機械学習で予測精度に大きな差をつけるために、探索的データ分析(Exploratory Data Analysis, EDA)が重要だと言われています。データの特性や構造を把握し、異常値や欠損値を特定し、データの分布や相関関係を理解する手助けになります。また、重要な特徴量を選択・生成することができるようになります。
具体的にどうやって探索的データ分析を行えばよいのか知りたくて、Kaggleのタイタニックをサンプルに試してみました。
データを観察する
データを読み込んで、ydata-profilingによる分析を行います。視覚的にデータ分析できるのでけっこう楽しいです。
import pandas as pd
import ydata_profiling as yf
df = pd.read_csv('../input/titanic/train.csv')
yf.ProfileReport(df)
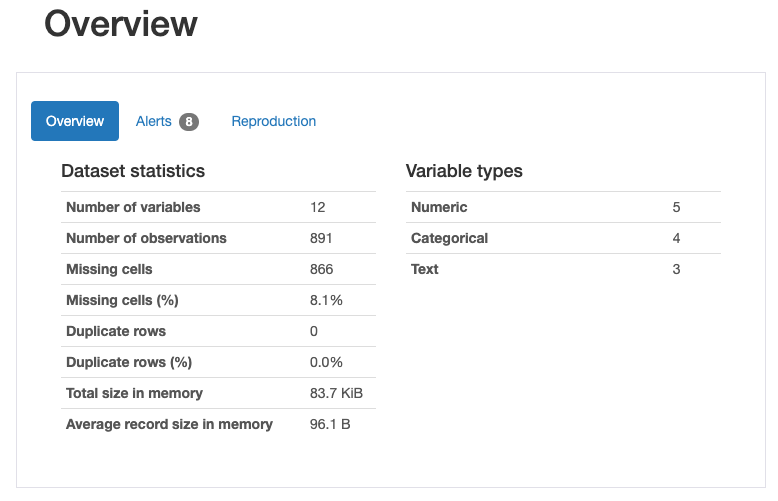
では1つ1つ見ていきましょう。まずは概要です。
12の特徴量があり、891行のデータがあることがわかります。そのうち欠損値は866です。12の特徴量のうち、量的変数が5、質的変数が4、テキストが3です。
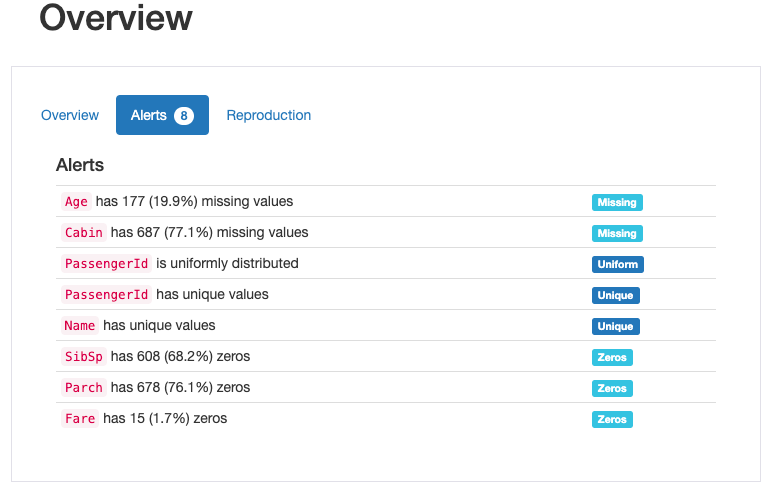
アラートタブを見ると、何かしらのデータ加工をしたほうが良さそうな特徴量がわかります。参考になりますね。
次にそれぞれの特徴量を観察してみましょう。
まず、PassengerId(乗客ID)(量的変数)は、完全に一意です。これはIDなので当然ですね。

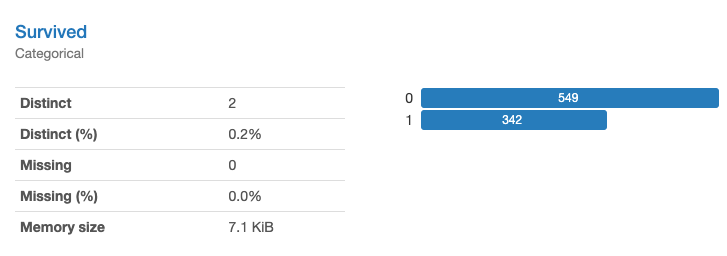
Servived(生存したか)(質的変数)は目的変数です。欠損値はありません。
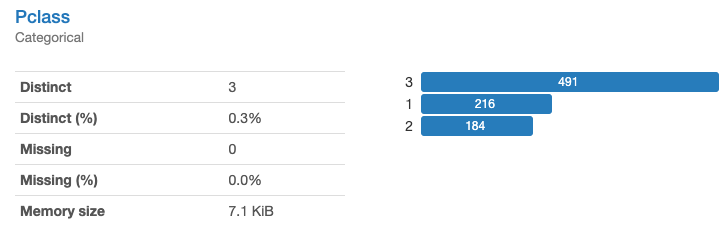
Pclass(チケットクラス)(質的変数)は1,2,3の数値で構成される特徴量です。欠損値はありません。
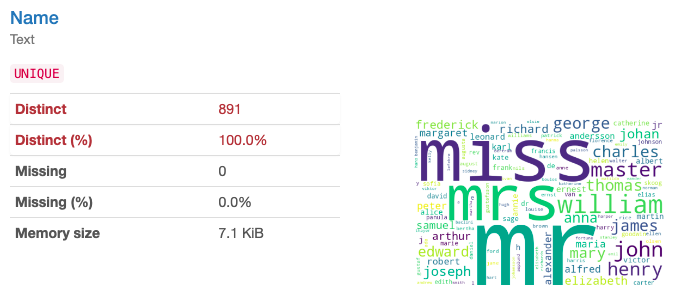
Name(氏名)(テキスト)は完全に一意な特徴量です。ですが、分析結果を見るとmrやmrsといったよく表れる単語があることがわかります。
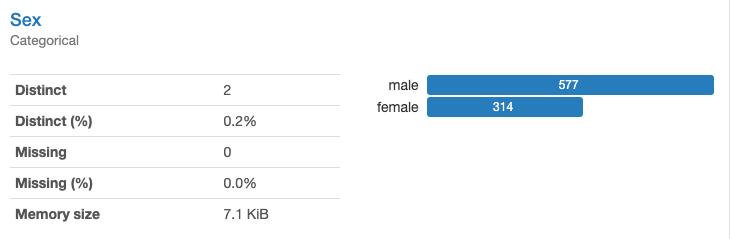
Sex(性別)(質的変数)はmale/femaleの2種類で構成されています。欠損値はありません。
Age(年齢)(量的変数)は0.42から80までの数値で構成されています。19%が欠損値です。

SibSb(同乗した兄弟・配偶者の数)(量的変数)は0~8の数値です。欠損値はありませんが、68%がゼロです。

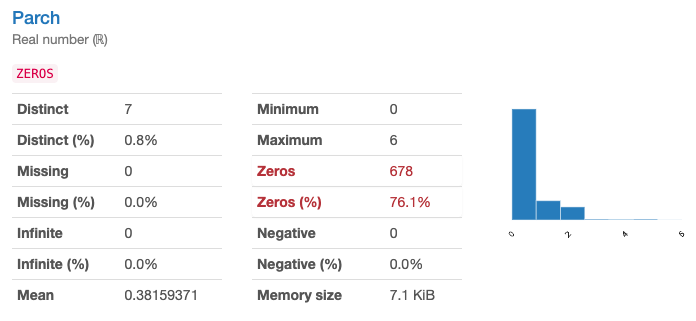
Parch(同乗した両親・子どもの数)(量的変数)は0~6の数値です。こちらも欠損値はありませんが、76%がゼロです。
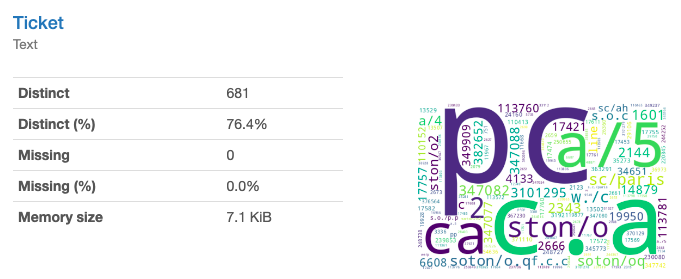
Ticket(チケット番号)(テキスト)。とりあえず「番号」と書きましたが文字列です。76%が一意です。
Fare(運賃)(量的変数) は0~512.3の数値です。
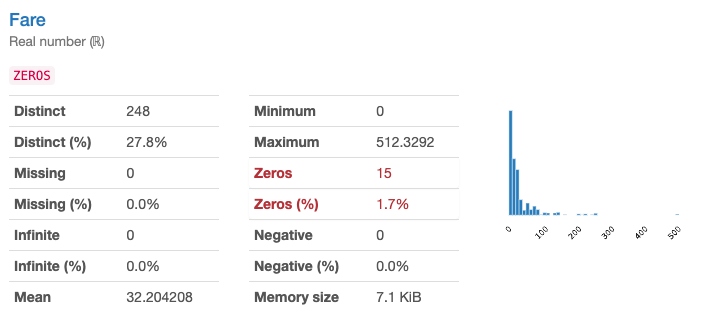
Cabin(旅客番号)(テキスト)は欠損率が77%もあります。
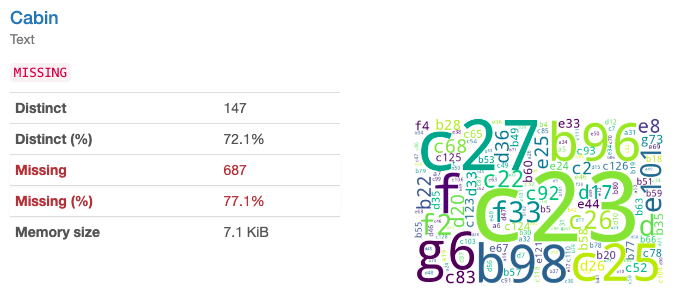
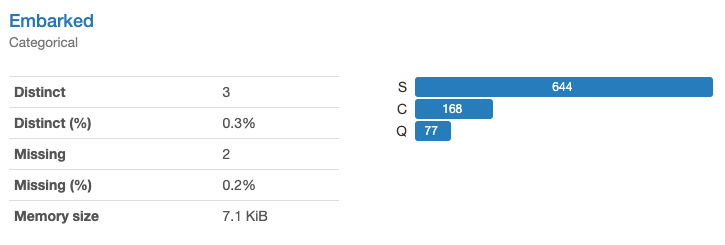
Embarked(出港地)(質的変数)は乗船した港を表す記号で、C:シェルブール、Q:クイーンズタウン、S:サザンプトンとなります。
データ観察のまとめ
各特徴量をまとめるとこうなります。
| variables | types | 特徴 |
|---|---|---|
| PassengerId(乗客ID) | 量的変数 | 完全に一意 |
| Servives(生存) | 質的変数 | 目的変数 |
| Pclass(チケットクラス) | 質的変数 | 1,2,3の数値 |
| Name(氏名) | テキスト | 完全に一意だが、mr、mrsなどの重複あり |
| Sex(性別) | 質的変数 | male/female |
| Age(年齢) | 量的変数 | 19%が欠損 |
| SibSp(同乗した兄弟・配偶者数) | 量的変数 | 68%がゼロ |
| Parch(同乗した両親・子供数) | 量的変数 | 76%がゼロ |
| Ticket(チケット番号) | テキスト | 76%が一意 |
| Fare(運賃) | 量的変数 | 0から512 |
| Cabin(旅客番号) | テキスト | 77%が欠損 |
| Embarked(出港地) | 質的変数 | C:シェルブール、Q:クイーンズタウン、S:サザンプトン |
データを可視化する
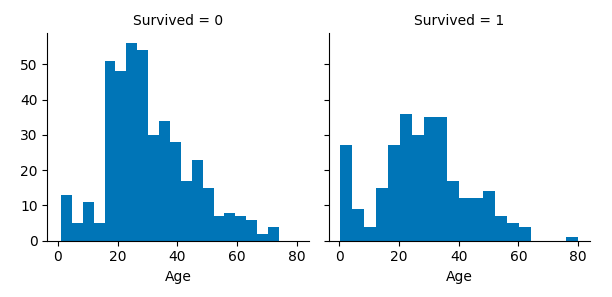
例として、年齢を生存別のヒストグラムで表示してみます。もし、両者が同じ傾向でしたら、年齢は生存率に影響がないかもしれません。年齢と生存率の相関関係を直感的に
把握するために、グラフは適しています。
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.FacetGrid(df, col='Survived')
g.map(plt.hist, 'Age', bins=20)
乳幼児は生存率が高そうです。また、20歳前後の人達は生存率が低そうに見えます。
データを加工する
予測の精度を上げたり、計算負荷を軽減するために、データを加工します。
不要な特徴量を削除する
重複値が多い特徴量としてTicketを、欠損値が多い特徴量としてCabinを削除します。
df = df.drop(['Ticket','Cabin'], axis=1)
df = df.drop(['Ticket','Cabin'], axis=1)
欠損値を補完する
Emberkedの欠損値を最頻値で補完します。
freq_embarked = df.Embarked.dropna().mode()[0]
df['Embarked'] = df['Embarked'].fillna(freq_embarked)
Ageの欠損値を平均値で補完します。
mid_age = df.Age.dropna().median()
df['Age'] = df['Age'].fillna(mid_age)
新しい特徴量を作る
NameはPasssengerIdと同じく完全に一意ですが、部分的に重複度が高い点に注目します。どうやら「Mr.」などの敬称(Title)が生存率に影響ありそうです。そこでTitleを特徴量として抽出します。類似の敬称をまとめ、頻度が低いものは「Rare」としてひとまとめにします。抽出が終わったら、Nameは削除します。
df['Title'] = df.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
df['Title'] = df['Title'].replace('Mlle', 'Miss')
df['Title'] = df['Title'].replace('Ms', 'Miss')
df['Title'] = df['Title'].replace('Mme', 'Mrs')
df['Title'] = df['Title'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
df = df.drop(['Name'], axis=1)
特徴量を組み合わせる
SibSpは同乗した兄弟・配偶者の数で、Parchは同乗した両親と子どもの数です。これらの特徴量を同乗した家族(FamilySize)にまとめます。さらに単独の搭乗者であることを示すIsAloneという特徴量を新たに作ります。まとめ終わったら、SibSpとParchは削除します。
df['FamilySize'] = df['SibSp'] + df['Parch'] + 1
df['IsAlone'] = 0
df.loc[df['FamilySize']==1, 'IsAlone'] = 1
df = df.drop(['SibSp','Parch'], axis=1)
質的変数を量的変数に変換する
アルゴリズムで解析しやすいよう、文字列が設定されている質的変数の特徴量を数値に置き換えます。Sex, Emberked, Titleが対象です。また、Titleの欠損値は0で補完します。
df['Sex'] = df['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
df['Embarked'] = df['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
df['Title'] = df['Title'].map(title_mapping)
df['Title'] = df['Title'].fillna(0)
おわりに
これでだいぶ解析しやすいデータになったと思います。 他にもその特徴量の性質に合わせてデータとまとめたり、結合したり、やり方は様々あるようです。
これを基本として、今後も様々なデータ探索を参考にしたいと思います。
今回の記事を作成するために使用したkaggle notebookはこちらです。
https://www.kaggle.com/code/kysd2023/exploratorydataanalysislearningfromtitanic