自宅PC環境で、scikit-learnのDecisionTreeClassfierで決定木を可視化するまでにやったことを記載します。
前提
OS:Windows 10 Home Edition
Anaconda 3.7導入済み。
導入手順
- graphvizのインストール
- "conda install graphviz"を実行する。
- 環境変数PATHに"Anacondaインストールフォルダ\Library\bin\graphviz"を追加する。
- pydotplusのインストール
- "conda install pydotplus"を実行する。
- python-graphvizのインストール
- "conda install python-graphviz"を実行する。
それぞれ、conda installコマンドが異常終了していないことを確認する。
方法としては、
・conda installコマンド実行中にエラーメッセージが出てないことを目視で確認する。
・"echo %ERRORLEVEL%"の実行結果が0であることを確認する。
・"conda list パッケージ名"を実行して、インストール対象としたパッケージの名前が出力されることを確認する。
といったやり方があるかと思います。
サンプル
サンプルコード
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import pydotplus
df = pd.read_csv( 'D:/python/testdata.csv' )
src = df.drop( 'C', axis='columns' )
trgt = df['C']
clf = DecisionTreeClassifier( random_state = 0 )
clf.fit( src, trgt )
dot_data = export_graphviz(clf,
feature_names=src.columns,
class_names=['T','F'],
filled=True,
rounded=True)
graph = pydotplus.graph_from_dot_data( dot_data )
graph.write_png( 'D:/python/tree.png' )
テストデータ(testdata.csv)
A,B,C
-4,-8,T
-9,7,F
-1,3,F
2,1,T
5,-1,T
10,5,T
-8,-6,F
-9,-2,F
-8,-2,F
3,1,T
5,-6,T
4,-7,T
9,9,F
9,5,T
-5,6,F
5,9,F
9,3,T
2,-5,T
8,10,F
0,-6,T
※A>Bの場合にC='T'、A<Bの場合にC='F'となるように作ったデータです。
結果グラフ

ちなみに、ここまでの環境構築内容だと、カラム名を日本語にした場合に文字化けします。
上記の例で、A⇒説明変数1、B⇒説明変数2、C⇒目的変数として同様の処理を実行させた結果は以下の通りです。

グラフ内で日本語を表示させるには…?
※scikit-learnをアップデートしたら元に戻ってしまいそうな方法ですが…。
『"Anacondaインストールフォルダ\pkgs\scikit-learn-0.21.2-py37h6288b17_0\Lib\site-packages\sklearn\tree\export.py"内でハードコーディングされているフォント名を変更する』という方法が使えます。
headメソッド内に以下の記述が2ヶ所あります。
「fontname=helvetica」
この、fontname=で指定されているフォント名を日本語フォント名に変更すればうまくいきます。
以下のグラフは、fontname=Meiryoに変更した上でグラフ作成した結果です。
上のグラフでは文字化けしていた部分が、正しく表示されています。
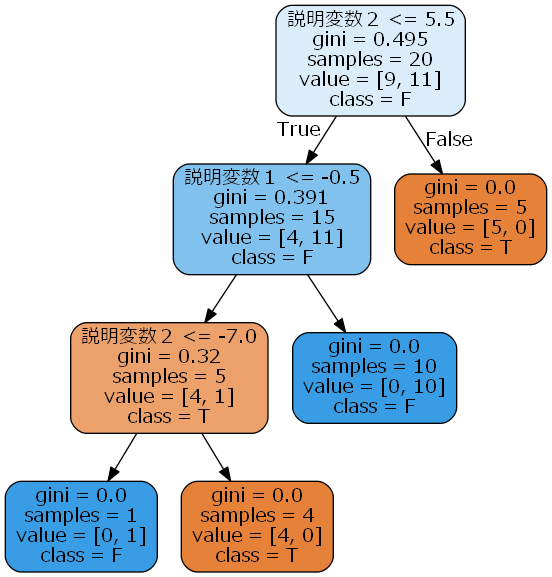
ただ、このやり方だとフォント名に空白が含まれるとダメで、例えばfontname=Meiryo UIとすると処理が異常終了します。
参考サイト
・Python3でscikit-learnの決定木を日本語フォントで画像出力する方法のまとめ
・Graphvizのコマンドで日本語が文字化けして困った(windows10)
関連リンク
・graphviz公式サイト
https://www.graphviz.org/
・pydotplus公式サイト
https://pypi.org/project/pydotplus/