QEは最新バージョンでなく7.0を使用。7.2で複数GPGPUボードつきシステムを試したところGPGPUへのデータ転送でプログラムが止まってしまった。解決法がわからないため動作した7.0を使用した。またQEのOpen benchmarkで使用されているのが7.0であることも理由の一つ。
ターミナルからwgetコマンドでQE-7.0ソースコードをダウンロード後、解凍するとQE-7.0ディレクトリが生成する。GPU版をmake & installするのでディレクトリ名をQE-7.0-gpuに変更しインストールに使用した。
configure & install
GPGPU版QEのconfigureについては公式マニュアルが詳しい。
QE-7.0-gpuディレクトリに移動し下記を参考に自身のシステムに合わせて入力。
$ > ./configure –with-cuda=value1 --with-cuda-runtime=value2 --with-cuda-cc=value3 --with-cuda-mpi=yes --enable-parallel --with-scalapack=no
コンパイラ名を明示したい場合は下記になる。
$ > ./configure MPIF90=mpif90 F90=pgf90 F77=pgf77 CC=pgcc –with-cuda=value1 --with-cuda-runtime=value2 --with-cuda-cc=value3 --with-cuda-mpi=yes --enable-parallel --with-scalapack=no
上記のvalue1、value2、value3は下記。
value1: インストールされたcudaディレクトリパス。例:/opt/nvidia/hpc_sdk/Linux_x86_64/23.7/cuda/12.2
value2: cudaバージョン。上記の場合12.2
value3: cuda compute capability: 小数点を除いた2桁数。K20, K40, K80なら35; P100は60; NVIDIA Titan V, V100は70など
configureでエラーが出ていないことを確認後、
$ > make all
でbinディレクトリに実行ファイルがビルドされる。これには時間がかかるのでお茶でも飲んでのんびりする。
実行用にこのbinディレクトリパスを~/.bashrcにexportしておく。
nvidiafortranではプログラム停止時にPROGRAM STOPメッセージが表示され目障りに感じる人は~/.bashrcへ下記を追記して表示を止める。
export NO_STOP_MESSAGE=y
環境によってはQEを走らせたときに下記メッセージで止まることがある。
error while loading shared libraries: libnvJitLink.so.12: cannot open
shared object file: No such file or directory
この場合は~/.bashrcへ下記を追記し、ターミナルを再度立ち上げれば解決できる。
export LD_LIBRARY_PATH=/opt/nvidia/hpc_sdk/Linux_x86_64/23.11/cuda/12.3/target/x86_64-linux/lib:$LD_LIBRARY_PATH
ディレクトリ名については自身のシステムに合わせること。
未解決問題
QE-7.0の場合、NDIVIA HPC SDK環境でgipawのビルドエラーが発生するため使えない。前述したがQE ver. 7.2では複数GPGPUボードをインストールした環境では計算がハングアップした。サポートページにも似たような現象に見舞われたユーザーがいるようだが、これはソフト問題ではなくハード側の問題との回答だった。しかし解決法については何も記載がなかった。
ベンチマーク
NVIDIA TESLA P100を6枚実装したワークステーションでこちらのベンチマークデータAUSURF112でベンチマークを計測した。TESLA P100(16GB)モデルの場合、このベンチマーク計算には最低4枚のボードがインストールされている必要がある。計算にはボード1枚当たりに1ノード与える分散計算をする。ターミナルでベンチマークデータがあるディレクトリへ移動し下記コマンドで6ボードを使う分散計算ができる。(出力ファイル名をausurf112.outとした場合)
mpirun -np 6 pw.x < ausurf112.in | tee ausrrf112.out
ベンチマーク結果は下記の通り。
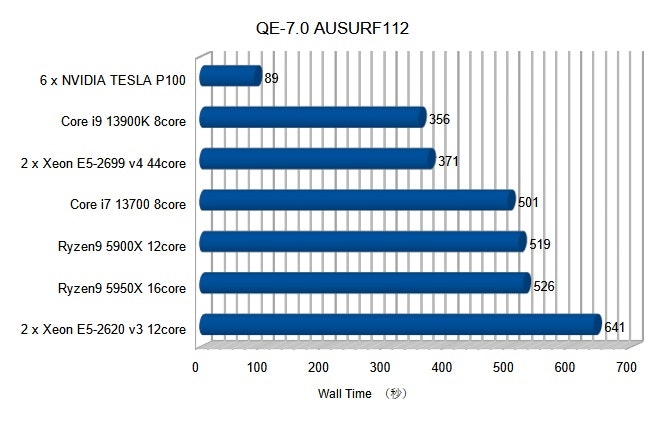
Wall Timeは計算に要した時間で短いほど計算能力が高いことを示す。TESLA P100システムの計算時間はCore i9-13900Kシステム時間の約1/4である。この速度はOpen Benchmarkで登録されている結果と比較してもトップである。(Open BenchmarkのトップマシンはAMD EPYC 75F3 32-CoreのデュアルPUシステム(計64コア)の271秒)
TESLA P100は生産終了品ではあるがQE計算ではまだまだ活躍できる性能を有することがわかるだろう。
GPGPU版QEの弱点
QEは様々な計算プログラムの集合体である。pw.xではハイパフォーマンスになるが、プログラムによってはパフォーマンスが落ちるものもある。
QE計算でGPGPUを導入しようと考える人は大きなモデルで計算時間が長い計算をしたい人が多いと思う。大きなモデルを扱う場合、当然ながらGPGPU側で大きなメモリを準備しなくてはならない。そのため複数のGPGPUボードをインストールする必要がある。NVIDIA TESLA P100(16GB)モデルの場合、最大消費電力は250 W/枚である。したがって4枚使用するには1000 W、6枚なら1500 W電源が最低でも必要になる。現在の高電力価格ではややつらい仕様になる。6枚仕様でも最大メモリは96GBにしかならない。GPGPUの場合はスワップメモリなどの代替増設手段もない。
まとめ
GPGPU計算ワークステーションをお試ししたい時には価格が落ちているP100が手頃といえるだろう。ただしTensor Coreは内蔵していないのでこちらを使いたい場合はV100以上のボードを使う必要がある。よく下調べしてから導入しないと痛い目にあいかねないので要注意。