機械学習を学んで何かをコードを作ってみよう、と思うときにネックになるのが学習用データと実行環境ですよね。何千件もあるデータを用意するのは大変ですし、初学者にとって高価なGPUを購入するのはハードルが高いです。
そこで機械学習のプラットフォームであるKaggleを利用し、チュートリアルでタイタニック生存者予測に取り組んでみます。
Kaggleにユーザ登録する
まずKaggleを開き、Registerボタンをクリックします。Googleアカウントでユーザ登録するか、メールからユーザ登録するか、お好きな方でどうぞ。
Kaggleは英語のみですので、DeepLなどで翻訳しながら進めると良いかもしれません。
コンペに参加する
ユーザ登録できたら、「Competitions」を開き、おそらく先頭に表示されているであろう「Titanic」を選んでください。次のURLから直接アクセスしてもOK。
https://www.kaggle.com/competitions/titanic
「Titanic」を開くと初めの方に「click on the "Join Competition button"」なんて書かれてますが、Join Competitionボタンは見当たりません。たぶんデザインが変わったんでしょうね、特に気にしないことにします。
Notebookを作る
さて、これで準備は整いました。
ここからは
- Kaggle Notebookでコードを書く
- タイタニックの生存者を予測する
- 予測データを投稿し、スコアをもらう
という流れになります。Kaggle Notebookとは、Kaggle上のJupyter Notebookのことです。ブラウザ上でPythonコードを書き、無料でGPUを使って解析できます。
「Code」->「+ New Notebook」を選択してください。すると、最初からInputとしてタイタニック用のデータがセットされた状態のNotebookが作成されます。便利ですね。
セットされているデータは
train.csv: 学習用のデータ
test.csv: 予測用のデータ
gender_submission.csv: 投稿する予測データのサンプル
となります。

コードを書く
さあ、いよいよ本題です。スターターページに沿って、タイタニックの生存者を予測するコードをNotebookに書いてみましょう。今回はお試しということで一部の過程は省略します。
学習用データのを読むこむ
まず、学習用データを読み込みます。
「+」ボタンで新しいセルを作り、「Code」になっていることを確認してください(「Markdown」だとメモを書けるだけで実行できません)。コードを書いたら、「▷」をクリックして実行です。うまく書けていたら、学習用データの一部が表示されます。IDの他に、生存したかどうか、等級(1等客室、2等客室…)、名前などが記載されていることがわかります。
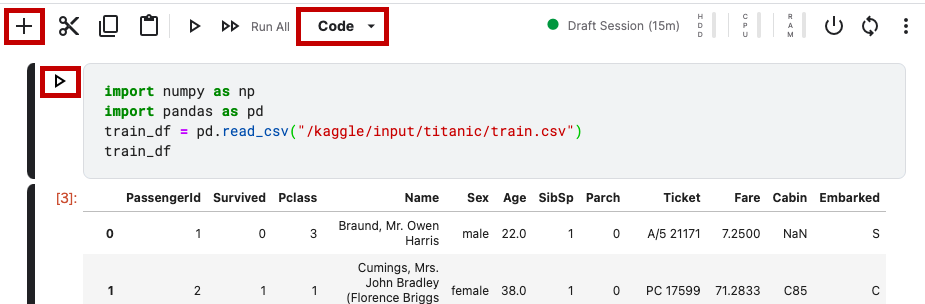
import numpy as np
import pandas as pd
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
train_df
項目リストを作る
解析に使う項目のリストを作成します。使わない項目は削除します。
input_features = list(train_df.columns)
input_features.remove("Ticket")
input_features.remove("PassengerId")
input_features.remove("Survived")
print(f"Input features: {input_features}")
TensorFlow用のデータセットに変換する
import tensorflow as tf
import tensorflow_decision_forests as tfdf
def tokenize_names(features, labels=None):
"""Divite the names into tokens. TF-DF can consume text tokens natively."""
features["Name"] = tf.strings.split(features["Name"])
return features, labels
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df,label="Survived").map(tokenize_names)
トレーニングを行う
GradientBoostedTreesモデルを使い、デフォルトパラメータでトレーニングを行います。
model = tfdf.keras.GradientBoostedTreesModel(
verbose=0, # Very few logs
features=[tfdf.keras.FeatureUsage(name=n) for n in input_features],
exclude_non_specified_features=True, # Only use the features in "features"
random_seed=1234,
)
model.fit(train_ds)
self_evaluation = model.make_inspector().evaluation()
print(f"Accuracy: {self_evaluation.accuracy} Loss:{self_evaluation.loss}")
予測用データで予測する
さてモデルができたので、いよいよ予測を行います。生成されたsubmission.csvをダウンロードします。
serving_df = pd.read_csv("/kaggle/input/titanic/test.csv")
serving_ds = tfdf.keras.pd_dataframe_to_tf_dataset(serving_df).map(tokenize_names)
def prediction_to_kaggle_format(model, threshold=0.5):
proba_survive = model.predict(serving_ds, verbose=0)[:,0]
return pd.DataFrame({
"PassengerId": serving_df["PassengerId"],
"Survived": (proba_survive >= threshold).astype(int)
})
def make_submission(kaggle_predictions):
path="/kaggle/working/submission.csv"
kaggle_predictions.to_csv(path, index=False)
print(f"Submission exported to {path}")
kaggle_predictions = prediction_to_kaggle_format(model)
make_submission(kaggle_predictions)
!head /kaggle/working/submission.csv
予測データを投稿し、スコアをもらう
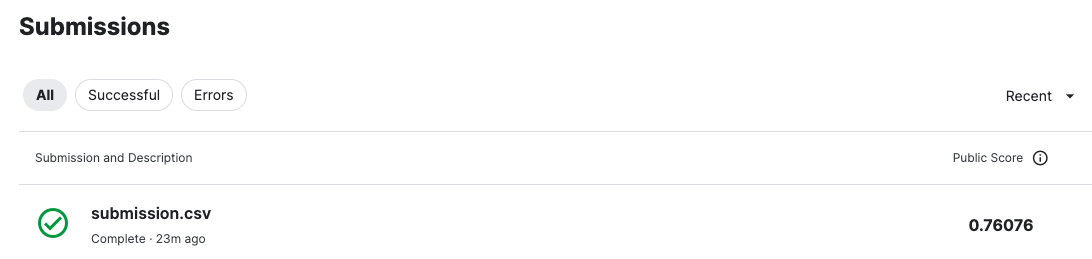
Notebookを離れ、Competitionsのページへ戻ってください。「Submit Prediction」ボタンを押し、先ほどダウンロードしたsubmission.csvを投稿します。しばらくすると、「Submissions」に今回のスコアが表示されます。

最後に
これでKaggleのコンペでの一通りの流れを体験できました。あとは他の人が保存したモデルを調べたり、自分のモデルを改良して再度投稿したり(1日10回まで投稿できます)、Discussionで質問してみたり(英語ですが)、他のコンペに参加するなどして、学習を進めてみてください。
それでは素敵なKaggleライフを!