世の中には様々なWebスクレイピングツールがありますが、その中でも今回はPuppeteerという、Googleが管理しているOSSを使用しました。
https://github.com/puppeteer/puppeteer
Puppeteer
**Puppteer(パペティア・パペッティア)**は、Google Chromeの機能を引き継いで開発されているChromiumと呼ばれるブラウザを自動操作することができるNode.jsのAPIです。
Puppeteerではブラウザを表示することなくバッググラウンドで操作することができる”ヘッドレスモード"を使うことができるため、高速かつメモリを節約した自動操作をすることができます。
(もちろんオプションでブラウザを表示することもできるため、デバッグも簡単です。)
さらに、手動でできるようなユーザの操作(例えば文字の入力やクリックなどのマウス操作や、キーボードを用いた他の操作など)のほとんどを行うことができるため、SPAやSSRなどのWebページでも、簡単に操作することができます。
この記事で紹介すること
- Puppeteerを用いた簡単なページ操作とデータの取得
- Puppeteerで取得したデータのcsv書き出し
想定読者
- nodeモジュールの概念を理解している
- npmで簡単な操作ができる
- HTML構造など、DOMの概念を理解している
バージョン
| 使用するもの | バージョン |
|---|---|
| node | 10.15.3 |
| npm | 6.13.0 |
| puppeteer | 2.0.0 |
| csv-writer | 1.5.0 |
準備
Puppeteerはnpmを使って簡単にインストールできます。
合わせて、ページから取得した情報をcsvに書き出すためにcsv-writerもインストールしましょう。
npm install csv-writer --save
Hello World
Puppeteerはプログラミング言語ではないので、一般的な"Hello World"とは少し違いますが、最初に簡単な操作を行ってみましょう。
まずhello-world.jsというファイルを作成します。
(今のところディレクトリ構造は以下のようになっていると思います。)
- hello-world.js
- package.json
- package-lock.json
- node_modules/
https://github.com/puppeteer/puppeteer
Puppeteerのページにもある下記のコードで、Googleの検索ページに移動できます。
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.google.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
実行は以下のように行います。
node hello-world.js
どうですか?
ヘッドレスモードで実行されてしまい、よくわかりませんでしたね。
デバッグに便利なヘッドフルモードも試してみましょう。
hello-world.jsの4行目(const browser...)を以下5行と置き換えてみましょう。
const options = {
headless: false, // ヘッドレスをオフに
slowMo: 100 // 動作を遅く
};
const browser = await puppeteer.launch(options);
これで実行してみると、実際にGoogleのページに遷移しているのがよくわかります。
要素の取得
上記の例でわかるように、基本的にPuppeteerは、
- Puppeteerでbrowserを作成
- browserでpageを開く
- pageを移動、またはpage内の要素を操作
という操作を行います。
要素を取得できるメソッド
URLが分かっていればpage.goto()でページ遷移できますが、それ以降のクリック操作や要素の文字列取得は、要素を指定して行います。
要素、つまりボタンやフォームの入力ボックスなどはXPathやセレクタを使って取得できます。
//XPath
const elems = await page.$x('//a[@class="major-link"]'); // page.$x()の返り値は配列(該当する要素が一つの場合でも要素数1の配列を返す)
//セレクタ
const elem = await page.$("#form"); // page.$()の返り値は単数要素(該当する要素が複数ある場合でも最初に見つけた要素だけ1つ返す)
const elems = await page.$$("a.red-link"); // page.$$()の返り値は配列
基本的に返り値がPromiseなので、awaitを前につけて記述すると楽です。
https://github.com/puppeteer/puppeteer/blob/v2.0.0/docs/api.md
さらに、上のドキュメントで確認してもらうとわかるのですが、返り値が配列であるときと、そうでない時があるので注意が必要です。
返り値が配列であるようなメソッドを使用する場合は、たとえそのセレクターに該当する要素が一つの場合でも長さが1の配列を返します。
とはいえ返り値が配列でも操作はそれほど変わりません。
const elem = await page.$("a.major-link"); // page.$()の返り値は単数要素
await elem.click(); // elemに格納されている要素をクリック
const elems = await page.$$("a.major-link"); // page.$$()の返り値は配列
await elems[0].click(); // elemsの0番目の要素をクリック
これまで"要素"と言っていたものはPuppeteerの世界では、ElementHandleクラスと呼ばれています。
https://github.com/puppeteer/puppeteer/blob/v2.0.0/docs/api.md#class-elementhandle
この章に書かれているメソッドを使用すれば、クリックやその他の操作ができます。
XPathとセレクタの取得とデバッグ
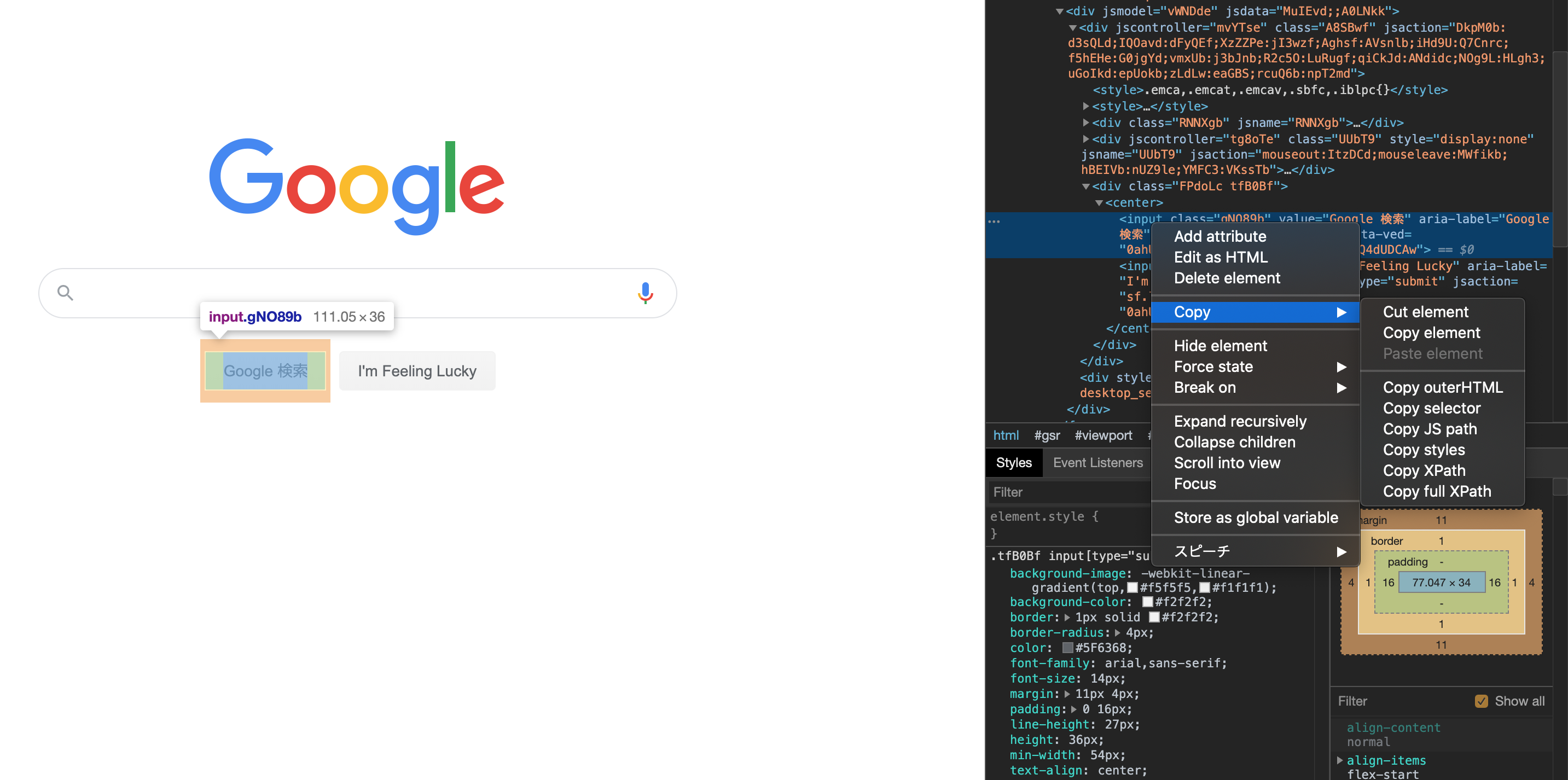
画像のように、Google DevToolsで表示したソースコード上で右クリックして、
Copy → Copy XPath or Copy selector
を選択すると、簡単にXPathかセレクタを取得できます。
また、自分で書いたXPathやセレクタで本当に要素が指定できているか確認したいときは、
同じようにDevToolsのconsoleタブを開き、以下のように入力します。
document.querySelector("input.gNO89b"); // セレクターで1つ要素を指定
document.querySelectorAll("input"); // セレクターで複数要素を指定
$x('//button[contains(text(), "検索")]'); // XPathで複数要素を指定
要素の文字列取得
ボタンをクリックしたり、フォームを入力できれば、ページ内の大抵の操作ができます。
次は、必要な情報(文字列)を取得する操作です。
細かい説明は省きますが、以下のように行います。
const xpath = '//section/div/p[contains(@class, "main-sentence")]';
const elems = await page.$x(xpath);
const jsHandle = await elems[0].getProperty('textContent'));
const text = await jsHandle.jsonValue();
// textにxpathで指定した要素の文字列が入る
CSV出力
csv-writerを使えば簡単にcsvファイルへの書き込みができます。
const data = [
{id: 1, name: "John", score: 90},
{id: 2, name: "Paul", score: 80},
{id: 3, name: "Ringo", score: 91},
{id: 4, name: "George", score: 100}
]
const csvWriter = createObjectCsvWriter({
path: "output/csv/result.csv",
header: [
{id: 'id', title: 'No.'},
{id: 'name', title: '氏名'},
{id: 'score', title: '点数'}
],
encoding:'utf8',
append :false,
});
csvWriter.writeRecords(data)
.then(() => {
console.log('Done');
})
指定したパスのcsvファイルにデータを書き込んでくれます。
※このときこのパスのファイルがないとエラーになるので、先に作成しておく必要があります。
書き込むデータは、headerで指定したidをキーとするオブジェクトを渡します。
書き込み後の結果はこんな感じです。
No.,氏名,点数
1,John,90
2,Paul,80
3,Ringo,91
4,George,100
headerのtitleで指定した値が最初の行にきます。もちろん設定で消すこともできます。
【おまけ】目黒のいい感じのレストランをcsvで吐き出してスプレッドシートで見てみる
Rettyで目黒のいい感じのレストランを検索したら83件ヒットしました。
スクレイピングしながら、20件データをとるごとにcsvに出力していくようにしました。
これで出力したcsvをスプレッドシートにインポートできます。
GitHubにも同じソースコードを置いています。
READMEに書いてあるコマンドを入力するだけでスクレイピングできるようにしていますので、興味がある方はご覧ください。
https://github.com/k1832/retty-scraping
const puppeteer = require('puppeteer')
const fs = require('fs')
require('dotenv').config()
const {createObjectCsvWriter} = require('csv-writer')
const OUTPUT_PATH = "retty"
let BROWSER
const VIEWPORT = {
width : 1280,
height: 1024
}
const xpath = {
searchResult: {
restaurantLinks: '//a[contains(@class, "restaurant__block-link")]',
nextPageLink: '//li[contains(@class, "pager__item--current")]/following-sibling::li[1]/a',
nextPageItem: '//li[contains(@class, "pager__item--current")]/following-sibling::li[1]'
},
restaurantDetail: {
restaurantInformation: '//*[@id="restaurant-info"]/dl[1]',
}
}
const selector = {
searchResult: {
hitCount: '.search-result__hit-count'
},
restaurantDetail: {
lastPageLink: '#js-search-result > div > section > ul > li:last-child > a',
pagerCurrent: 'li.pager__item.pager__item--current'
}
}
;(async() => {
/**** setup ****/
const options = process.env.HF
? {
headless: false,
slowMo: 100
}
: {}
BROWSER = await puppeteer.launch(options)
let page = await BROWSER.newPage()
let newPage
await page.setViewport({
width : VIEWPORT.width,
height: VIEWPORT.height
})
/**** setup ****/
let data = []
const url = "https://retty.me/restaurant-search/search-result/?budget_meal_type=2&max_budget=9&min_budget=6&latlng=35.633923%2C139.715775&free_word_area=%E7%9B%AE%E9%BB%92%E9%A7%85&station_id=1371"
await page.goto(url, {waitUntil: "domcontentloaded"})
const lastPageNum = await getTextBySelector(page, (selector.restaurantDetail.lastPageLink))
const hitCount = await getTextBySelector(page, selector.searchResult.hitCount)
console.log("総ページ数: " + lastPageNum + ", 総件数: " + hitCount)
let currentPageNumber
while(true) {
currentPageNumber = await getTextBySelector(page, selector.restaurantDetail.pagerCurrent)
let restaurantsList = await page.$x(xpath.searchResult.restaurantLinks)
for(let i = 0; i < restaurantsList.length; ++i) {
console.log(currentPageNumber + "ページ目【" + (i+1) + "件目】")
await restaurantsList[i].click()
newPage = await getNewPage(page)
await newPage.waitForXPath(xpath.restaurantDetail.restaurantInformation)
/***** retrieve page contents *****/
const dataArray = await Promise.all([
20*(currentPageNumber-1) + i + 1,
getName(newPage, getTableInfoXPath("店名") + '/ruby/span', getTableInfoXPath("店名") + '/ruby/rt'),
getTextByXPath(newPage, getTableInfoXPath("予約")),
getTextByXPath(newPage, getTableInfoXPath("住所") + '/div/a'),
getTextByXPath(newPage, getTableInfoXPath("定休日")),
getTextByXPath(newPage, getTableInfoXPath("ジャンル") + '/ul/li'),
getTextByXPath(newPage, getTableInfoXPath("座席")),
getTextByXPath(newPage, getTableInfoXPath("営業時間")),
newPage.url()
])
console.log(dataArray[1]) // restaurant name
/***** retrieve page contents *****/
data.push({id: dataArray[0], name: dataArray[1], phone: dataArray[2], address: dataArray[3], holiday: dataArray[4], genre: dataArray[5], chairs: dataArray[6], hours: dataArray[7], url: dataArray[8]})
await newPage.close()
}
await csvWrite(data, currentPageNumber)
const nextPageLinkHandle = await page.$x(xpath.searchResult.nextPageLink)
let nextPageLink = nextPageLinkHandle[0]
const nextPageItemHandle = await page.$x(xpath.searchResult.nextPageItem)
let nextPagerItem = nextPageItemHandle[0]
if(nextPageLink == null) {
if(nextPagerItem == null) {
break
} else {
// 最後のページャーの前に...があるとき
// 例:最後のページが37で、36ページにいるとき→ 35 36 ... 37
nextPageLink = await page.$(selector.restaurantDetail.lastPageLink)
}
}
await Promise.all([
page.waitForNavigation({waitUntil: "domcontentloaded"}),
nextPageLink.click()
])
}
BROWSER.close()
})()
/**
* 新しく開いたページを取得
* @param {page} page もともと開いていたページ
* @returns {page} 別タブで開いたページ
*/
async function getNewPage(page) {
const pageTarget = await page.target()
const newTarget = await BROWSER.waitForTarget(target => target.opener() === pageTarget)
const newPage = await newTarget.page()
await newPage.setViewport({
width : VIEWPORT.width,
height: VIEWPORT.height
})
await newPage.waitForSelector('body')
return newPage
}
/**
* 渡したデータをcsvに出力するメソッド。ページ数を渡すことで、ページごとに区別してcsvを出力できる。
* @param {Object.<string, string>} data csvに書き込まれるデータ。csvのヘッダと対応するkeyと、実際に書き込まれるvalueを持ったobjectになっている。
* @param {number} pageNumber 現在のページ数
*/
async function csvWrite(data, pageNumber) {
if (!fs.existsSync(OUTPUT_PATH)) {
fs.mkdirSync(OUTPUT_PATH)
}
var exec = require('child_process').exec
exec(`touch ${OUTPUT_PATH}/page${pageNumber}.csv`, function(err, stdout, stderr) {
if (err) { console.log(err) }
})
const csvfilepath = `${OUTPUT_PATH}/page${pageNumber}.csv`
const csvWriter = createObjectCsvWriter({
path: csvfilepath,
header: [
{id: 'id', title: 'No.'},
{id: 'name', title: '店舗名'},
{id: 'phone', title: '電話番号'},
{id: 'address', title: '住所'},
{id: 'holiday', title: '定休日'},
{id: 'genre', title: 'ジャンル'},
{id: 'chairs', title: '座席・設備'},
{id: 'hours', title: '営業時間'},
{id: 'url', title: 'URL'}
],
encoding:'utf8',
append :false,
})
csvWriter.writeRecords(data)
.then(() => {
console.log('...Done')
})
}
/**
* セレクターで指定した要素のテキストを取得できる。
* @param {page} page
* @param {string} paramSelector
* @returns {string} 改行と空白を取り除いた要素のテキスト。要素を取得できなかった時は空文字が返る。
*/
async function getTextBySelector(page, paramSelector) {
const element = await page.$(paramSelector)
let text = ""
if(element) {
text = await (await element.getProperty('textContent')).jsonValue()
text = text.replace(/[\s ]/g, "")
}
return text
}
/**
* XPathで指定した要素のテキストを取得できる。
* @param page
* @param {string} xpath 取得したい要素のxpath。
* @returns {string} 改行と空白を取り除いた要素のテキスト。要素を取得できなかった時は空文字が返る。
*/
async function getTextByXPath(page, xpath) {
const elements = await page.$x(xpath)
let text = ""
if(elements[0]) {
text = await (await elements[0].getProperty('textContent')).jsonValue()
text = text.replace(/[\s ]/g, "")
}
return text
}
async function getName(page, nameXpath, rubyXpath) {
let name = await getTextByXPath(page, nameXpath)
const nameRuby = await getTextByXPath(page, rubyXpath)
name += '(' + nameRuby + ')'
return name
}
function getTableInfoXPath(infoName) {
return `//dt[contains(text(), "${infoName}")]/following-sibling::dd`
}