今回は先日オープンソース化したGeek Guild社が提供しているSmallTrainを使って
簡単な転移学習を実行したレビューをします。
(本記事はGeekGuild様より依頼を受けて書いています)
記事作成にあたり公式HPに記載されているチュートリアルを参考にしています。
作成するモデルの概要
SmallTrainの学習デモを応用して自作の熊の画像認識を行うモデル、熊: 0 , 哺乳類(猫,鹿,犬,馬): 1 , 乗り物(飛行機,車,船,トラック): 2 として認識するモデルを作成します。
環境構築
今回はAWSのGPUインスタンス上で実行しています。
方法については以下を参照してください。
- AWSでGPUインスタンスを使う準備
- AWSのGPUインスタンスを使う
- SmallTrainをAWSのGPUインスタンスで動かす(※「SmallTrain用のDocker bridge networkを作成します。」まで)
1つ目のリンクについてはGPUインスタンス使用のための制限緩和のリクエストについての説明のため必要がなければ2つ目のリンクのみ参照してください。
リンク先にも記載がありますがGPUインスタンスの利用額はCPUのものより高額のため利用の際は注意が必要です。
データの準備
学習のための画像を準備します。熊以外の画像についてはデモで使用されているCIFAR10の画像を流用しています。
SmallTrainのソースに含まれるconvert_cifar_data_set.pyを参考に作成しました。
CIFAR-10とCIFAR100ではフォルダ構成が異なっており多少工夫が必要ですが画像ファイルの仕様は同一のため比較的簡単にデータを準備することができます。
こちらで今回の記事で利用した修正後のソースを公開しておりますのでご自身で差し替えて頂く(/var/smalltrain/tutorials/image_recognition/convert_cifar_data_set.py)か公開しているブランチをクローンして頂ければと思います。
※注意:今回はあえて上書きしているため以前のチュートリアルが実行できなくなります。以前の状態に戻すには再度オリジナルのSmallTrainをcloneしてください
熊の画像
CIFAR-100を利用しています。
CIFAR-100では熊の画像はClassは3に分類されており、このクラスの画像のみ取得しています。
再定義後のクラスは0としています。
データセット作成
チュートリアルのこちらのページを参考に作成します。
データセット定義ファイル(/var/data/cifar-10-image/data_set_def/train_cifar10_classification.csv)に以下の行が作成されるようにします。
data_set_id,label,sub_label,test,group
/var/data/cifar-10-image/data_batch_1/data_batch_1_i90000_c0.png,0,0,0,TRAIN
...
/var/data/cifar-10-image/data_batch_5/data_batch_5_i90099_c0.png,0,0,0,TRAIN
/var/data/cifar-10-image/test_batch/test_batch_i90000_c0.png,0,0,1,TRAIN
...
/var/data/cifar-10-image/test_batch/test_batch_i90099_c0.png,0,0,1,TRAIN
CIFAR100のデータはバッチに分けられていないのでdata_batch_1からdata_batch_5まで均等に分けるようにします。
番号を90000から振っているのはdata_batch_1とtest_batchの9から始まるデータのみを使った同時実行されるスモールデータ学習利用のためです。
熊以外の画像
CIFAR-10を利用しています。
10個のClassを2種類に分けて再定義しています。
| 元のClass | 今回のClass |
|---|---|
| 3,4,5,7 (猫,鹿,犬,馬) | 1 (哺乳類) |
| 0,1,8,9 (飛行機,車,船,トラック) | 2 (乗り物) |
Class1と2でデータ数を揃えるため2(鳥),6(カエル)は除外しています。
データセット定義ファイル(/var/data/cifar-10-image/data_set_def/train_cifar10_classification.csv)に以下の行が作成されるようにします。
data_set_id,label,sub_label,test,group
/var/data/cifar-10-image/data_batch_1/data_batch_1_i0_c2.png,2,2,0,TRAIN
...
/var/data/cifar-10-image/data_batch_5/data_batch_5_i90099_c0.png,0,0,0,TRAIN
/var/data/cifar-10-image/test_batch/test_batch_i0_c1.png,1,1,1,TRAIN
...
/var/data/cifar-10-image/test_batch/test_batch_i90099_c0.png,0,0,1,TRAIN
画像ファイル自体はデータセット定義ファイルに記載されているパスに格納します。
元のClassの画像はbatchあたり1000個あるためClass0:Class1:Class2のデータ比率は100:4000:4000となります。
Class0の画像だけ少ないデータセットとなっています。
学習の実行
SmallTrainをAWSのGPUインスタンスで動かすページの
「dockerイメージを実行します。」以降を実施します。
実行結果の確認
チュートリアルにあるように学習後の予測結果を確認します。(less /var/data/smalltrain/results/report/IR_2D_CNN_V2_l49-c64_TUTORIAL-DEBUG-WITH-SMALLDATASET-20200708-TRAIN/prediction_e35999_all.csv)
DateTime,Estimated,MaskedEstimated,True
/var/data/cifar-10-image/test_batch/test_batch_i0_c1.png_0,1,0.0,1
/var/data/cifar-10-image/test_batch/test_batch_i1_c2.png_0,2,0.0,2
/var/data/cifar-10-image/test_batch/test_batch_i2_c2.png_0,2,0.0,2
/var/data/cifar-10-image/test_batch/test_batch_i3_c2.png_0,2,0.0,2
/var/data/cifar-10-image/test_batch/test_batch_i4_c2.png_0,2,0.0,2
...
/var/data/cifar-10-image/test_batch/test_batch_i90095_c0.png_0,0,0.0,0
/var/data/cifar-10-image/test_batch/test_batch_i90096_c0.png_0,0,0.0,0
/var/data/cifar-10-image/test_batch/test_batch_i90097_c0.png_0,0,0.0,0
/var/data/cifar-10-image/test_batch/test_batch_i90098_c0.png_0,0,0.0,0
/var/data/cifar-10-image/test_batch/test_batch_i90099_c0.png_0,0,0.0,0
上記の例では分類が正しく行われていることが確認できます。もちろん
以下の表はtest accuracyと個別の画像の精度をまとめており、画像はTensorBoardのtest accuracyのグラフとなっています。
今回の検証は5時間程度の計算の結果となっています。気軽に画像認識モデル作成が体験できます。
| epoch | 15999 | 35999 |
|---|---|---|
| test accuracy | 0.9762 | 0.973 |
| 熊画像以外の精度 | 0.9826 | 0.9723 |
| 熊画像のみの精度 | 0.46 | 0.73 |
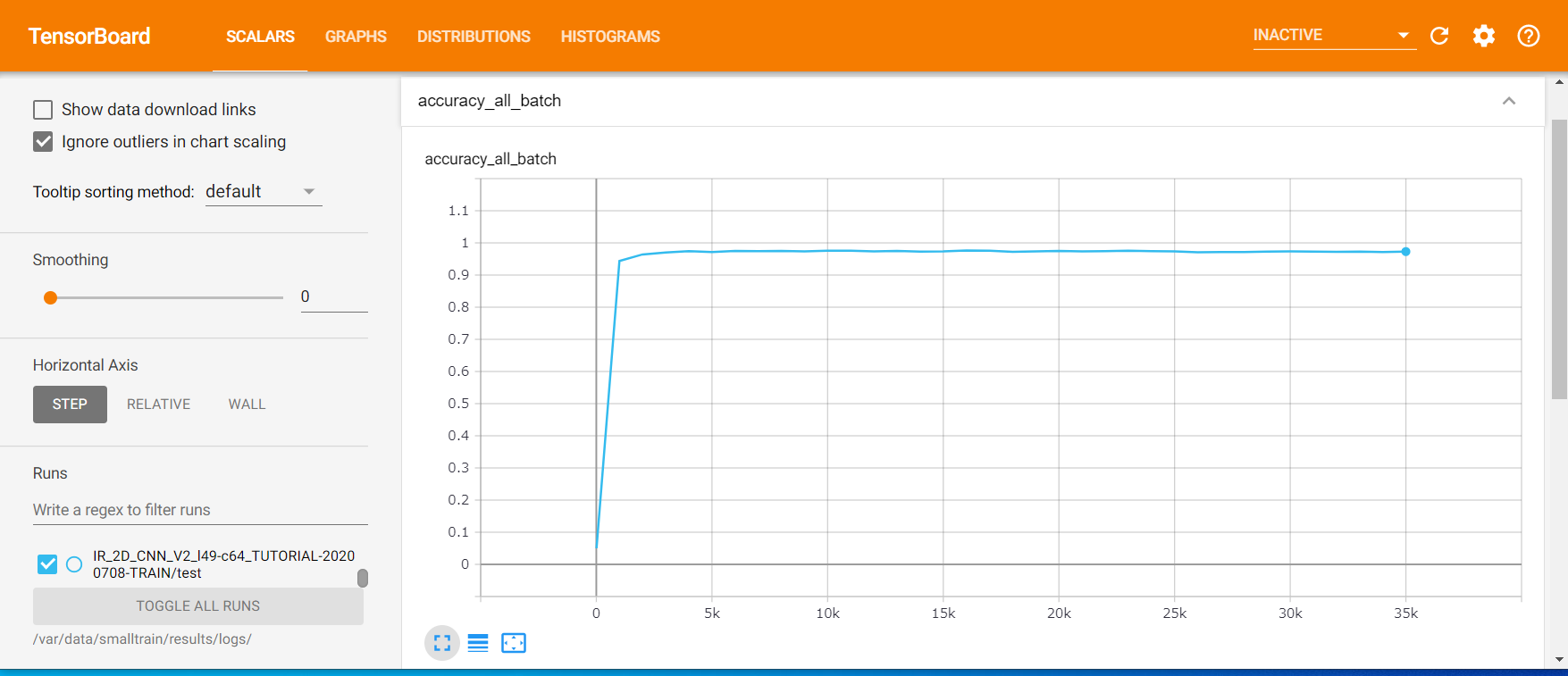
熊画像以外のデータ数が非常に多いため熊画像以外の精度が高く、test accuracyに大きく寄与しています。
test accuracyが最大なのはepoch15999ですが熊画像のみの精度が0.46と低くなっています。
epoch35999はtest accuracyは少し低いですが熊画像のみの精度が0.73と大きく向上していることが分かります。
今回はデモの設定をそのまま流用しているためチューニングすれば精度は上がるはずです。
画像とデータセット定義ファイルを準備するだけで簡単に画像認識モデル作成がきるのでぜひ試してみてください。