なにを作ったの?
Nijisanji Live Checkerという,にじさんじの配信を同時視聴するためのWebアプリを作りました (HerokuがBANされたので閉鎖しました) . https://nijisanji-lc.web.app/
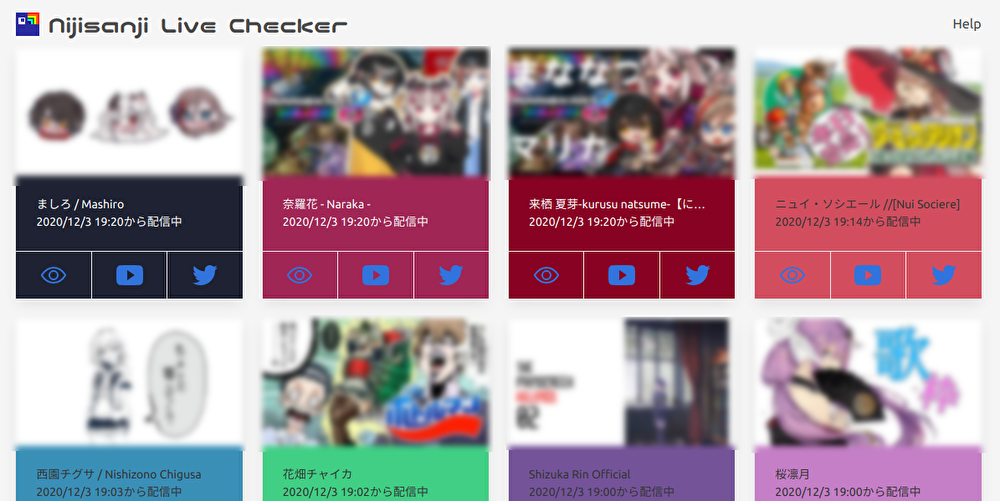
↑こんな感じでライブ中の配信が一覧でみれます.(一応サムネはぼかしてます)
目のアイコンを押すと,↓のように同時視聴ができました.
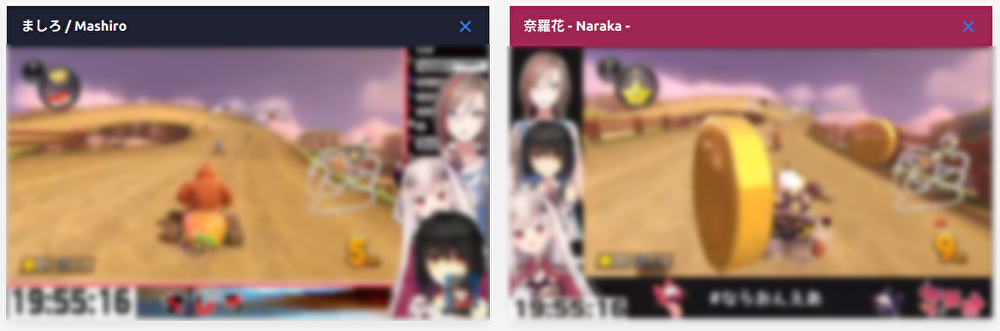
こんな感じにスマホ,タブレットでも複窓して見れました.今は複窓では見れません.
なので,現状はライブ中の配信のまとめサイトみたいになってます.ただ,同様の(にじさんじの)配信まとめサイトに比べて,正確かつ高速に配信状況をキャッチできていると思います.遅くとも配信が始まってから3分以内にはこのサイトに反映されていると思います(体感).
まぁ,実はこれ去年に作ったやつなんですが,Advent Calendarがあるのでいまさら書いてみたいと思いました.複窓できない経緯についても少し触れたいと思います.
なんで作ったの?
スマホ,タブレットだと配信を同時視聴できない
Youtubeアプリだとひとつのライブ配信しか見れないので,コラボ配信などを同時に見たいと思ったので作りました.スマホで複窓みるためのWebアプリもいくつかあったがURLを打ち込む必要があり,めんどくさかった.(2019年末当時)ライバーが多くて配信を把握できない
にじさんじには100名を超えるライバーがいるので全員の配信を把握するのは難しい.誰が今配信しているのかをひと目で確認できるものが欲しかった.勉強のため
Firebase, Herokuなどの技術に興味があったので,勉強する目的もあった.何か作ろうとしないと何もしない性格なので,せっかくなので作ってみた.
技術的なお話
利用した技術一覧
- HTML / CSS (Bulma) / JavaScript
- Firebase Hosting (アクセスポイント)
- Firebase Cloud Storage (データベースとして利用)
- Heroku (Youtube配信情報の取得)
- Python, Youtube Data API
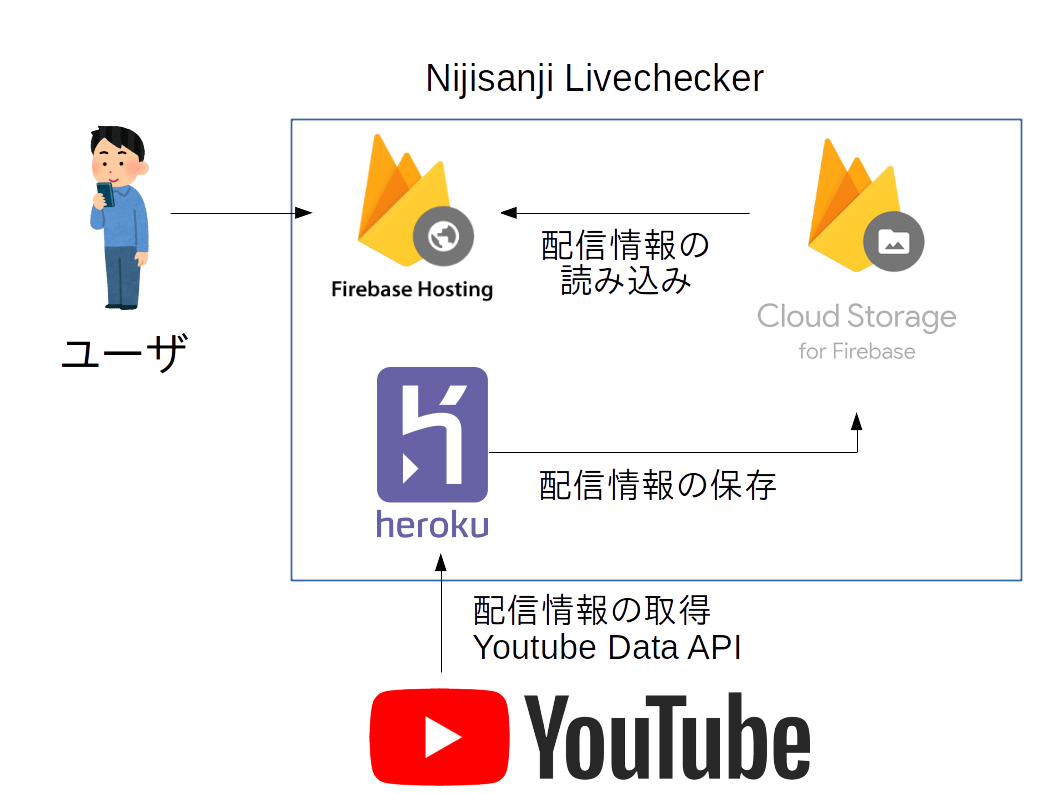
システムの全体図
学んだこと
新しく学んだこと/悩んだところについて,雑多にまとめてみる.
サービスの利用規約は守りましょう!!!
一番大切なことなので最初に書きます.それは,利用するツール,サービスの利用規約は守る必要があるということです.
実は配信の埋め込みをひとつのページに複数表示させるのはYoutubeの規約に違反するそうです.HoloLiveの複窓ツールにHolotoolsというものがあるのですが,今年の6月にYoutubeから利用規約違反の通告を受けたそうです(詳しくは作者のTwitter).この禁止行為に抵触したようです.
複数のYoutube動画の埋め込みがあるサイトはたくさんあるように思うのですが,それらもアウトなのでしょうか.
正直,この記事を半分くらい書き終えてからこの事件(?)について知りました.このアプリは去年末から公開しているので,万が一にも話題になっていたら面倒なことになっていた可能性があったので,宣伝しなくて本当に良かったと思いました.現在は複窓ができないように修正済みです.
更新(2020-12-06)
上記の規約についてはYoutube Player APIで埋め込んだ複数の動画を1つだけ再生させる制御の記事で知りました。
HerokuのWorkerを使う
全体図でもあるとおり,ライブ中の配信情報をHerokuに走らせているプログラムで取得しFirebase Storageに保存している.極端な話,この部分は自分のPCで代替することも可能であるが,安定して運用するためにHerokuのWorker Dynoを利用した.ずっと走らせたいプログラムがあったら無料でPC代わりに使えるので便利![]()
ここではHerokuのWorker Dynoを使う方法をまとめてみる.基本的にはWeb Dynoと使い方は同じでGithubレポジトリをHerokuに登録すればデプロイできる.
-
Procfileを用意する
どのコマンドをWorker Dynoに実行させるかをProcfileに明記する. このファイルはプロジェクトのルートディレクトリにおいておく. 例えばpython run.pyというコマンドを実行したい場合は以下のように書く.
worker: python run.py
runtime.txtを書く
実行するPythonのバージョンをruntime.txtというファイルに明記する.
このファイルもルートディレクトリにおいておく
結構このruntime.txtの書き方が厳しいのだが,公式のサポートが役に立った.デプロイして,動いているか確認
↓みたいになればOK
robots.txtに従ったWebスクレイピング
Youtube Data APIでは配信予定の動画を取得できないので,このアプリではスクレイピングを用いている.search.listを使えばできないことはないが,Quota(後述)の上限的に厳しい.
しかし,Youtubeではボットによる自動アクセスについて以下の様に禁止されている(2020-12-04時点,LINK)

(a)にあるように公開されている検索エンジンを用いてかつrobots.txtに従えば自動アクセスは禁止されていない.なので,このアプリで使っている検索エンジンを以下に公開する.検索エンジンの定義についてはこちら.pythonではurllib.robotparser.RobotFileParserを使うことでrobots.txtをパースできる.
import re
from time import sleep
import urllib.robotparser
import requests
def collect_video_ids(channel_ids, delay):
def fetch_video_ids(cid):
result = set()
url = f"https://www.youtube.com/channel/{cid}/videos?view=57"
if not rp.can_fetch("*", url):
print(f"ACCESS REJECTED: {url}")
return result
resp = requests.get(url)
if resp.status_code != requests.codes.ok:
return result
for wid in re.findall(r"watch\?v=\S{11}", resp.content.decode("utf-8")):
result.add(wid.split("watch?v=")[1])
return result
def fetch_all_video_ids():
result = set()
for cid in channel_ids:
result |= fetch_video_ids(cid)
sleep(delay)
return result
rp = urllib.robotparser.RobotFileParser()
rp.set_url("https://www.youtube.com/robots.txt")
rp.read()
return fetch_all_video_ids()
YoutubeAPI,Quota
このアプリではYoutube Data APIを使って動画が配信中かどうかの判定をしている.Youtube Data APIを使う際の障壁となるのがQuotaの管理である.Youtube Data APIの各操作にはQuotaと呼ばれるコストが設定されていて,初期設定では10000Quotaが上限として割り当てられている.配信の状態をチェックするためにvideos.listを利用している.この一回あたりの呼出Quotaは1であるが,愚直に使うとすぐに上限に達してしまう.このアプリで色々工夫を行っているが,ここでは誰でもできるvideo.listのQuotaの節約法を紹介する.
youtube = build("youtube", "v3", developerKey="your api key")
PART = # blabla
FIELDS = # blabla
id_list = ["videoId1", "videoId2", ...]
id_field = ",".join(id_list)
resp = youtube.videos()\
.list(part=PART, id=id_field, fields=FIELDS)\
.execute()
videoIdの数が一つだろうと複数だろうと(上限50)消費Quotaは変わらないので,もし複数のvideoの情報が欲しい場合はできるだけまとめてAPIを叩くと良い.videoIdとはyoutube動画のIdのことで,例えば,動画URLがhttps://www.youtube.com/watch?v=5PlI9i4XWDkの場合,5PlI9i4XWDkがIDである.これをカンマつなぎの文字列として入力することで複数のvideoの情報を一度で得られる.
このアプリでは1日あたり約2000〜3000Quotaの消費で抑えられている.
どのデータベースを使う?
この部分が一番悩んだところです.当初の選択肢としてはHerokuのredisとFiresotreがありました.
Herokuのredis
この場合だとHerokuのWeb Dynoを利用するため,無料枠で利用しようとするとWorker Dynoが使えなくなるため断念した.一応テストとして使ってみたが,Herokuのリージョンは欧米であるため,レスポンスがかなり遅い(体感).特にアクセスが一定時間ないと無料枠のHerokuのWeb Dynoはスリープするため,かなりレスポンスが遅くなる.Firestore
書き込み/読み込み回数の上限が厳しいため,断念した.このアプリでは,サーバ(Heroku)とクライアントの両方から読み取りが発生するため,特に読み込み上限に達することがあった.レスポンス面に関してはHeroku上のredisと比べると大幅に改善されたが,また若干もっさりしていた(体感).JavaScriptから呼び出せるNoSQLデータベースはとても魅力的だったが,クライアントからの書き込みがない場合は無理してこれを使う必要はないのかと思った.
結果として,FirebaseのCloud Storageを使うことにした.このアプリでは結局,配信情報をクライアント側で読み込めば良いだけなので,Cloud Storageに配信情報が入ったjsonを静的に配置するだけで十分だった.Firestoreに比べても書き込み/読み込み制限もゆるく,レスポンスも高速だった(体感).
ユーザに静的ページにアクセスさせ,静的ファイルをダウンロードさせるのが今回の場合は最適だという結論に至った.データベースをサーバサイドに用意する場合はデータベースの知識も必要になり構築の難易度が高いが,Firebaseにはさまざまな言語へのAPIがサポートされているため,とっつきやすかった.
Reactを使う? HTML/CSS/JS? フロントエンド?
当初フロントエンドはReactを使って書いていましたが,色々改善していくうちにHTML/CSS/JSに落ち着いた.ReactはhtmlとJavaSciptを同じファイルにかける(jsx)が,これが正直わかりづらく,HTMLの要素をJavaScriptで操作するほうが理解しやすかった.jQueryというものもあるらしいが,Vanilla JavaScriptが個人的に一番わかりやすかった.このアプリでは配信データをダウンロードしてレンダリングするが,この部分がReactで実行するのがややこしかった(useEffectフックを使ったイベントの管理).JavaScriptなら以下のような関数を用意して,それを実行すればよいだけなので,分かりやすかった.
const fetchData = async (storage, fname) => {
// storage はfirebase.storage()で生成されたオブジェクト
// fnameはCloud Storage上のファイル名
const pathRef = storage.ref(fname);
const url = await pathRef.getDownloadURL();
const resp = await fetch(url);
return resp.json();
};
大規模なプロジェクトになるとReactの恩恵が大きいかもしれませんが,この程度の小規模なSPAを作るにはJavaScriptで十分だった.
また,早く形にしたかったのでパッケージ管理は行わないことにした.このWebアプリではFirebase, ion-icon, bulmaを外部ライブラリとして利用しているが,全てhtml内でCDNを読み込んで利用している.
お金について
ライブチェッカーの作成に当たって利用したサービスは全て無料である.もちろん維持費も一切かかっていない.正直お金をかけて作る/使うものでもないし,収益化するつもりもない(誰も使ってないのでできない)ので,無料のものしか使わなかった.
作った当時(2019年の12月くらい)にGoogle Adsenseを申し込んで見たがだめだった.まぁ広告があるとうざいので今後も収益化はしないと思う(多分).Webアプリなんかつくっても労力にたいして収益が少ない
作り切るには
こういう感じの個人開発をしたのは初めてでしたが,サービスを作り切るにはある程度集中して取り組み,細かいことを考えないのが大事なのかなと思いました.例えば,今回の場合でもフロントサイドのパッケージ管理などはしたほうがいいと思いますし,HTML+JavaScriptではなく,ReactやTypeScriptを使うほうがモダンでかっこいいと思います.でも面倒なら別にやんなくていいと思いました.こういうWebアプリってたいていユーザ登録機能とかあるからなんとなく作ってみたいなと思ったりもしましたが,絶対めんどくさいことになるし,必要ないのでやめました.あと,アーカイブの検索とかもできたらいいのかなとも思いましたが,面倒なのでやってません.
当然ですが,自分が作りたいものを作るのがやる気を保つのに一番いいと思います.
おわりに
興味があれば使ってみてください![]()
あと,何かの規約的にアウトなところがあれば,速攻でアプリを削除するのでおしえてください.