機械学習における時系列データの予測方法を学習したので、備忘録としてまとめます。かなりシンプルな方法だと思いますが、時系列データ処理の入門的な位置付けだと考えています。解析環境はGoogle Colaboratory(Colab)を使いました。
対象は株価です。今回の目的は「翌日の終値が当日の終値より上がるか下がるか」を予測します。
時系列データを取得する
時系列データとして米Amazonの株価を使います。株価データはyfinanceで取得します。yfinanceは株価以外にも様々な金融系のデータを取得できるすごいライブラリだと思います。Colabにはyfinanceが入っていないのでインストールから始めます。
!pip install yfinance
上場から2023年末までを訓練データ、2024/01/01〜2024/03/31を評価データとしてデータを取得します。
# データダウンロード
import yfinance as yf
df_train=yf.download("AMZN", end="2023-12-31", interval = "1d")
df_test=yf.download("AMZN", start="2024-01-01", end="2024-03-31", interval = "1d")
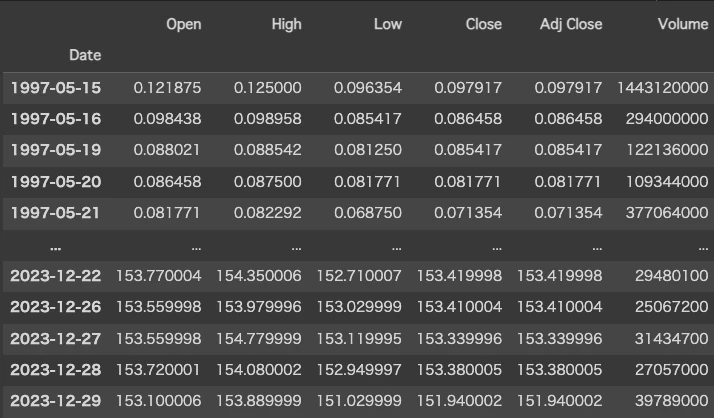
df_train
このように始値(Open)、高値(High)、安値(Low)、終値(Close),出来高(Volume)が1日ごとに取得できました。調整後終値(Adj Close)も取得されますが、今回は使いません。
どんなデータかグラフで見てみましょう。ついでに今後使うライブラリもインポートしておきます。
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
df_train["Close"].plot()
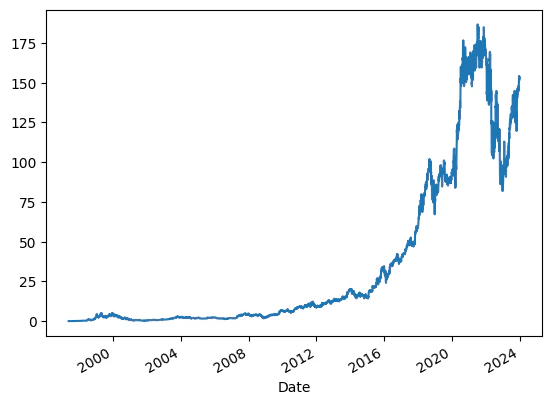
上場当初と最高値の差が激しいですね。現在は100$を超えていますが、上場当初は0.1$以下だったようです。このままだと解析しにくいので、あとで差分データに変換します。
目的変数を作る
今回の目的は、翌日の終値が上がるか下がるかです。pandasで終値の差分を取得し、1日ずらします。この列を「Up」とします。
# 目的変数生成
df_train = pd.concat([df_train, df_train["Close"].diff(1).shift(-1).rename("Up")], axis=1)
これを上がったら1、下がったら0、に変換します。
for i, row in df_train.iterrows():
if row["Up"] > 0 :
df_train.at[i, "Up"] = 1
else :
df_train.at[i, "Up"] = 0
差分データを作る
前日データとの差分を作成します。1日前の差分データ、2日前の差分データ・・・5日前の差分データを列として追加します。
始値、高値、安値、終値、出来高の全てに対して5日分の差分データを生成するので、これを関数にします。
# 差分データを作る
def add_diff(df, col):
return pd.concat([df, df[col].diff(1).rename(col+"_diff1"),
df[col].diff(1).shift(1).rename(col+"_diff2"),
df[col].diff(1).shift(2).rename(col+"_diff3"),
df[col].diff(1).shift(3).rename(col+"_diff4"),
df[col].diff(1).shift(4).rename(col+"_diff5")],
axis=1)
df_train = add_diff(df_train, "Open")
df_train = add_diff(df_train, "High")
df_train = add_diff(df_train, "Low")
df_train = add_diff(df_train, "Close")
df_train = add_diff(df_train, "Volume")
不要な列は訓練の妨げになるので削除します。
cols = ["Open","High","Low","Close","Volume","Adj Close"]
df_train = df_train.drop(cols,axis=1)
評価データも同様に差分を作ります。
df_test = add_diff(df_test, "Open")
df_test = add_diff(df_test, "High")
df_test = add_diff(df_test, "Low")
df_test = add_diff(df_test, "Close")
df_test = add_diff(df_test, "Volume")
df_test = df_test.drop(cols,axis=1)
モデルを作って予測する
過学習を避けるため、訓練データから検証データを分離します。
# 訓練データから検証データを分ける
df_train2, df_val = train_test_split(df_train, test_size=0.2)
LightGBMでモデルを作ります。
# モデル構築
goal = "Up"
train_y = df_train2[goal]
train_x = df_train2.drop(goal, axis=1)
val_y = df_val[goal]
val_x = df_val.drop(goal,axis=1)
trains = lgb.Dataset(train_x, train_y)
valids = lgb.Dataset(val_x, val_y)
params= {"objective": "binary",
"metric" : "binary_logloss"}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=1000, callbacks=[lgb.early_stopping(stopping_rounds=100)])
次の予測します。結果は確率なので、しきい値を0.5として上がったか下がったかに分類します。
# 予測
predict = model.predict(df_test)
thresh_hold = 0.5
predict_list = []
for i in predict :
if i >= thresh_hold :
Up = 1
else :
Up = 0
predict_list.append(Up)
予測結果を元のデータセットと結合します。
df_pre = pd.Series(predict_list).rename("Up")
df_pre.index = df_test.index
df_predict = pd.concat([df_test, df_pre], axis=1)
まとめ
では予測結果を評価してみましょう。
df_t = pd.concat([df_predict["Up"], df_predict["Open_diff1"].shift(-1)], axis=1)
cnt = 0
for i, row in df_t.iterrows():
if(row["Up"] > 0 and row["Open_diff1"] > 0) :
cnt+=1
if(row["Up"] <= 0 and row["Open_diff1"] <= 0) :
cnt+=1
cnt/len(df_t)
# => 0.6229508196721312
シンプルな手法でしたが、正答率62%というのはまずまずじゃないでしょうか。以下やってみた感想です。
- 時系列データとはいえ、使うモデルはよく見かけるもので良さそう
- 始値とか高値とか使ってるけど、相関係数高いのでは
- 出来高関係ないのではと思って試しに外してみたところ、正答率54%まで落ちてしまい影響大きかった
- 差分でいいのか、比率のほうがよいか、5日分は適切なのか
- 他にも影響あるデータはいろいろあるはず
- Qiitaのなかにも時系列データの予測について予測手法の解説をやっている記事があるので、理解できるようになりたい
ここまで読んでいただき、ありがとうございました。初心者なので次に学習したほうが良さそうな記事や本があればコメントで教えてください。