API良いですよね。フロントとサーバーサイドが分業できる点が特に好きです。
この記事はそのAPIをRailsで作ってみようというものです。APIを作る際の選択肢が幾つかありますが、この記事ではRails::APIを使用します。
前半はVagrantを使った環境構築編、後半はRailsのコードを編集していくコーディング編、という二本立てになっています。
記事がかなり長くなってしまったのですが、良ければお試しあれ(^o^)
この記事で出来上がる成果物
今回はcompanies(企業)とemployees(従業員)というモデルを作成し、それぞれに対して登録/参照/更新/削除の操作ができるAPIサーバーが最終的な成果物となります。
この記事で触れること
- Vagrantを使った最低限の仮想開発環境の構築方法
- Ruby、Rails、PostgreSQLなどのミドルウェアのセットアップ方法
- 最低限の、APIで必要な各種ファイルの役割や編集方法
- APIを使ってリソース(DB内のレコード)を操作する方法
- Rspecの最低限の書き方
などなど。ザックリいうと上記のような感じです。
対象読者
- APIの開発に興味のある方
- プログラミング初学者
経験の浅いWeb系エンジニアにとってRailsを使ったAPIの開発は、爆速で成長できるので非常におすすめと他の方の記事でも紹介されていたので、独学で勉強している方など良いのではないでしょうか。
新人教育の教材に使ってもらえるとものすごく嬉しいです。
筆者について
筆者の技術力ってどんなもんやねんと気になるかと思うので軽く経歴などを自己紹介させていただくと、静的サイトの制作を三年くらい、そのあとの二年ぐらいはRailsで一つの同じ案件をずっとやっていました。
ベテランであるとか、OSSのコミッターとかではないです。
教育に興味があり、それが影響したのかこういう記事を書いてみた次第です。
用語
読み飛ばしてもいい。後から分からなくなった時に読み返すでも良い。
必要無いやつも混ざってますが、気にしないでください。
See the Pen oEVZJm by k.shimoji (@kshimoji) on CodePen.
あると良いもの
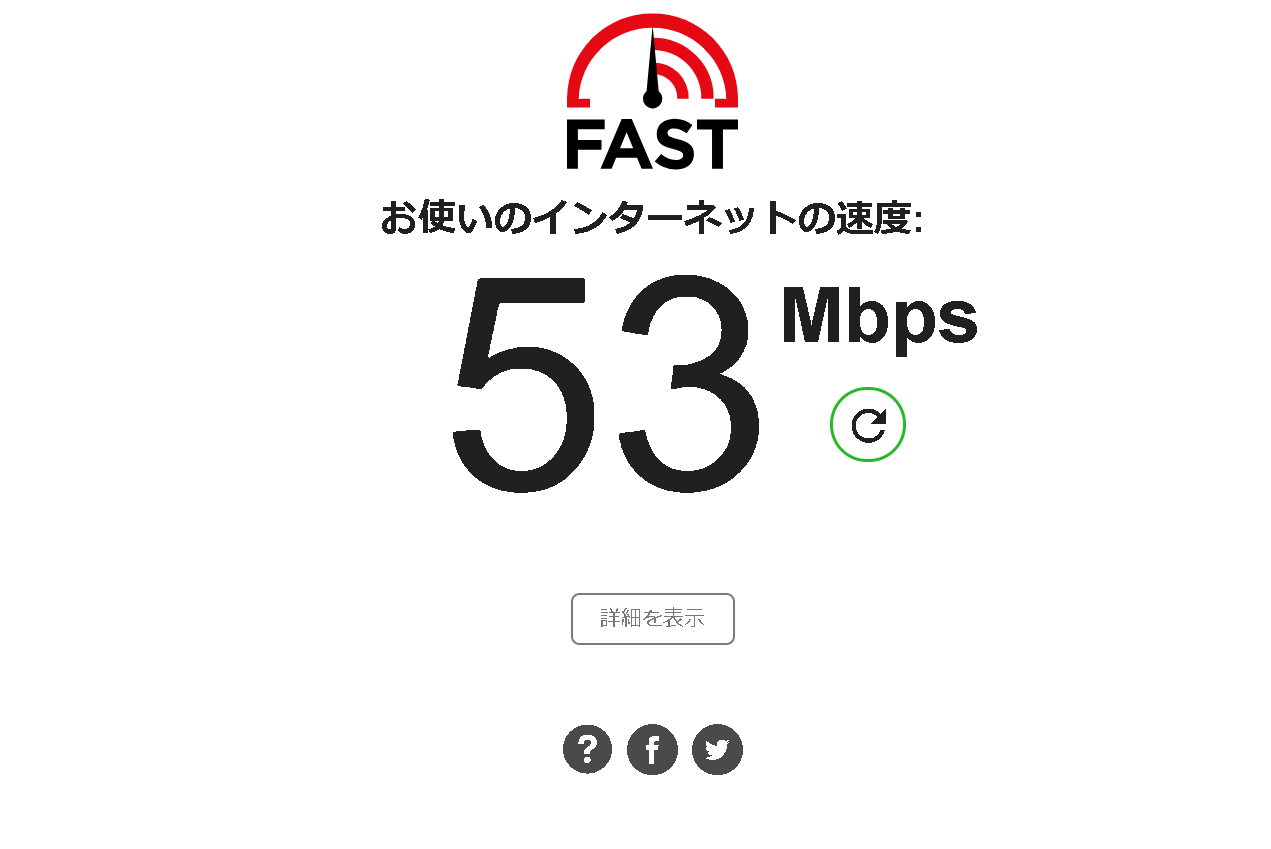
そこそこの速度が出る回線
色々なものをダウンロードするので細い回線(カフェのWIFIなど)では辛みがあります。そこそこスピードの出る環境を用意してください。
自分の環境は53Mbpsで十分でした。
 |
|---|
ちなみにこのサービス、NETFLIXがやってるみたいです。
SSDのPC
HDDだと書き込みに時間がかかるため、トライアンドエラーを行うのは辛みがあります。これは必須ではないのですが、経験上あった方が良いと思います。
その他
- 私の環境ではWindowsなのでこの記事もWindowsを前提にして書いています。ただ、仮想マシンを建てて以降の手順についてWinもMacも同じはずですので、Macの方もぜひご参考にして試して頂けたらと思います
- あくまで入門用なので、特にセキュリティの面で実際の業務とはかけ離れた設定をして進めているのでその点は意識してください
- ファイルを編集する手順に出てくるコードブロックに関しては極力ファイルパスを表示させるようにしているので、どのファイルを編集したらいいのかわからなくなった場合などに参考にしてください
- ファイルの編集にはvscodeを使用していますがどのエディタでも問題無いです
- 区切りの良いところで記事の内容を振り返って、よくわからなった単語などは用語集を参照してもらうかggったり質問したりして調べてみてください。記憶が新鮮なうちに結び付けておくことをお勧めします
- 途中疲れて失速気味なので間違いや不足している点やわかりにくい点があるかもしれません。指摘いただけると助かります
- 主にcygwinやvagrantなどのホストマシン側の設定についてなのですが、この記事を書いている時点で既に私の環境にインストールされて設定されていたものが殆どですので、もしかすると真っ新な環境での構築とは異なる解説をしてしまっている可能性があります。その点もご指摘いただけると助かります
- てにをはの修正依頼も歓迎です
環境構築編
ゴールの設定
環境構築ではrailsアプリのデフォルトのHello Worldが見えることをゴールにします。
では早速始めていきます。
cygwinをインストール
今後、後述するVagrantなどの操作をするためにcygwinが必要になります。
無くてもコマンドプロンプトなどで出来るのですが、初学者がlinuxコマンドとWindowsコマンドを両方覚えるのは混乱するのでcygwinに絞りました。
Macの場合はこの手順は不要かもしれません。Mac使ったことないのでよくわからず。
下記のサイトからインストーラーをダウンロードします。赤線のところをクリック
 |
|---|
ダウンロードしたインストーラーを起動し、下記画像のところまでは「次へ」を選択で問題ないはず。

xxxxx.jpのようなjpドメインのURLを選択してください。ネットワークの速度的に、日本国内のサーバーの方が速いとのことです。外国のサーバーを選択してしまうと遅いらしいです。(画像の中で選択しているのは山形大学なのかな?)
そのあとも「次へ」を選択します。特に難しいことは無いはずです。
起動確認
こんな感じで起動できれば成功です。
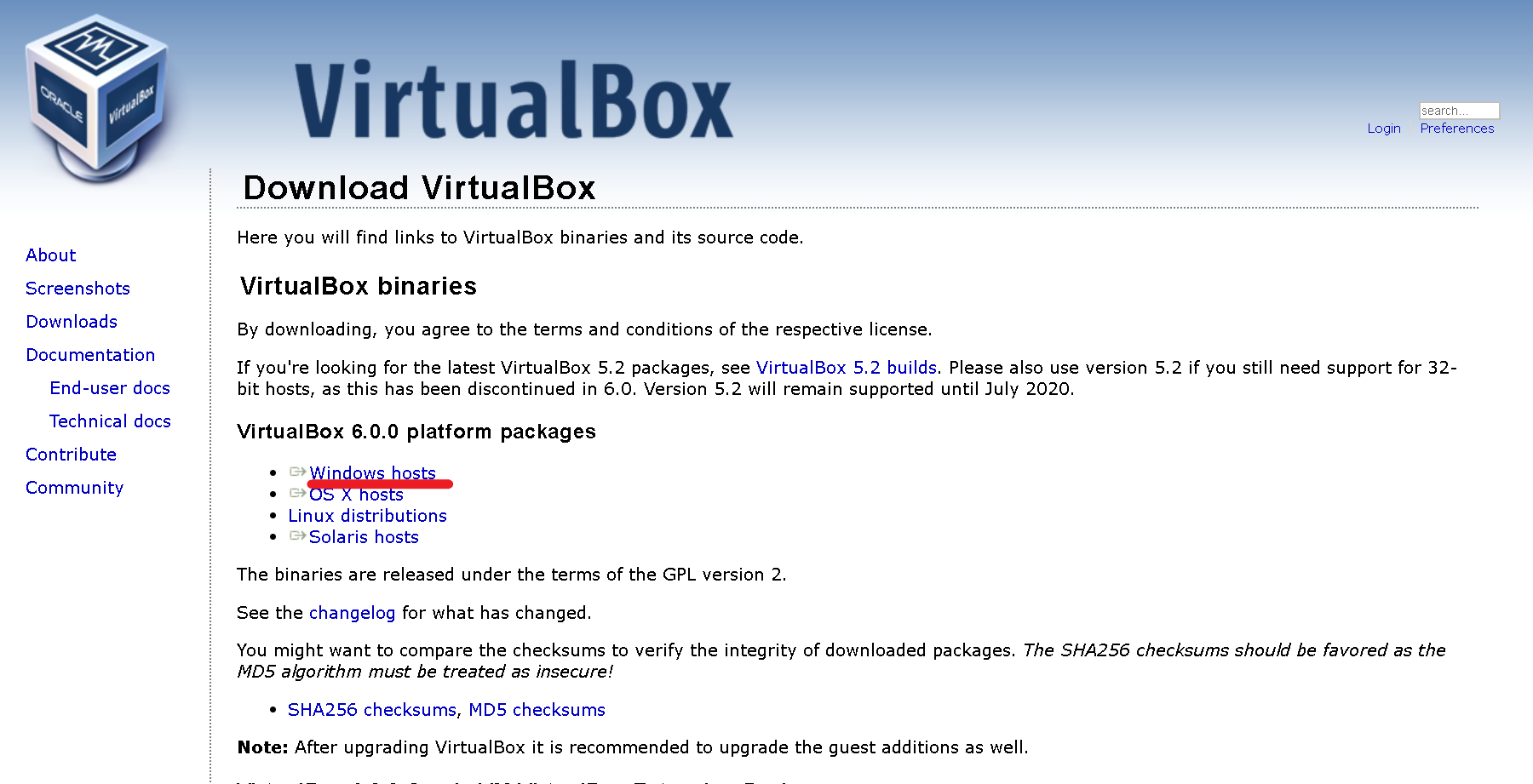
virtualboxをインストール
公式ページからVirtualBoxのインストーラをダウンロードします。デカデカと出ているボタンを押します。
https://www.virtualbox.org/
 |
|---|
Windowsの人は赤線のところをクリック
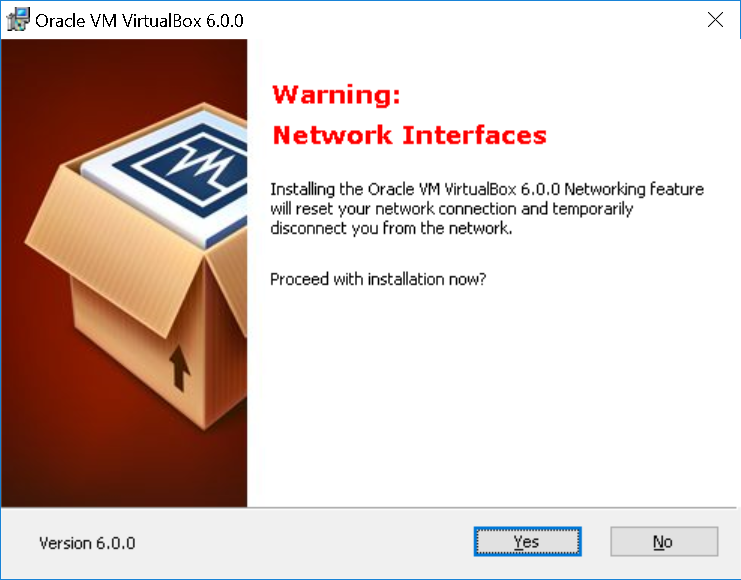
 |
|---|
ネットワークがリセット(切断?)されるけど良いか?と聞かれているっぽい。他にダウンロードしているものなどが無ければYesを選択。
 |
|---|
インストールが完了したら起動してみます。下記の画像では色々なマシンが左に並んでいますが、最初は何もないはずです。なので画像と同じでなくても問題無いです。
 |
|---|
vagrantをインストール
下記のVagrant公式サイトからインストーラーをダウンロード。赤線のところです。
 |
|---|
自分のOSにあったやつをダウンロード
 |
|---|
Nextを選択して進めていきます。
スクショを取り忘れたのですが、インストールが完了するとPCの再起動を聞かれます。次のステップに進む前に必ず再起動をしてください。
再起動後、cygwinからvagrantのインストールの確認をしてみます。
$ vagrant --version
Vagrant 2.2.2
vagrantのpluginのupdateを行います。自分の場合は下記のようになりました。vagrant-vbguestというプラグインがupdateされたようですが、これは人によって異なると思います。
ただ、updateをしておかないとvirtualboxとうまく連携出来ない可能性があるので、必ずupdateしておきます。
$ vagrant plugin update
Updating installed plugins...
Updated 'vagrant-vbguest' to version '0.17.1'!
box(仮想マシン)を追加する
Vagrantのbox(仮想マシン)を追加するためのディレクトリを作成します。名前は何でも良いのかどうかよくわからないのでとりあえずVagrantにします。
cd /cygdrive/c/ ←Cディレクトリ(Cドライブ直下に移動)
mkdir Vagrant ←Vagrantディレクトリを作成
更にVagrantディレクトリの中に今回の目的用のBox(仮想マシン)を設置する用のディレクトリを作成します。Vagrantディレクトリは色々なBox(仮想マシン)が共通して使う場所なので、その中にそれぞれ専用のディレクトリを作ってあげるイメージです。
$ cd Vagrant
$ mkdir rails_api
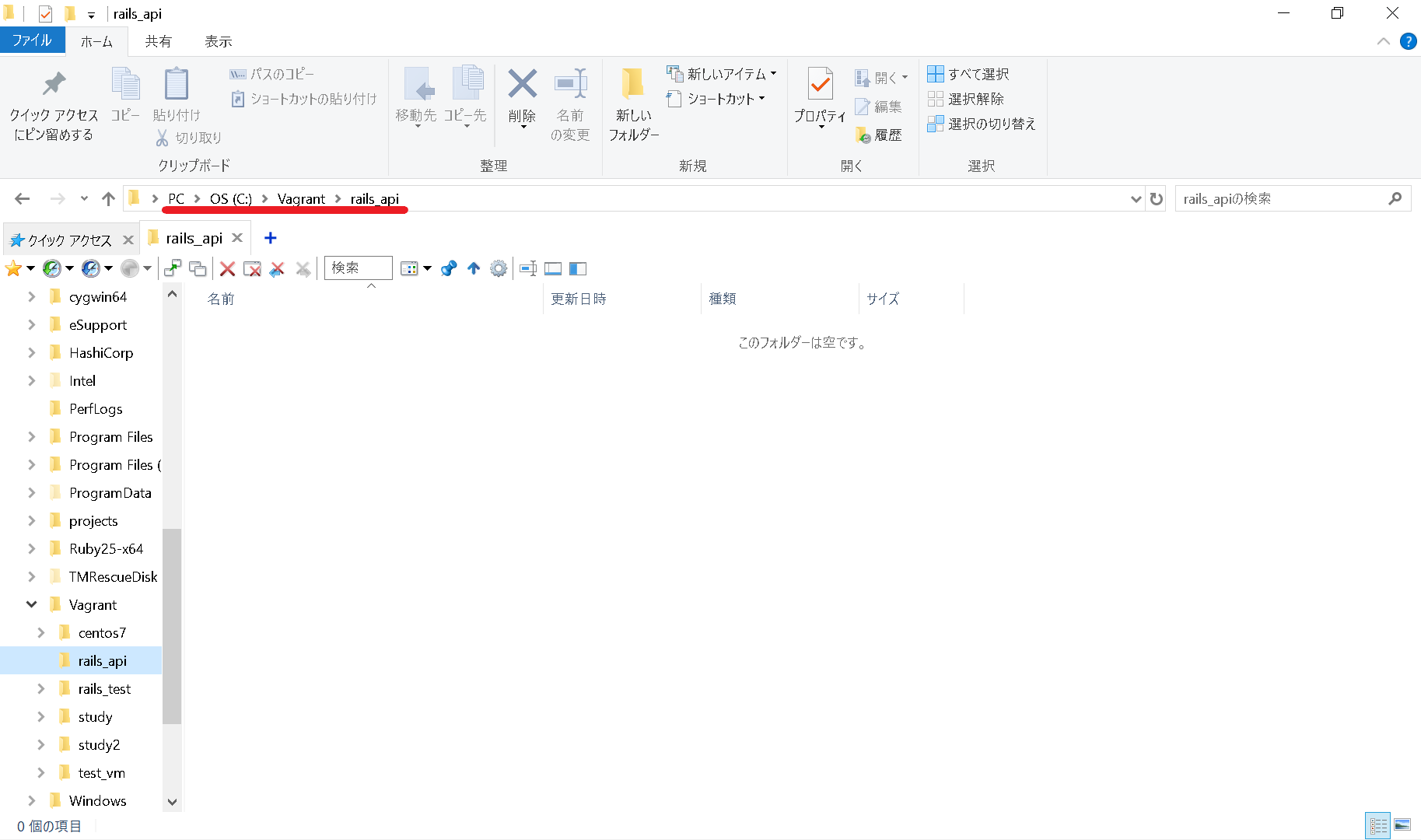
Windowsのエクスプローラーで見るとこんなディレクトリ構造になっているはずです。
 |
|---|
下記のHashicorp(Vagrantを作っている企業)が運営している公式のBox(仮想マシン)配布サイトから、今回作成する仮想マシンを探します。
CentOS7の仮想マシンを作成しますが、CentOS7と言っても色んな人あるいは組織がCentOS7のBox(仮想マシン)をアップしています。
それぞれCentOS7の中にインストールしているパッケージなどが異なっています(例えば、同じCentOS7であってもGUIがあったり無かったりなど)。
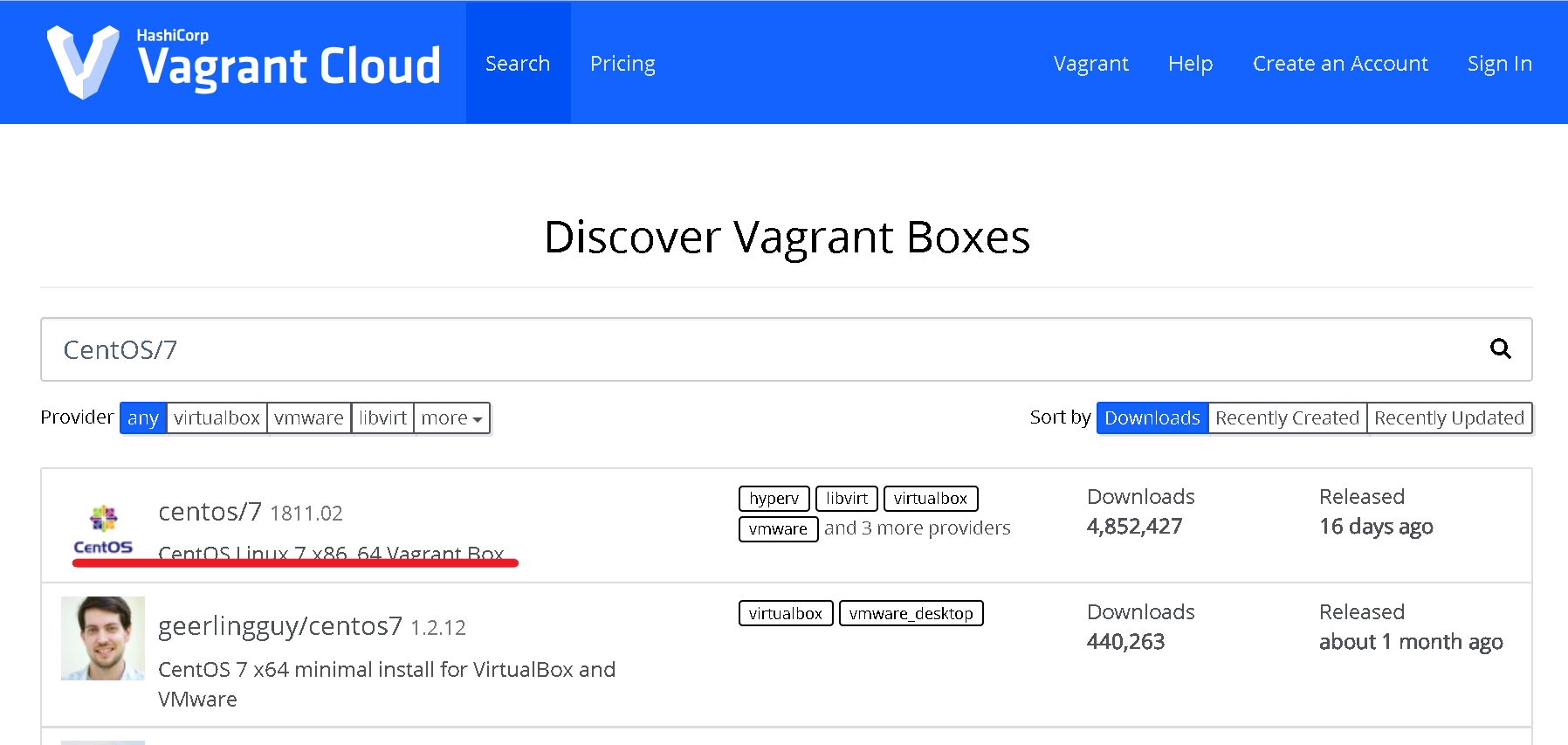
検索窓にCentOS/7と入れて検索します。CentOS7ではなく、CentOS/7です。
注意です。
一番上の赤線のものがCentOSの公式Vagrant Boxです。クリックします。
 |
|---|
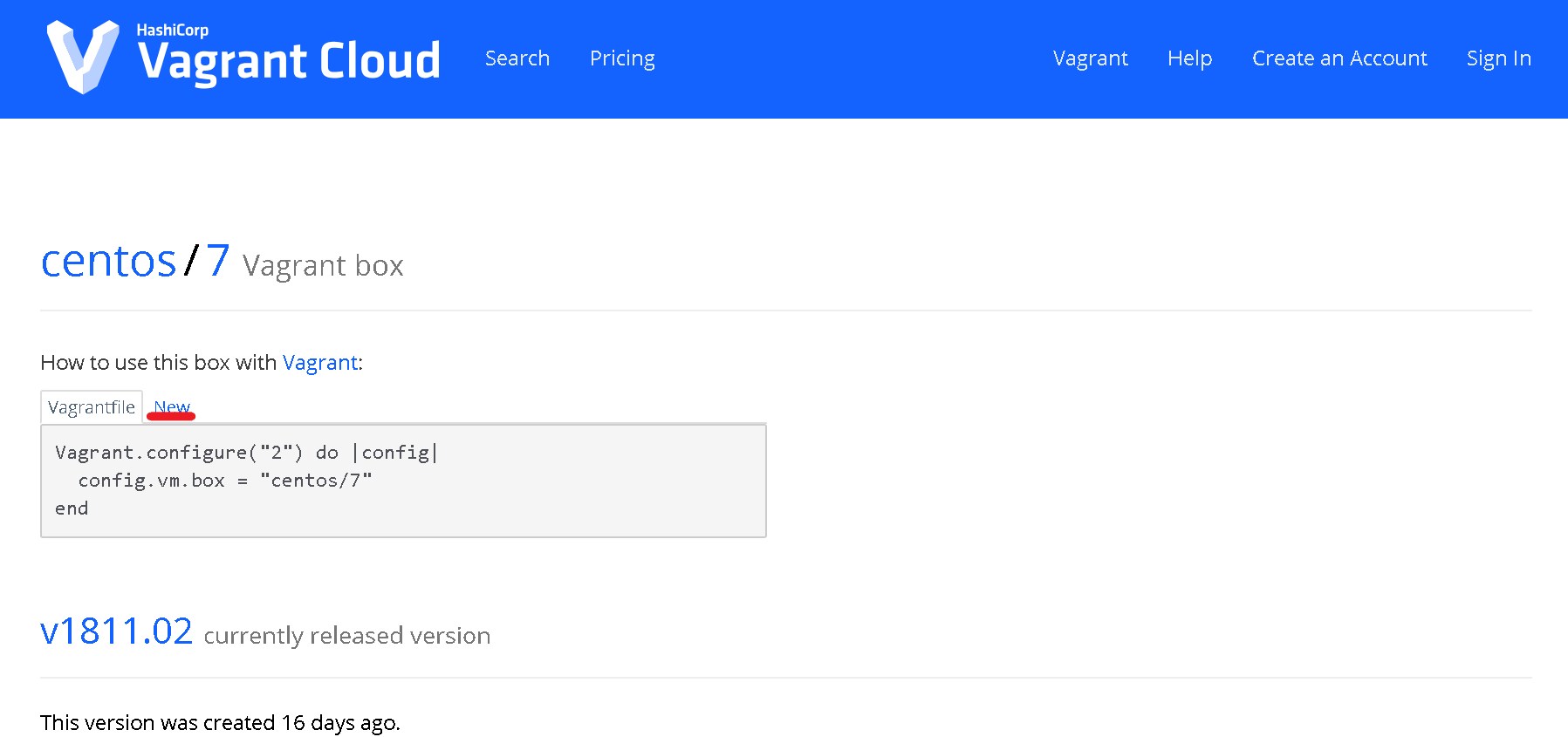
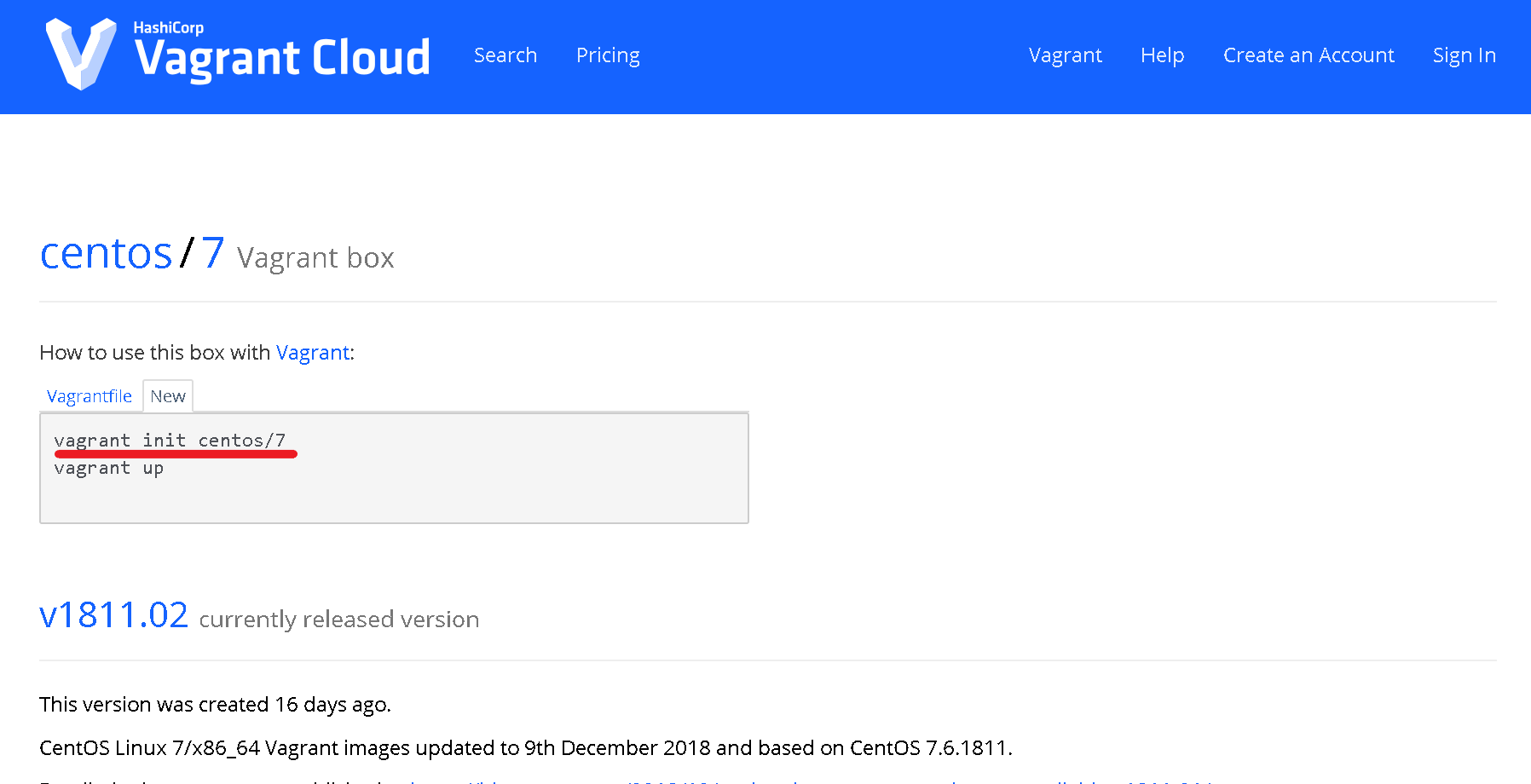
Newと書かれたタブをクリックします。
 |
|---|
赤線の部分がCentOS7のBoxを追加するための前準備用のコマンドです。
vagrant init centos/7
今回はCentOS公式Boxを使いますが、他のBoxを入れたくなった場合は同じ要領でBoxを探してください。
 |
|---|
cygwinに戻って、先ほどのコマンドを実行します。重要なのは、ちゃんと今回用に作成したディレクトリに移動してからコマンドを打つという事です。
$ cd /cygdrive/c/Vagrant/rails_api/
$ vagrant init centos/7
A `Vagrantfile` has been placed in this directory. You are now
ready to `vagrant up` your first virtual environment! Please read
the comments in the Vagrantfile as well as documentation on
`vagrantup.com` for more information on using Vagrant.
Vagrantファイルが作成されようです。確認してみます。
$ ls -l
合計 4
-rwxrwxr-x+ 1 shimoji なし 3085 12月 28 20:00 Vagrantfile
この状態でvagrant upコマンドを実行すると仮想マシンが作成される&仮想マシンが起動します。
2回目以降は既に仮想マシンが作成されている状態なので、作成はスキップされて起動するだけです。
$ vagrant up
自分の場合下記のようなerrorが出ました。kernel-develをインストールしてねみたいに言われている気がします。とりあえず起動には成功したようなので、後で仮想マシンに入ってからkernel-develをインストールすることにします。
Error getting repository data for C7.6.1810-base, repository not found
==> default: Checking for guest additions in VM...
default: No guest additions were detected on the base box for this VM! Guest
default: additions are required for forwarded ports, shared folders, host only
default: networking, and more. If SSH fails on this machine, please install
default: the guest additions and repackage the box to continue.
default:
default: This is not an error message; everything may continue to work properly,
default: in which case you may ignore this message.
The following SSH command responded with a non-zero exit status.
Vagrant assumes that this means the command failed!
yum install -y kernel-devel-`uname -r` --enablerepo=C7.6.1810-base --enablerepo=C7.6.1810-updates
Stdout from the command:
Loaded plugins: fastestmirror
Stderr from the command:
Error getting repository data for C7.6.1810-base, repository not found
仮想マシンにログイン
$ vagrant ssh
[vagrant@localhost ~]$ ←入れました
rootユーザーにスイッチ
今後はほぼ全ての作業をrootユーザーで行いますので、仮想マシンにログインしなおしたりした際は必ずrootユーザーにスイッチしてください。
[vagrant@localhost ~]$ sudo su - root
[root@localhost ~]# ←rootユーザーに切り替わった
仮想マシンのプラグインをアップデート&インストール
最新のCentOS/7のBoxを使用してはいますが、中のパッケージは最新ではないものもあるためアップデートして最新化します。393個出てきました。気長に終わるのを待ちます。
[root@localhost ~]# yum -y update
先ほどvagrant up時のerrorで指摘されていたkernel-develを入れておきます。調べてみると、これが無いとホストマシンと仮想マシンのディレクトリをマウントすることが出来ないみたいな記事が出てきたので(詳しくは調べていません)、入れておいた方が良いのでしょうね。
[root@localhost ~]# yum -y install kernel-devel
念のためもう一度updateコマンドを打ちます。kernel-develを入れた事によりupdate出来るものが出てきたりしてないかと思いましたが、特にありませんでした。
[root@localhost ~]# yum -y update
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: ftp.riken.jp
* extras: ftp.riken.jp
* updates: ftp.riken.jp
No packages marked for update
仮想マシンを再起動してerrorが出なくなったを確認します。exit(ログアウト)してホストマシンに戻ってからvagrantコマンドで再起動を行います。
kernel-develをインストールした影響で、gccなどのプラグインをインストールする挙動を見せました。
更にVirtualBox Guest Additionsなどもインストールしているようです。これらが無いとマウントに影響が出る気がします。
[root@localhost ~]# exit
logout
[vagrant@localhost ~]$ exit
logout
Connection to 127.0.0.1 closed.
shimoji@DESKTOP-5VTVL8G /cygdrive/c/Vagrant/rails_api
$ vagrant reload
~略~
Dependency Installed:
cpp.x86_64 0:4.8.5-36.el7
glibc-devel.x86_64 0:2.17-260.el7
glibc-headers.x86_64 0:2.17-260.el7
kernel-headers.x86_64 0:3.10.0-957.1.3.el7
libmpc.x86_64 0:1.0.1-3.el7
mpfr.x86_64 0:3.1.1-4.el7
Complete!
Copy iso file C:\Program Files\Oracle\VirtualBox\VBoxGuestAdditions.iso into the box /tmp/VBoxGuestAdditions.iso
~略~
errorが解消されました。
仮想マシンとホストマシンをポートフォワーディングする、フォルダを共有する
後々の事を見越して事前にしておく作業があります。Vagrantfileを編集し、以下の二つのことが出来るようにします。
1. ホストマシンのポートを仮想マシンのポートへ繋げる
理由:仮想マシン上で今回作成するrailsのアプリを立ち上げた際、そのアプリへホストマシン側からアクセスできるようにするためです。これにより、ホストマシン側から仮想マシン上のrailsのAPIを叩くことが出来るようになり、開発しやすくなります。
2. ホストマシンのディレクトリと仮想マシンのディレクトリを共有(同期)する
理由:仮想マシン上でrailsアプリを作成していきますが、そのアプリのソースコードをホストマシン上で編集できるようにします。ちょっとイメージが湧きにくいかもしれませんが、例えばホストマシンの/c/hogeというディレクトリと、仮想マシンの/root/fugaというディレクトリを共有(同期)したとします。そうすると、ホストマシンの/c/hogeにtest.txtファイルを作成し設置すると、/root/fugaのディレクトリ内にもtest.txtファイルが設置されます。さらに、その設置された/root/fuga/test.txtを仮想マシン側からviなどを使って編集しホストマシン側で中身を確認すると、編集内容が反映されているのが確認できます。
つまり、フォルダの共有というのは同期するということで、一方の変更がもう一方にも反映されほぼ同じように扱うことが出来るということです。
これにより、ホストマシン側でWinSCPを使って同期アップロードしたり、仮想マシン側でrailsコマンドを使って作成したファイルをホストマシン側にダウンロードしたりという必要がなくなり、「あれ、今ってどっちが最新だっけ?」や「あれ、反映されてないぞ」みたいな煩雑さを回避できます。
では編集していきます。
shimoji@DESKTOP-5VTVL8G /cygdrive/c/Vagrant/rails_api
$ vi Vagrantfile
「追加」と書かれている行を追加します。
~略~
# Create a forwarded port mapping which allows access to a specific port
# within the machine from a port on the host machine and only allow access
# via 127.0.0.1 to disable public access
# config.vm.network "forwarded_port", guest: 80, host: 8080, host_ip: "127.0.0.1"
config.vm.network "forwarded_port", guest: 3000, host: 3000, host_ip: "127.0.0.1" ←追加
~略~
# Share an additional folder to the guest VM. The first argument is
# the path on the host to the actual folder. The second argument is
# the path on the guest to mount the folder. And the optional third
# argument is a set of non-required options.
# config.vm.synced_folder "../data", "/vagrant_data"
config.vm.synced_folder "C:\\Vagrant\\rails_api\\rails_api", "/root/rails_api", owner: "root", group: "root" ←追加
ホストマシン側の共有(同期)するディレクトリを作成します。ゲストマシン側の共有(同期)するディレクトリは、Vagrantfile編集後に仮想マシンを再起動すると自動的に作成されます。
作成したホストマシン側のディレクトリのパスは/c/Vagrant/rails_api/rails_apiとなるはずです。同じディレクトリ名で入れ子になっていてややこしいので注意です。
shimoji@DESKTOP-5VTVL8G /cygdrive/c/Vagrant/
$ cd rails_api
shimoji@DESKTOP-5VTVL8G /cygdrive/c/Vagrant/rails_api
$ mkdir rails_api
仮想マシンを再起動します。ログにそれっぽいのが出るはずです。
shimoji@DESKTOP-5VTVL8G /cygdrive/c/Vagrant/rails_api
$ vagrant reload
~略~
==> default: Forwarding ports...
default: 3000 (guest) => 3000 (host) (adapter 1)
~略~
==> default: Rsyncing folder: /cygdrive/c/Vagrant/rails_api/ => /vagrant
==> default: Mounting shared folders...
default: /root/rails_api => C:/Vagrant/rails_api/rails_api
~略~
sshでログインし、rootユーザーにスイッチします。
shimoji@DESKTOP-5VTVL8G /cygdrive/c/Vagrant/rails_api
$ vagrant ssh
[vagrant@localhost ~]$ sudo su - root
[root@localhost ~]#
仮想マシン側にディレクトリが作成されているかを確認します。
[root@localhost ~]# ls
rails_api
無事に出来ていました。ホストマシン側にtest.txtファイルを設置して仮想マシン側から確認してみます。赤線のところがファイルを置くパスです。
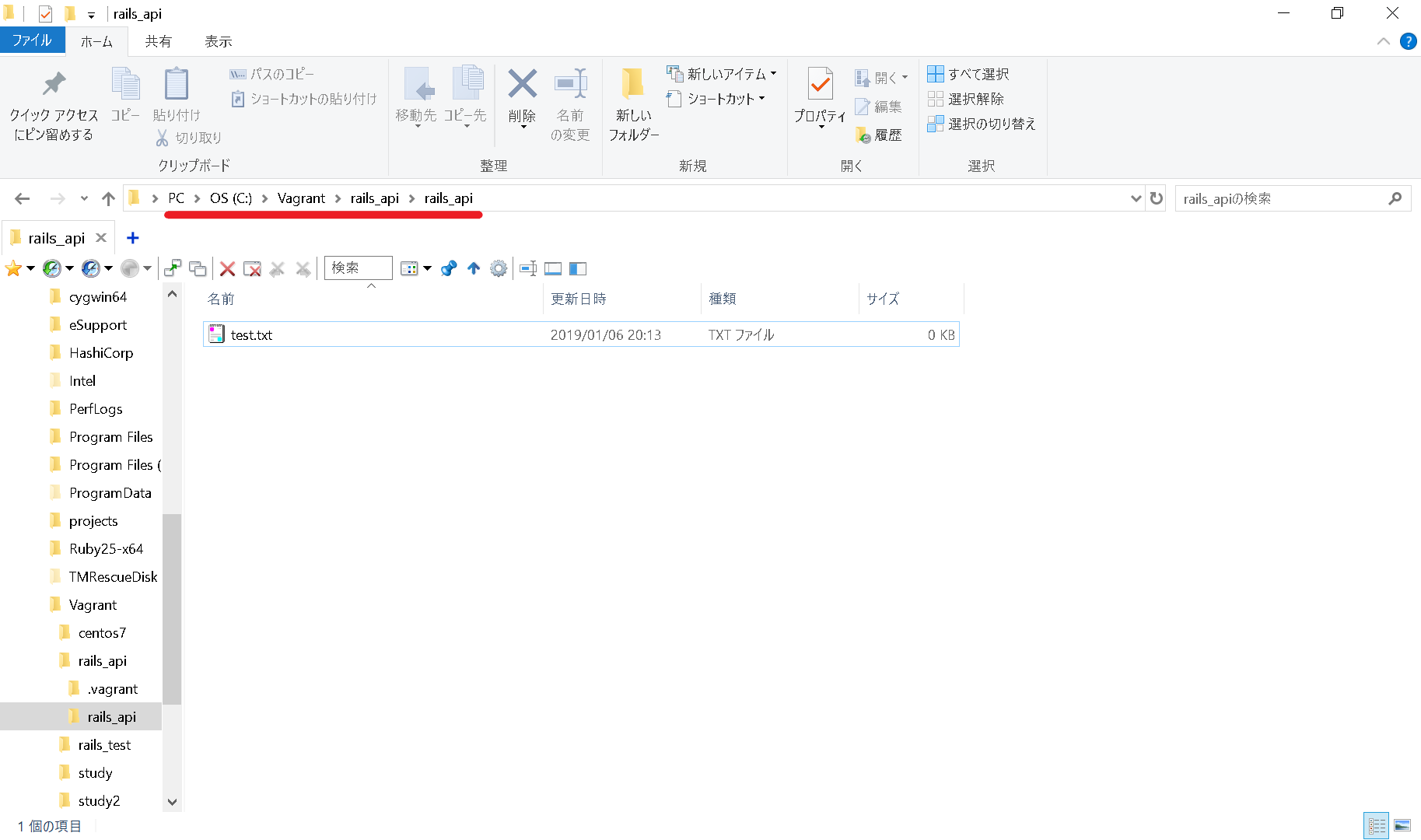 |
|---|
[root@localhost ~]# cd rails_api/
[root@localhost rails_api]# ls
test.txt
ちゃんと設置できていることが確認できました。ディレクトリの共有(同期)に関しては以上でOKですが、ポートをつなげる作業の成否確認は後々行います。順番がバラバラになってしまい申し訳ないですが覚えておいてください。
これでベースとなるBox(仮想マシン)のOSとしての最低限のセットアップはほぼ問題なく完了になったはずです。次章からrubyやpostgresqlなどをインストールしていきます。
仮想マシンにRubyをインストール
rbenvをインストール
gitをインストール
[root@localhost ~]# yum -y install git
rbenvのリポジトリをclone
[root@localhost ~]# git clone https://github.com/rbenv/rbenv.git ~/.rbenv
rbenvのパスを通す
[root@localhost ~]# echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile
[root@localhost ~]# ~/.rbenv/bin/rbenv init
# Load rbenv automatically by appending
# the following to ~/.bash_profile:
eval "$(rbenv init -)"
[root@localhost ~]# source ~/.bash_profile
インストール確認
[root@localhost ~]# rbenv -v
rbenv 1.1.1-39-g59785f6
ruby-buildのインストール
ruby-buildのリポジトリをclone
[root@localhost ~]# git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build
インストール
[root@localhost ~]# ~/.rbenv/plugins/ruby-build/install.sh
成功しているとrbenv installコマンドが使えるようになるので確認してみる。ここでは実際にインストールするわけではなく、コマンドが存在するかを確認するのみです。
[root@localhost ~]# rbenv install
Usage: rbenv install [-f|-s] [-kpv] <version>
rbenv install [-f|-s] [-kpv] <definition-file>
rbenv install -l|--list
rbenv install --version
~略~
Rubyをインストール
Rubyのインストールに必要なパッケージを事前にインストールしておく
[root@localhost ~]# yum -y install gcc make openssl-devel readline-devel openssl-devel zlib-devel
インストール可能なRubyのバージョン一覧を表示して最新バージョンを確認する
[root@localhost ~]# rbenv install -l
~略~
2.5.2
2.5.3 ← こいつが最新
2.6.0-dev ← 開発中
2.6.0-preview1 ← 開発中のもの一旦見せれるようにしたよその1
2.6.0-preview2 ← 開発中のもの一旦見せれるようにしたよその2
2.6.0-preview3 ← 開発中のもの一旦見せれるようにしたよその3
2.6.0-rc1 ← Release Candidateの略らしい。リリース直前でテスト中その1
2.6.0-rc2 ← Release Candidateの略らしい。リリース直前でテスト中その2
jruby-1.5.6 ← javaのruby(混乱)。今は気にしない
jruby-1.6.3 ← javaのruby(混乱)。今は気にしない
jruby-1.6.4 ← javaのruby(混乱)。今は気にしない
~略~
バージョンを指定してインストール
[root@localhost ~]# rbenv install 2.5.3
Rubyへのパスを通す
[root@localhost ~]# echo 'eval "$(rbenv init -)"' >> ~/.bash_profile
[root@localhost ~]# source ~/.bash_profile
rbenvコマンドを使って、使用するRubyのバージョンを指定して設定
[root@localhost ~]# rbenv global 2.5.3
インストール&ちゃんと設定できたかを確認
[root@localhost ~]# ruby -v
ruby 2.5.3p105 (2018-10-18 revision 65156) [x86_64-linux]
仮想マシンにPostgreSQLをインストール
PostgreSQLをダウンロード
今回は最新のpostgresql11を使用します。
上記のPostgreSQLの公式サイトにて、赤線のcentosのところにカーソルを合わせて右クリック⇒リンクをコピーでURLをクリップボードにコピーできます。
ちなみにchromeの場合であれば画面左下にリンクのURLが表示されるはずです。
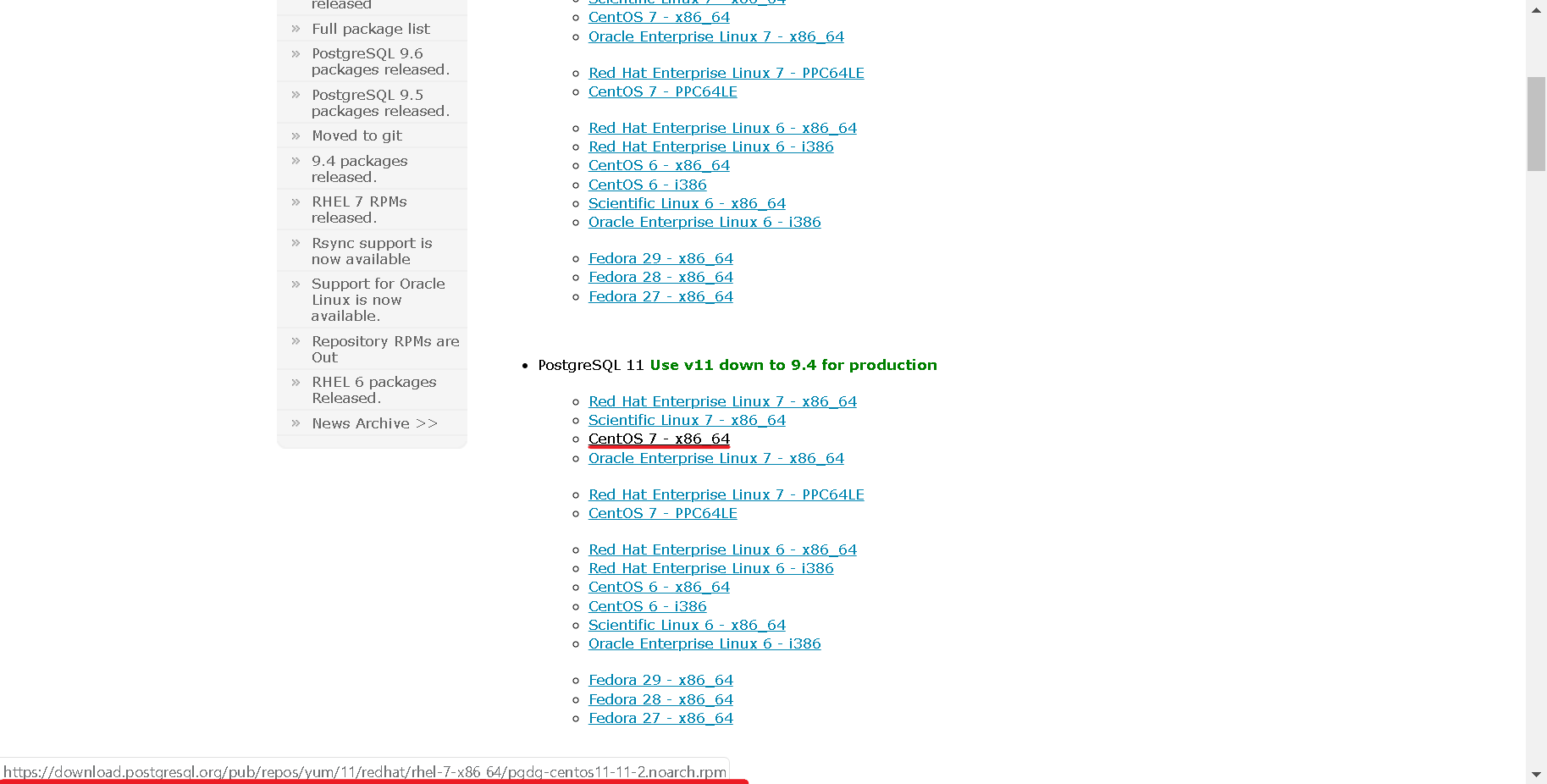 |
|---|
そのURLを指定してyum installします
[root@localhost ~]# yum -y install https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pgdg-centos11-11-2.noarch.rpm
postgresqlのインストール
[root@localhost ~]# yum -y install postgresql11-server
バージョンの確認
[root@localhost ~]# /usr/pgsql-11/bin/postgres --version
postgres (PostgreSQL) 11.1 ←11.1がインストールされていることが確認できる
DB初期化
[root@localhost ~]# /usr/pgsql-11/bin/postgresql-11-setup initdb
Initializing database ... OK
自動起動の設定
仮想マシンが起動するのと同時にPostgreSQLも起動するように設定します。
[root@localhost ~]# systemctl enable postgresql-11
Created symlink from /etc/systemd/system/multi-user.target.wants/postgresql-11.service to /usr/lib/systemd/system/postgresql-11.service.
起動
[root@localhost ~]# systemctl start postgresql-11.service
確認
[root@localhost ~]# systemctl status postgresql-11.service
● postgresql-11.service - PostgreSQL 11 database server
Loaded: loaded (/usr/lib/systemd/system/postgresql-11.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2019-01-04 13:01:16 UTC; 7s ago ← runningになっていれば起動しているということ
DBの設定
認証の無効化
pg_hba.confを編集します。このファイルではpostgresqlへのアクセスに対して、パスワードでの認証を行うかなどの設定が出来ます。今回はフルオープンで設定します(どんなアクセスも通しちゃいます)が、業務などでは絶対にしないでください。
[root@localhost rails_api]# find / -name pg_hba.conf
/var/lib/pgsql/11/data/pg_hba.conf
編集していきます。
[root@localhost ~]# vi /var/lib/pgsql/11/data/pg_hba.conf
# "local" is for Unix domain socket connections only
# local all all peer ←元々あった行をコメントアウト
local all all trust ←追加
# IPv4 local connections:
# host all all 127.0.0.1/32 ident ←元々あった行をコメントアウト
host all all 127.0.0.1/32 trust ←追加
# IPv6 local connections:
# host all all ::1/128 ident ←元々あった行をコメントアウト
host all all ::1/128 trust ←追加
編集が終わったら必ずpostgresqlを再起動しておきます。
[root@localhost rails_api2]# systemctl restart postgresql-11.service
rootのroleの追加
postgresユーザーにスイッチし、psqlを使ってDBの中に入ります。
[root@localhost ~]# su - postgres
viでファイルを作成&記述しますが、正直ここの理屈はよくわかっていません。。
-bash-4.2$ vi ~/.pgsql_profile
下記の内容を書き込みます。viの使い方は別途他の記事を参考にしてみてください。
PATH=/usr/pgsql-11/bin:$PATH
MANPATH=/usr/pgsql-11/share/man:$MANPATH
PGDATA=/var/lib/pgsql/11/data
export PATH MANPATH PGDATA
ちゃんと書き込みが出来たか確認します。
-bash-4.2$ cat .pgsql_profile
PATH=/usr/pgsql-11/bin:$PATH
MANPATH=/usr/pgsql-11/share/man:$MANPATH
PGDATA=/var/lib/pgsql/11/data
export PATH MANPATH PGDATA
psqlで設定を行っていきます。
-bash-4.2$ psql
roleを作成します。Role Playing Game(RPG)のroleのことで、役割のことです。role(役割)に応じて付与する権限を使い分けたりします。
今回作成するrailsアプリからPostgreSQLへアクセスしてくる際にはrootのroleを使用します。
role名もパスワードもrootとして設定しますが、これは業務ではセキュリティ上の問題があるため絶対にしないようにしてください。あくまでも今回のような勉強目的などで立てる場合のみです。
postgres=# CREATE ROLE root WITH CREATEDB LOGIN PASSWORD 'root';
CREATE ROLE ←成功したよっていうログ
成功したら抜けてrootに戻ります
postgres=# exit; ←psqlを抜ける
-bash-4.2$ exit ←postgresユーザーを抜ける
logout
この状態ではまだroleを作成しただけで、今回使用するDBはまだ作成されていません。後々の手順で作成します。
Railsをインストール
その前にgemをインストール
[root@localhost ~]# yum -y install rubygems
Railsをインストール。依存関係で39個ぐらいのgemがインストールされるはずです。そこそこ時間かかります。
[root@localhost ~]# gem install rails
railsのバージョンを確認します。
[root@localhost ~]# rails -v
Rails 5.2.2
railsアプリを作成
下記コマンドを実行。rails newコマンドでWebアプリに必要なフレームワークとしてのディレクトリ、ファイルが生成されます。
今回はJSON APIを作成するわけですが、--apiオプションを付けることでAPIモードで生成されます。
また、--databaseオプションにpostgresqlを指定します。
[root@localhost ~]# cd /rails_api/
[root@localhost rails_api]# rails new rails_api --api --database=postgresql
~略~
An error occurred while installing pg (1.1.3), and Bundler cannot continue.
Make sure that `gem install pg -v '1.1.3' --source 'https://rubygems.org/'` succeeds before bundling.
In Gemfile:
pg
run bundle exec spring binstub --all
bundler: command not found: spring
Install missing gem executables with `bundle install`
~略~
pgという名前のgemのインストールに失敗したとのエラーが出ました。pgを個別にgem installしようとしてみますが、やはりerrorになります。
[root@localhost ~]# gem install pg
/root/.rbenv/versions/2.5.3/bin/ruby -r ./siteconf20190104-26856-wvn5e7.rb extconf.rb
checking for pg_config... no
No pg_config... trying anyway. If building fails, please try again with
--with-pg-config=/path/to/pg_config
~略~
No pg_config... trying anyway. If building fails, please try again with
--with-pg-config=/path/to/pg_config
これはrails newする際に--with-pg-configというオプションでpg_configというファイルのパスを指定してみてくれ、という事らしいです。
pg_configの場所を調べます。
[root@localhost rails_api]# find / -name pg_config
/usr/pgsql-11/bin/pg_config
居ました。こいつのパスを指定して再度gemをインストールしてみます。しかしまたerrorです。
[root@localhost rails_api]# gem install pg --with-pg-config=/usr/pgsql-11/bin/pg_config
ERROR: While executing gem ... (OptionParser::InvalidOption)
invalid option: --with-pg-config=/usr/pgsql-11/bin/pg_config
調べてみると、-- --with-pg-configオプションを試してみて的な記事があったので試してみます。--が二回出てくるというのがポイントのようです。注意です。
参考:https://deveiate.org/code/pg/README_rdoc.html#label-How+To+Install
[root@localhost rails_api]# gem install pg -- --with-pg-config=/usr/pgsql-11/bin/pg_config
Building native extensions with: '--with-pg-config=/usr/pgsql-11/bin/pg_config'
This could take a while...
ERROR: Error installing pg:
ERROR: Failed to build gem native extension.
~略~
やはりだめでした。postgresql11-develというパッケージをインストールしないとダメみたいな記事もあったので、そちらも試します。
まずはpostgresql11-develパッケージを探します。yum install可能なパッケージリストを確認します。
[root@localhost rails_api]# yum list available | grep postgres
~略~
postgresql11-contrib.x86_64 11.1-1PGDG.rhel7 pgdg11
postgresql11-debuginfo.x86_64 11.1-1PGDG.rhel7 pgdg11
postgresql11-devel.x86_64 11.1-1PGDG.rhel7 pgdg11 ←こいつです
postgresql11-docs.x86_64 11.1-1PGDG.rhel7 pgdg11
~略~
インストールします。
[root@localhost rails_api]# yum -y install postgresql11-devel.x86_64
で、--のオプションを付けて試してみます。
[root@localhost ~]# gem install pg -- --with-pg-config=/usr/pgsql-11/bin/pg_config
Fetching: pg-1.1.3.gem (100%)
Building native extensions with: '--with-pg-config=/usr/pgsql-11/bin/pg_config'
This could take a while...
Successfully installed pg-1.1.3
Parsing documentation for pg-1.1.3
Installing ri documentation for pg-1.1.3
Done installing documentation for pg after 1 seconds
1 gem installed
無事にインストールできました。一旦仕切り直しということで、先ほどのrails newコマンドで作成されたファイル群は削除して新たにrails newしなおします。
rails_api/rails_apiのように同じ名前のディレクトリが入れ子になっていてややこしくなっています。今自分がどこにいるのか、都度pwdコマンドで確認しながら作業するのが安全です。
/root/rails_apiではなく、/root/rails_api/rails_apiを削除するので注意です。
[root@localhost rails_api]# rm -rf rails_api
[root@localhost rails_api]# rails new rails_api --api --database=postgresql
今度はエラーが出ずに成功したようです。作成されたディレクトリの中を確認してみます。
[root@localhost rails_api]# cd rails_api
[root@localhost rails_api]# ls -la
total 35
drwxrwxrwx. 1 root root 4096 Jan 6 11:21 .
drwxrwxrwx. 1 root root 0 Jan 6 11:20 ..
drwxrwxrwx. 1 root root 4096 Jan 6 11:20 app
drwxrwxrwx. 1 root root 0 Jan 6 11:21 bin
drwxrwxrwx. 1 root root 4096 Jan 6 11:20 config
-rwxrwxrwx. 1 root root 130 Jan 6 11:20 config.ru
drwxrwxrwx. 1 root root 0 Jan 6 11:20 db
-rwxrwxrwx. 1 root root 1504 Jan 6 11:20 Gemfile
-rwxrwxrwx. 1 root root 3576 Jan 6 11:21 Gemfile.lock
drwxrwxrwx. 1 root root 4096 Jan 6 11:20 .git
-rwxrwxrwx. 1 root root 574 Jan 6 11:20 .gitignore
drwxrwxrwx. 1 root root 0 Jan 6 11:20 lib
drwxrwxrwx. 1 root root 0 Jan 6 12:03 log
drwxrwxrwx. 1 root root 4096 Jan 6 11:20 public
-rwxrwxrwx. 1 root root 227 Jan 6 11:20 Rakefile
-rwxrwxrwx. 1 root root 374 Jan 6 11:20 README.md
-rwxrwxrwx. 1 root root 5 Jan 6 11:20 .ruby-version
drwxrwxrwx. 1 root root 0 Jan 6 11:20 storage
drwxrwxrwx. 1 root root 4096 Jan 6 11:20 test
drwxrwxrwx. 1 root root 0 Jan 6 12:03 tmp
drwxrwxrwx. 1 root root 0 Jan 6 11:20 vendor
無事にnewが出来たようです。
アプリ用のデータベースを設定する
既にpostgresqlを仮想マシンにインストールはしていますが、それはあくまでpostgresqlというミドルウェア(ソフトウェア)をインストールしただけです。postgresqlというミドルウェア内には複数のデータベースを作成することが出来ます。
この段階ではまだ今回使用するデータベースの作成は行っていない状態ですので新規に作成し設定していきます。
database.ymlを編集する
ここからは、rails newで作成されたアプリの各ファイルの編集は基本的にはホストマシン上で行っていきます。
共有(同期)を行っているため、ホストマシン上で編集するとそれが仮想マシンにも反映される仕組みです。
エディターにはvscodeを使用していますがどのエディターでもOKです。
下記の追加となっている行を追加します。railsアプリからはpostgresqlのDBにアクセスできるようになりますが、このdatabase.ymlで設定した各パラメータにしたがってpostgresqlにアクセスしに行きます。今回は先ほど作成したrootのroleとしてアクセスしに行くように設定し、passwordも先ほど設定したパスワードを指定し設定する必要があります。
hostパラメーターに関しては、railsサーバーから見たDBのアドレスを指定します。今回はrailsサーバーとDBが同じ仮想マシン上で起動しているため、localhostを指定します。
~略~
default: &default
adapter: postgresql
encoding: unicode
# For details on connection pooling, see Rails configuration guide
# http://guides.rubyonrails.org/configuring.html#database-pooling
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
username: root ←追加
password: root ←追加
host: localhost ←追加
~略~
この状態でDBの作成コマンドを実行します。このコマンドを実行すると、先ほど編集したdatabase.yml内の設定に応じた各DBがpostgresql上に作成されます。
なぜかrails_api_productionは作成されませんでしたが、今回は特に使用しないので問題無いです。
[root@localhost rails_api]# rails db:create
Created database 'rails_api_development' ←作成された
Created database 'rails_api_test' ←作成された
psqlコマンドでdatabaseの中を確認してみます。
postgreslユーザーにスイッチして更にpsqlに入る
[root@localhost rails_api]# su - postgres
-bash-4.2$ psql
データベース一覧を確認するコマンドを使用
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------------------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
rails_api_development | root | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
rails_api_test | root | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(5 rows)
DBが作成されているのが確認できましたので抜けます。
postgres=# exit
-bash-4.2$ exit
railsサーバーを起動してみます。
ちなみに、rails sコマンドのsはserverのsです。今後アプリ=サーバーと表現する場合が多々出てきます。呼び方は異なりますがアプリと同義の場合がほとんどなので覚えておいてください(もちろん、違う場合もあります)。
[root@localhost rails_api]# rails s
=> Booting Puma
=> Rails 5.2.2 application starting in development
=> Run `rails server -h` for more startup options
Puma starting in single mode...
* Version 3.12.0 (ruby 2.5.3-p105), codename: Llamas in Pajamas
* Min threads: 5, max threads: 5
* Environment: development
* Listening on tcp://0.0.0.0:3000
Use Ctrl-C to stop
無事に起動できました。3000番ポートでサーバー(アプリ)が起動したようです。
ログに「Use Ctrl-C to stop」と出ています。この状態でctrl+cのキーを入力すると、サーバーを停止することが出来ます。
また、バックグラウンドで起動しているわけではないので、起動中はそのcygwinのウィンドウでは他の作業(viやmkdirなど)が出来なくなります。
もし起動したまま他の作業をしたい場合は、別途cygwinのウィンドウを開くなどしてください。この記事では一つのcygwinウィンドウでも大丈夫なように解説を進めていきます。
仮想マシン上で起動しているrailsアプリへホストマシンからアクセスする
ではいよいよrailsサーバーにWebブラウザからアクセスしてみます。
ブラウザのアドレスバーにlocalhost:3000と入れてアクセスしてみます。
 |
|---|
キタ━━━━(゚∀゚)━━━━!!
これで環境構築編は終わりです。構築完了おめでとうございます。
ちょっとした余談
railsサーバーを起動するとデフォルトでは3000番ポートで起動します。つまり仮想マシン上でrailsサーバーが3000番ポートで立ち上がることになります。
また、localhostというのは自分自身を指し、3000というのは3000番ポートという意味です。今回の場合、localhostの3000番ポートに対してWebブラウザからアクセスするという事です。
ホストマシンのWebブラウザからloclhost:3000にアクセスするということは、ホストマシンからホストマシン自身の3000番ポートへアクセスするという事です。
上の方の章で行った作業を思い出してください。ホストマシン側(localhost側)の3000番ポートと、仮想マシン側の3000番ポートを繋げる作業をしました。
これにより、ホストマシンからlocalhostの3000番ポートにアクセスすると仮想マシン上の3000番ポートに繋がる事になりますが、その3000番ポートにはrailsサーバーがいますので、結果的に「ホストマシンから仮想マシンのrailsアプリへアクセスすることができる」ようになります。
下記のようなイメージです。
 |
|---|
コーディング編
ここまで来たら折り返し地点は既に過ぎています。
とはいっても、railsに用意されているコマンドを使えば自動的に生成できるものもあったりで、割と簡単です。
ここまでくればあとは何とかなるでしょう。
ゴール
今回は「企業(companies)」と「従業員(employees)」のデータを操作できるAPIを作っていきます。
ER図
登録/参照/更新/削除の対象となるDBで管理するデータは下記のとおりです。
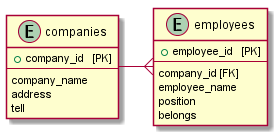
railsコマンドやbundleコマンドを使用する場所について
railsコマンドは基本的にはアプリディレクトリ配下のどこかでないと動きません(直下でなくても大丈夫です)。
もしアプリディレクトリ以外の場所でコマンドを打ってしまってエラーになっても慌てずにアプリディレクトリに帰ってきてください。
[root@localhost rails_api]# pwd
/root/rails_api/rails_api ←今回はここがアプリディレクトリです
rspecを追加
rspecとはrailsで定番となっているアプリをテストするためのgemです。
テストフレームワーク(テストするための枠組み、便利機能)の一種です。
テストとはコードが意図したとおりに実装されているかを判定することですが、テストフレームワークではテストしたい内容を本体のコードとは別にテスト用のコードとして記述し、それを実行した結果で判定を行います。
手動でテストすることも出来ますが、毎回同じ手順を人の手でやるのは圧倒的に非効率的です。
- 手動テストではミスが起きる可能性が毎回発生する(コードであれば一度正しいロジックを書けば何度実行しても基本的には同じ結果となり、ミスの可能性を取り除けます)
- 手動テストはエンジニアが拘束される(数秒で終わるテストであれば手動でも自動でも大差は無いのですが、開発が少し進むだけで手動テストは数分かかるようになることでしょう。コードを編集するたびにそんな時間を掛けて手動テストしていては時間が幾らあっても足りません。かと言って、手動テストの頻度を減らして後から一気に手動テストすることにした場合、ひとたびエラーが出るといつどこに追加したコードが悪さしているのかをデバッグするのに時間が取られ、もしそこで設計の欠陥が見つかった場合、一気にやった分だけ手戻りが大きくなります。テストをする頻度は究極を言えばコードを編集するたびに行うのが理想です。その方が手戻りが少なく出来るからです。また、後からコード化しようとするのも、まとまった時間が取れずズルズルと先延ばしになり、その間上記のような非効率的な開発が続き余計なコストを払うことになる可能性が高いです。後から時間を作り自動テスト化することを約束していたり、テストの導入時期を見極められる且つ権限の与えられた人がリーダーシップをとっているなどの環境でない限りは、初めからテストを書くのが無難です。「うちは小さい会社だからミニマムでいくべきでそれがビジネス的にも正しい」みたいなことを私はよく言われましたが、その議論に付き合うのは時間の無駄だと思うので、自分の人生やキャリアの方が大切であることを思い出して、テストを書くことがビジネス的に正しいとされる企業に転職するなどをした方が良いかと思います。コノカッコナゲー)
Gemfileを編集してrspecを追記し、コマンドを実行しインストールします。
vscodeで開いて下記の記述を追記します。
group :test do
gem 'rspec-rails'
gem 'factory_bot_rails'
end
インストールします。
[root@localhost rails_api]# bundle install
rails gコマンドでrspecを使用するのに必要なファイルを生成します。
gはgenerate(生成)のgです。
[root@localhost rails_api]# rails g rspec:install
Running via Spring preloader in process 852
create .rspec
create spec
create spec/spec_helper.rb
create spec/rails_helper.rb
使用するテストフレームワークをデフォルトのものからrspecに変更します。
require_relative 'boot'
require "rails"
# Pick the frameworks you want:
require "active_model/railtie"
require "active_job/railtie"
require "active_record/railtie"
require "active_storage/engine"
require "action_controller/railtie"
require "action_mailer/railtie"
require "action_view/railtie"
require "action_cable/engine"
# require "sprockets/railtie"
# require "rails/test_unit/railtie" ←この行をコメントアウト
~略~
module RailsApi
class Application < Rails::Application
# Initialize configuration defaults for originally generated Rails version.
config.load_defaults 5.2
# Settings in config/environments/* take precedence over those specified here.
# Application configuration can go into files in config/initializers
# -- all .rb files in that directory are automatically loaded after loading
# the framework and any gems in your application.
# Only loads a smaller set of middleware suitable for API only apps.
# Middleware like session, flash, cookies can be added back manually.
# Skip views, helpers and assets when generating a new resource.
config.api_only = true
# この下の4行を追加
config.generators do |g|
g.test_framework :rspec
g.fixture_replacement :factory_bot, dir: "spec/factories"
end
end
end
これでrspecの設定は終わりです。実務においては更に設定を加えたりしますが今回は割愛します。rspecの書き方が自分と違っていても慌てずに調べたり質問してみてください。
設定まで行ったところでまた別の個所を実装していきます。後々テストを書いていきます。
rails gコマンドで色々なファイルを追加
[root@localhost rails_api]# rails g scaffold 作成したいAPI名
この書式でコマンドを実行することによって作成したいAPIに必要な各種のファイルが自動で生成されます。
[root@localhost rails_api]# rails g scaffold company
Running via Spring preloader in process 6592
invoke active_record
create db/migrate/20190113093220_create_companies.rb
create app/models/company.rb
invoke rspec
create spec/models/company_spec.rb
invoke factory_bot
create spec/factories/companies.rb
invoke resource_route
route resources :companies
invoke scaffold_controller
create app/controllers/companies_controller.rb
invoke rspec
create spec/controllers/companies_controller_spec.rb
create spec/routing/companies_routing_spec.rb
それぞれのファイルの役割それぞれ以下のようになります。
db/migrate/20190113093220_create_companies.rb
マイグレーションファイルです。マイグレーションファイルとは、migrateコマンドを使用した際に記述内容に従ってDBにSQLを発行しCREATE TABLEやADD COLUMNなどが行われます(楽チン)。
また、SQLの代わりにファイルが出来るという事はGitによる版管理が出来る(さらには他の人との共有も)というメリットがあります。
今回生成されたマイグレーションファイルでは、DB内にcompaniesというテーブルを作成するSQLが書かれています。自動的にcompanyを複数形のcompaniesにしてくれています。
class CreateCompanies < ActiveRecord::Migration[5.2]
def change
create_table :companies do |t|
t.timestamps
end
end
end
マイグレーションファイルの名前にはファイルを作成した日時が頭に付きます。migrationコマンドではこの日付順にファイルを読み込んでSQLの発行を行います。
また、一度実行したマイグレーションファイルはDBをリセットしたりしない限り二回以上実行することは出来ません(companiesテーブルがある状態で更にCREATE TABLE companiesを行うとエラーになるため)。
また、今後カラムを追加したり色々とcompaniesテーブルに対して変更を加える場面が出てきますが、その際マイグレーションファイルの利用の仕方としては二通りあります。
- 一つのマイグレーションファイルを書き変えて使いまわしていく。マイグレーションファイルはDBをリセットしない限り一回しか実行できないので、マイグレーションファイルを書き換えるたびにDBをリセットしてmigrationコマンドを再実行する。中身は消える。
- 実行済みの既存のマイグレーションファイルは編集しない。変更したいのであればその分のマイグレーションファイルを新規に作成し実行していく。過去には遡らない。リセットを伴わないでの中身は消えない。
例えばカラム名を間違えてしまい修正したい場合、上記のいずれの方法でも修正することが出来ます。しかし、1の方法ではDBのリセットを行います。今回は学習目的なので大した問題にはなりませんが、業務で実際に稼働しているDBの場合はリセットしてはいけません。
業務ではDBの中身を失わずに変更を加える必要がある場合は2の方法を採ることになりますが、今の段階でその方法に慣れておいた方が良いでしょう。
app/models/company.rb
モデルファイルはDBとのやり取りを担うファイルです。
生成されたcompany.rbにはclassが定義されているだけで中身は何もありません。
このclassに色々とメソッドやらバリデーションやらリレーションやらを定義していく事になります。
class Company < ApplicationRecord
end
また、ファイル名のcompanyとクラス名のcompanyは一致させておく必要があります(一致しなくても良いかもしれませんがやったことが無いのでわかりません)。
このcompanyという名前を元に、railsはDB内のcompaniesと紐付けを行います。
これにより、モデルのcompanyクラスはDBのcompaniesを色々と操作できるようになるわけです。
こういった紐付けをrailsが自動的にやってくれるというのはモデルに限らず色々な場面で出てきます。
片方が複数形だがもう片方は単数形という場合もあり、単純にファイル名を全く同じ文字列にすれば良いというわけではありません。
初めの内は戸惑ったり躓いたりするかもしれませんが次第に慣れてきます。
全てを丸暗記する必要は無いので、紐付けを意識しないといけなさそうだなと気を付けられるようになればとりあえずは良いと思います。あとはggれば良いだけなので。
app/controllers/companies_controller.rb
コントローラーファイルはリクエストの一発目を受け、レスポンスに必要なモデルのメソッドを呼び出してデータを受け取ったのち、レスポンスとして返します。
companiesテーブルにカラムを追加する
migrationコマンドを使用して追加します。今回companiesには企業名(company_name)と住所(address)、電話番号(tell)の三つを管理するのでこの三つのカラムを追加します。
それぞれstring型を指定します。
[root@localhost rails_api]# rails g migration AddColumnToCompany company_name:string address:string tell:string
Running via Spring preloader in process 11031
invoke active_record
create db/migrate/20190113105655_add_column_to_company.rb
ファイルの中を見てみます。
class AddColumnToCompany < ActiveRecord::Migration[5.2]
def change
add_column :companies, :company_name, :string
add_column :companies, :address, :string
add_column :companies, :tell, :string
end
end
db:migrateコマンドを実行しDBに反映させます。
[root@localhost rails_api]# rails db:migrate
== 20190113105655 AddColumnToCompany: migrating ===============================
-- add_column(:companies, :company_name, :string)
-> 0.0147s
-- add_column(:companies, :address, :string)
-> 0.0020s
-- add_column(:companies, :tell, :string)
-> 0.0034s
== 20190113105655 AddColumnToCompany: migrated (0.0209s) ======================
これでcompaniesテーブルにはカラムが出揃いました。
初期データを登録する
companiesテーブルに初期データを入れてみます。
railsでは初期データはseeds(シーズ、種)と呼ばれています。
今回のアプリ開発ではseedsが必要になる場面は特には無いのですが、一応試しておきます。
Companyクラス、これはモデルに作成されたCompanyクラスです。Companyクラスに対してcreateメソッドを呼び出し、その引数として各カラム名と値をkey: valueの形で渡します。
言葉にするとちょっと複雑ですが、すぐにこんなもんだと感覚的に慣れます。
# This file should contain all the record creation needed to seed the database with its default values.
# The data can then be loaded with the rails db:seed command (or created alongside the database with db:setup).
#
# Examples:
#
# movies = Movie.create([{ name: 'Star Wars' }, { name: 'Lord of the Rings' }])
# Character.create(name: 'Luke', movie: movies.first)
# ここから下を追加
Company.create(
company_name: 'Hoge株式会社',
address: '東京都新宿区1-1-1',
tell: '0312345678'
)
これを実行します。ログは特に出ません。
[root@localhost rails_api]# rails db:seed
ちゃんとDBに登録されたのかを次の章で確認します。
Postmanを使用してAPIを叩く
下記のchromeウェブストアからPostmanをchromeに追加してください。
https://chrome.google.com/webstore/detail/postman/fhbjgbiflinjbdggehcddcbncdddomop/related?hl=ja
追加されたアプリを起動すると、アカウント登録/ログインを求められます。なんでAPIクライアントなのにサインインが必要なのかは謎です。
話が脱線してしまいますが、Postmanで叩いたデータってGoogleに送られているんですかね。業務で使うのってどうなんでしょう。ずっと気になってました。
とりあえず今回は赤線のところをクリックしてサインインせずに使っていきます。
HTTPメソッドとエンドポイントの組み合わせを指定します。赤線の部分をクリックすると色々なHTTPメソッドが選択肢として出てくるので、GETを選択し、アドレスバーの部分にエンドポイントを入力します。
今回はhttp://localhost:3000/companiesがエンドポイントとなります。
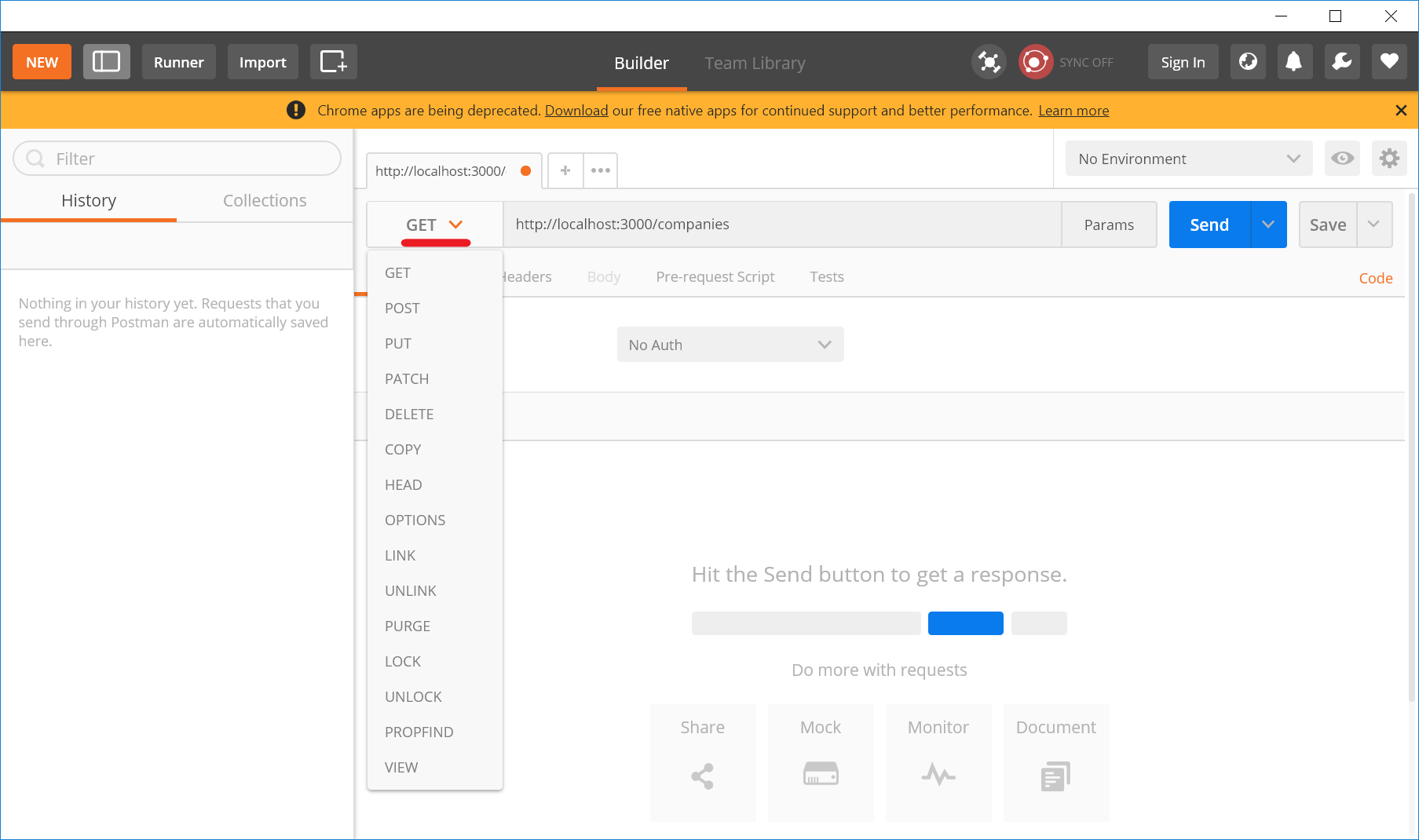
railsサーバーが起動している状態であることを確認し、青いSendボタンをクリックします。
するとこんなデータが返ってきました。
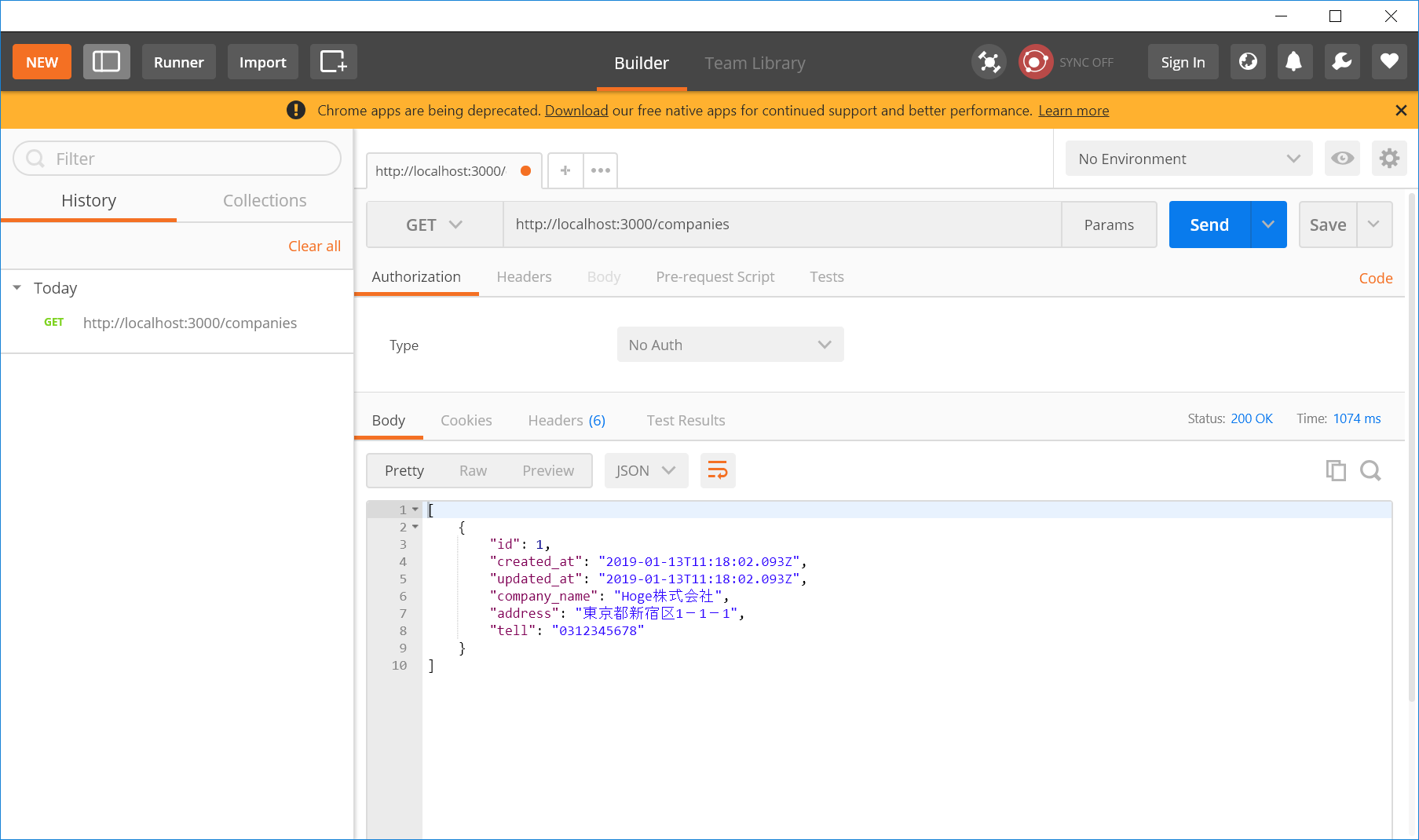
[
{
"id": 1,
"created_at": "2019-01-13T11:18:02.093Z",
"updated_at": "2019-01-13T11:18:02.093Z",
"company_name": "Hoge株式会社",
"address": "東京都新宿区1-1-1",
"tell": "0312345678"
}
]
companiesエンドポイントに対してGET(参照)を行った結果、配列になったデータが取れたという事です。
seedsでの登録は無事に成功していたようです。
上記は全てのcompaniesのレコード(リソース)を取得するというエンドポイントですが、一件だけを指定して取得することも出来ます。
idを指定してみます。
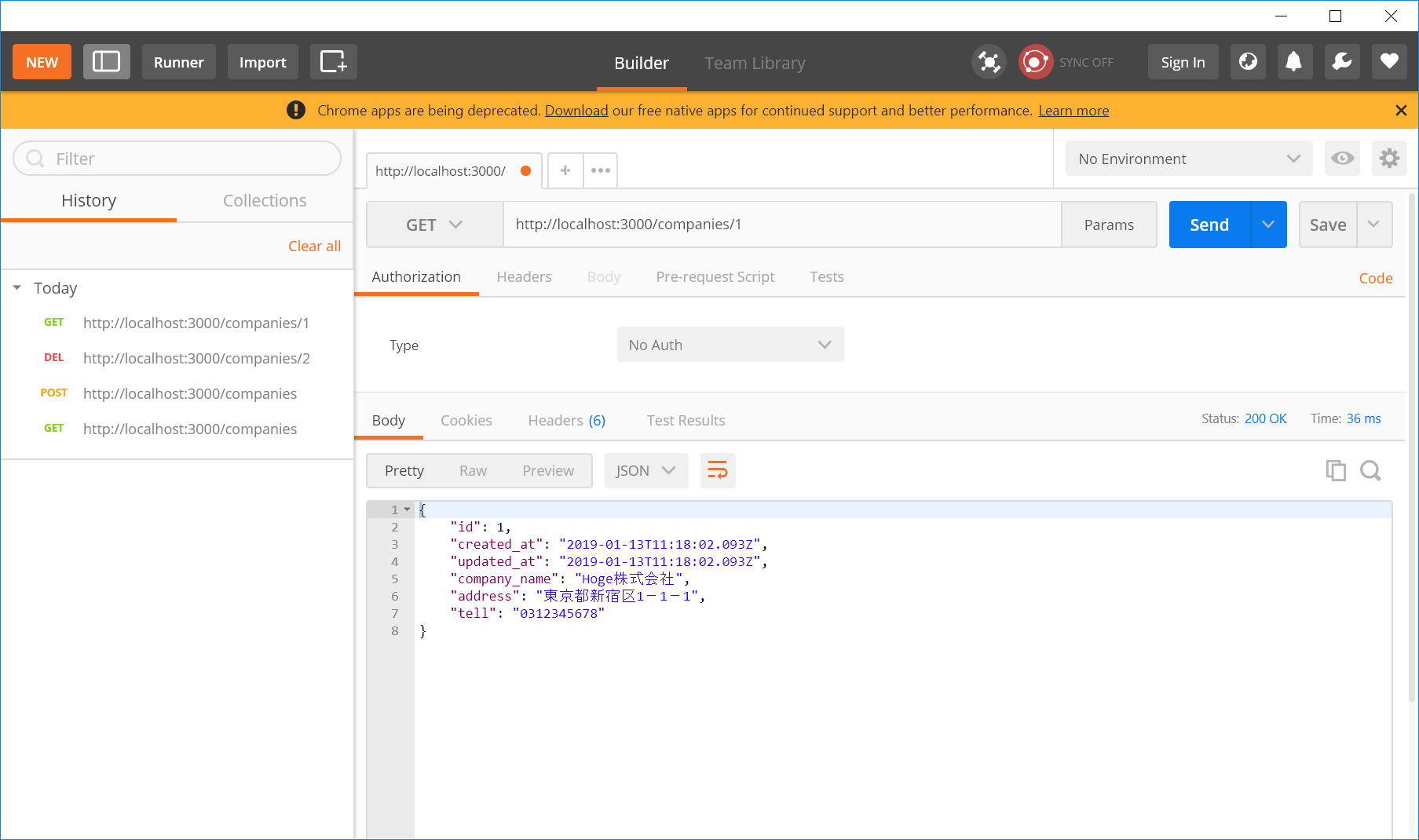
{
"id": 1,
"created_at": "2019-01-13T11:18:02.093Z",
"updated_at": "2019-01-13T11:18:02.093Z",
"company_name": "Hoge株式会社",
"address": "東京都新宿区1-1-1",
"tell": "0312345678"
}
配列ではなくなっていますね。
では次にcompanyをPOSTして新規登録してみます。
HTTPメソッドはPOSTを選択、エンドポイントはhttp://localhost:3000/companyです。
赤線のところを選択肢、赤丸の部分に下記のようなデータを貼り付けます。
seedsで書いたような記述と似ていますね。
{
"company_name": "Fuga有限会社",
"address": "東京都中央区1-1-1",
"tell": "0398765432"
}
Sendボタンを押してみます。エラーになってしまいました。

このような仕様になっているのはセキュリティの観点からのようです。
例えば、先ほどGETしたJSONの中に含まれるcreated_at(作成日時)という項目はRailsが自動でDBに登録するものですが、これを指定してPOSTされたりUPDATEされたりすると未来や過去の日付を指定出来てしまいます。
他にも、仮にユーザー管理を行うアプリの場合、各リソース毎にuser_idなどを持たせてどのユーザーの持ち物であるかを管理することになるのですが、そのuser_idを操作できてしまうとデータの窃盗や削除などの悪意ある操作が出来てしまうと考えられます。
Railsではアプリ開発者が許可していないカラム/項目に関しては操作が出来ないようになっているのですが、この機能/仕組みの事をstrong parameterと言います。許可したparameter(項目/カラム)のみリクエストを受け付けるということです。
今回エラーが出たのは「操作を許可する」というコードをまだ追加していないためです。
次章から許可の記述を加えていきます。
strong parameterを編集してPOSTとPATCHも出来るようにする
controllerを編集し、適切なカラムへリクエストできるように許可します。scaffoldコマンドで作成したままの素の状態ではcompaniesテーブルのいかなるカラムに対しても登録時の指定や更新時の指定が出来ないようになっています。
companies_controller.rbのparams.fetch(:company, {})となっている部分を下記のように編集します。
~略~
# Only allow a trusted parameter "white list" through.
def company_params
params.permit(
:company_name,
:address,
:tell
)
end
~略~
編集を終えたらrailsサーバーを再起動し、先ほどと同じようにpostmanでPOSTを試します。
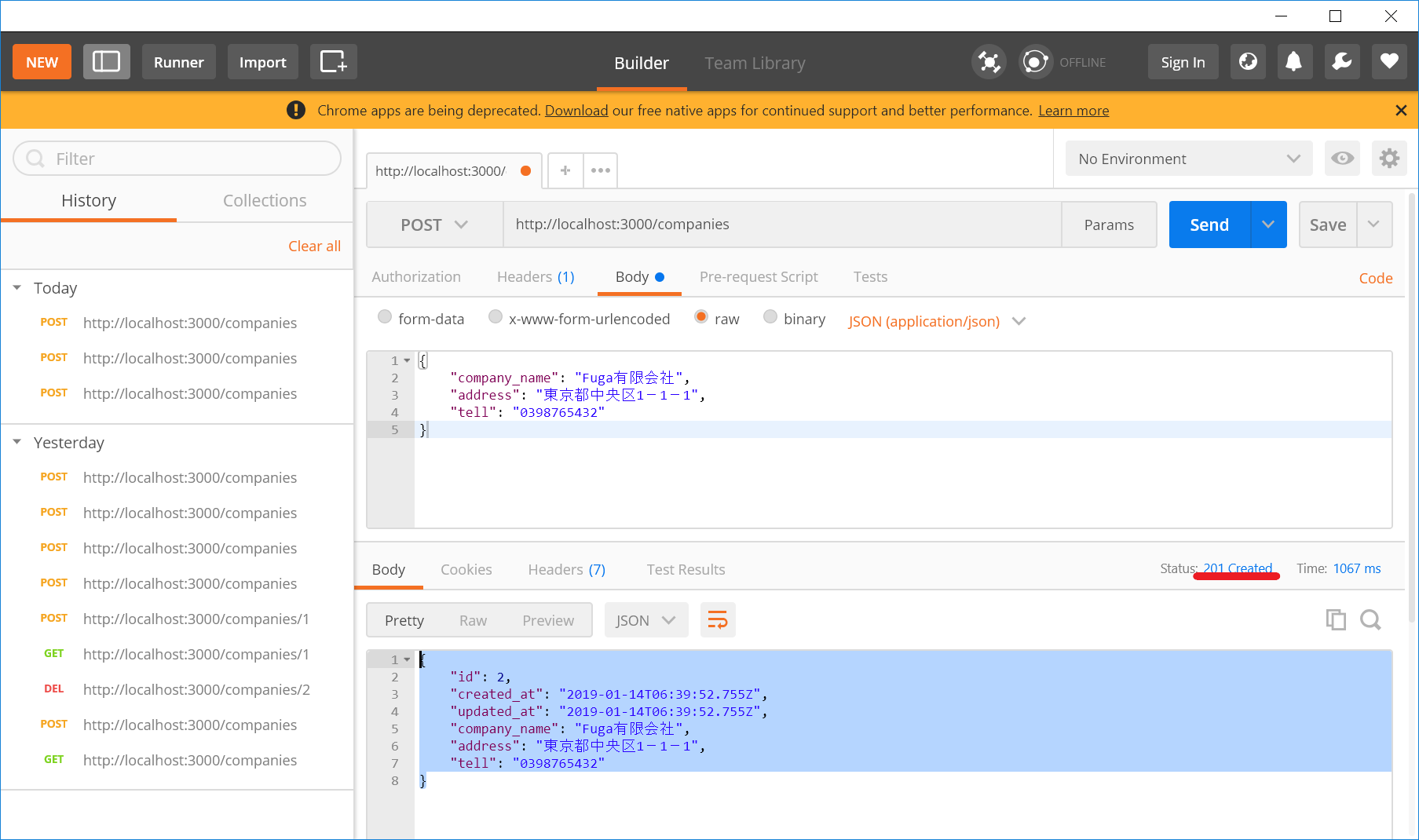
無事に登録されたようです。赤線部分はHTTPステータスコードで、201というのは登録に成功した事を意味します。
同じようにUPDATEも試してみます。
company_nameをpiyo有限会社に変更してみます。
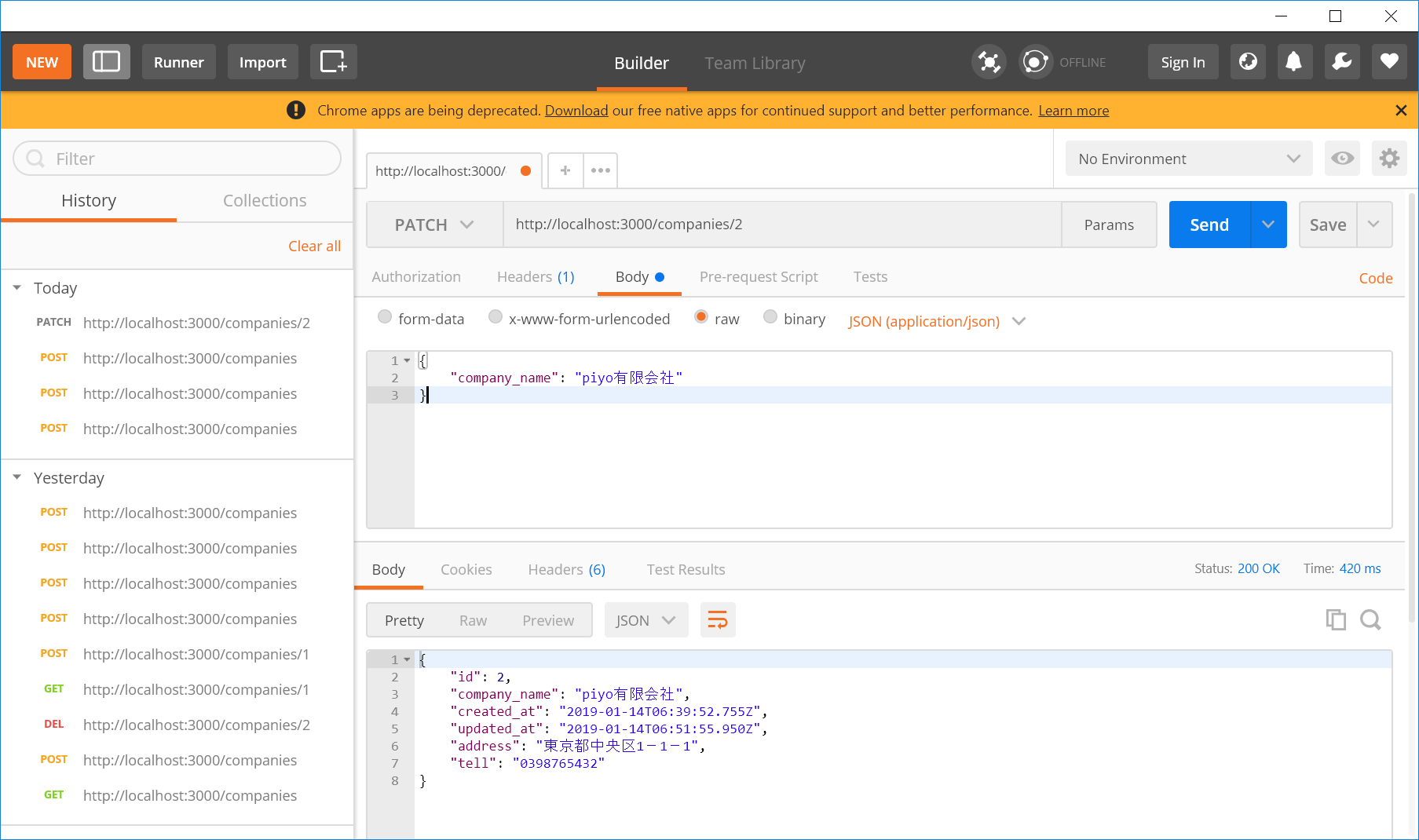
成功し、ちゃんとcompany_nameが変わりました。HTTPステータスコードは今度は200になっています。
200というのは成功したという意味、参照/更新/削除など色々な処理の成功を表す比較的汎用的なコードです。
先ほどの201は少し特殊で、登録の成功の場合にしか使いません。
試しに削除もしてみましょう。bodyの部分に先ほどのリクエスト内容が残ってしまっていますが気にしないでください。あっても無くても問題ありません。
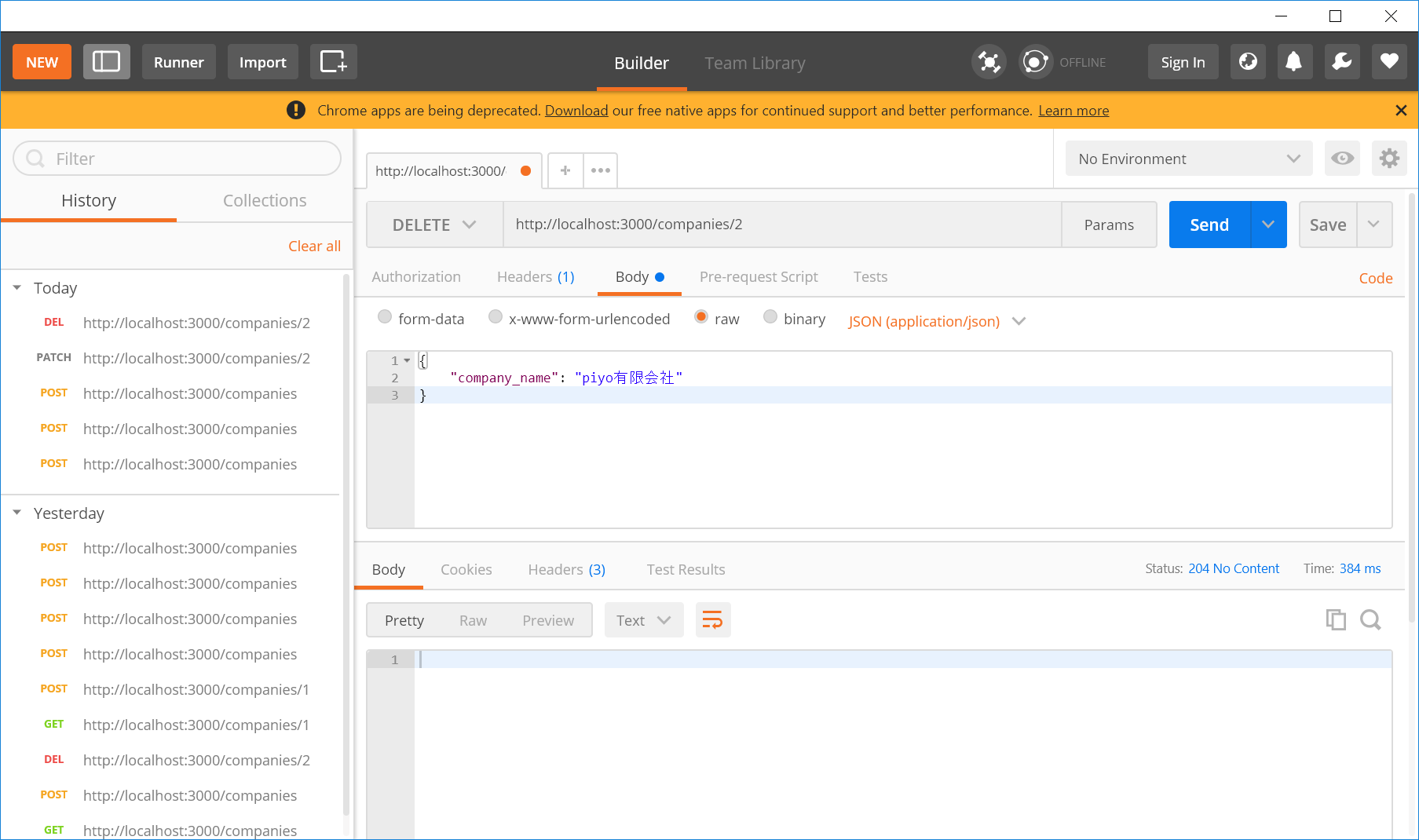
成功したようです。削除されたからなのか、レスポンスのボディに何もありません。
HTTPステータスコードは204となっています。
返す内容があるかないか200と204を使い分けるようですが、今回は204のままで問題無いです。
employeesのAPIを追加する
追加する際のカラム名などは異なりますが、方法はcompaniesを追加した時と一緒です。
以下は手順の再確認や補足など。
- rails gコマンドでemployeesを追加する
- 追加するカラムの内companye_idはintegerではなくblongs_toという後述する型を指定してください(company_id: * belongs_to)
- controllerを編集しカラムを許可する
- seedは不要
ここに関しては応用になるので割愛します。是非自分で追加してみてください。
railsサーバーの再起動を忘れたりとかで色々ハマるかもしれませんが、それも勉強です。
companiesとemployeesに関連付け (アソシエーション)を張る
employeesが追加出来たら、companiesとemployeesの関連付け (アソシエーション)を定義していきます。
今回は一つのcompaniesに対して複数のemployeesが紐づくモデルにします。
関連付け (アソシエーション)はモデルクラスに記述を行います。
class Company < ApplicationRecord
has_many :employees ←こいつを追加
end
class Employee < ApplicationRecord
belongs_to :company ←こいつを追加
end
| 名前 | 説明 |
|---|---|
| has_many: xxx | xxxの複数のレコードが紐づくという事。親に当たる |
| belongs_to: xxx | xxxのある一つのレコードに複数紐づくという事。子に当たる |
一つの企業に複数の従業員を紐づけます(在籍させます)。今回は割愛しますが、逆に一人の従業員が複数の企業に紐づく(在籍する)という関係を表現したい場合はまた別の記述にしてモデリングする必要があります。
コロンの位置や単数形/複数形の違いに気を付けてください。従業員から見て企業は一つなのでcompany(単数形)で、企業から従業員を見るとemployees(複数形)となるという事です。これはrailsの規約です。
ちなみに、rails g migrationコマンドでこの辺も指定できるようなのですが、使い勝手が悪そうな直感がしたのでこの方法で関連付けを行っています(食わず嫌い)。
employeesのPOST APIを使って登録しつつcompanyに紐づけてみる
activemodel_serializerを使ってAPIのレスポンス内容を編集する
activemodel_serializerというgemを使用するとレスポンスのJSONをカスタマイズしやすくなります。似たようなgemは他にもあります。また、これらが無くてもJSONのカスタマイズは出来るのですが、使用した方がはるかに楽なので何かしらのgemを使用しましょう。
今回はactivemodel-serializerを使用します。
Gemfileの一番下にgemを追加しbundle installします。
~略~
# レスポンスボディ加工用 ←何用のgemなのかをコメントしておくのが良いよ
gem 'active_model_serializers' ←これを追加
[root@localhost rails_api]# bundle install
rails g コマンドを使ってserializerを追加します。単数形複数形や大文字小文字に気を付けてください。
[root@localhost rails_api]# rails g serializer Employee
Running via Spring preloader in process 17752
create app/serializers/employee_serializer.rb
生成されたファイルを下記のように編集します。この編集の仕方でレスポンスボディのJSONを色々とカスタマイズできるようになります。
ちなみに、company_idをattributesに追加するのではなく、関連付け(アソシエーション)を書くと、対応したserializerがあればそのserializerの記述に基づいてよしなにやってくれます。
class EmployeeSerializer < ActiveModel::Serializer
attributes :id,
:employee_name,
:position,
:belongs,
:company
has_one :company
end
今回はhas_one: companyとしたので、company_serializer.rbが必要になります。
class CompanySerializer < ActiveModel::Serializer
attributes :id,
:company_name,
:address,
:tell
end
この状態でrailsサーバーを再起動してpostmanからemploeesをGETしてみます。
{
"id": 1,
"employee_name": null,
"position": null,
"belongs": null,
"company": {
"id": 1,
"company_name": "Hoge株式会社",
"address": "東京都新宿区1-1-1",
"tell": "0312345678"
}
}
ちゃんと関連(アソシエーション)が張られていて、且つ適切なserializerの記述になっていれば、employeeの親となるcompanyの情報が含まれているはずです。
バリデーションを書いてみる
Companyモデルに対して、「company_nameが必ず入力されていること」というバリデーションを組みます。
バリデーションとは検証のことで、今回の場合はPOSTやUPDATEでリクエストされた際にcompany_nameが必ず存在するかどうかを検証(バリデーション)するという事です。
バリデーションは基本的には各モデルクラスに追加します。
class Company < ApplicationRecord
has_many :employees
validates :company_name, presence: true ←個々を追加。presenceをtrueにする事で必須項目として検証できるようになる
end
railsサーバーを再起動してcompaniesに対してPOSTを試してみます。
addressだけを指定してそれ以外は空のJSONをリクエストしてみます。
{
"address": "東京都千代田区3-3-3"
}
422のステータスコードとともに"can't be blank"というエラーメッセージが返ってきました。バリデーションが効いているという事です。
{
"company_name": [
"can't be blank"
]
}
実際の業務ではエラー時のレスポンスボディはカスタマイズしたりします。JSONの構造を変えたり、必要であればエラーメッセージを日本語化したりなどです。
テストを書いてみる
実装したバリデーションをテストするコードを追加します。今回で言うと、追加したcompany_nameのバリデーション(検証)が本当に効いているのかをテストするという事です。
テストのメリットに関してはここでは触れませんが、業務では必須のものと認識してもらって差し支えありません。
先ほど追加したRspecの機能を使ってテストしていきます。
rpsecにはmodel specやrequest specなど、何種類かのspecが用意されていますが、今回はrequest specを使っていきます。
rails gコマンドでrequest specのファイルを生成し編集していきます。
[root@localhost rails_api]# rails g rspec:request company
Running via Spring preloader in process 8018
create spec/requests/companies_spec.rb
require 'rails_helper'
RSpec.describe "Companies", type: :request do
↓ここのブロックをコメントアウト。GETのテストを書く時の参考とかにしてみてね
# describe "GET /companies" do
# it "works! (now write some real specs)" do
# get companies_path
# expect(response).to have_http_status(200)
# end
# end
↓ここのブロックを追加
describe "POST /companies" do
it "company_nameが必須であること" do
request_params = {
company_name: nil
}
post "/companies", params: request_params
expect(response).to have_http_status(422)
end
end
end
rspecコマンドを使って編集したrequest specを実行してしてみます。
[root@localhost rails_api]# rspec spec/requests/companies_spec.rb
.
Finished in 0.37985 seconds (files took 3.68 seconds to load)
1 example, 0 failures
1 exampleというのは1個のテスト(itのブロックの事です)があり、その中で0 failures、つまり失敗はゼロだったという結果です。
「POST時にcompany_nameが空だった場合422でリクエストが失敗すること」というテストなわけですが、「ちゃんと422で失敗した」という事でテストとしては成功したという事です。
specに関する相談
個人的にはcontroller specは不要で、model specに関しても基本的には殆ど書く必要が無いんじゃないかという認識です。
request specはAPIとして入出力を一貫してテストできます。
一方、model specの場合、メソッドをモデルに追加してそのメソッドのテストを書いたとしても、「そのメソッドをちゃんと呼び出しているか」、「適切に使っているか」、みたいなところまではテストできないので、APIとして意図したレスポンスになっているかどうかは結局request specを書く必要が出てきます。
APIの入出力とは関係の無い部分のテストをmodel specに書くのはアリだと思いますが、APIの入出力に関する事であればrequest spec一本でやった方が工数が削減できると思います。
この考え方について色々調べてみましたが、controller specが非推奨であるという点は見つかったものの、request specに一本化するという開発スタイルの例は見付けられませんでした。他の方のご意見を伺いたいところです。
テストを書き終わって
テストの章がこの記事における実作業的な内容を含んだ章としては最後のものになります。
ここまで読んでいただき本当にありがとうございます。めっちゃ長かったと思います。
繰り返しになってはしまいますが、記事内の誤りなどあればご指摘いただけると助かります。
参考になったと思っていただけた方はいいねボタンとコメントをお願いします!
お疲れ様でした!\(^o^)/