はじめに
マルチモーダルAIの中で特にテキスト・画像・動画からテキストを生成すること(Azure OpenAI GPT-4 Turbo with vision)の注目度が高いためここではそのユースケースについて整理します。
アップロードした画像に関するレコメンドを提供する
会社概要
instacartは北米でサービスを展開するオンライン食料品配送サービスを提供する企業です。ローカルのスーパーマーケットと提携しており、食料品や日用品をアプリやウェブサイトから注文、指定した場所まで配送してもらうことができます。
マルチモーダルAIの活用
現時点ではプレビュー中の機能ですが、以下の画像のようなオンラインショッピングサイトに写真をアップロードすると、写真の内容に沿って必要な食材を提案してくれる機能が開発されています。食料品に限らず、衣料品などオンラインショッピングサイトを持つ企業であれば同じような顧客の購入体験を向上する仕組みを導入することが期待されます。
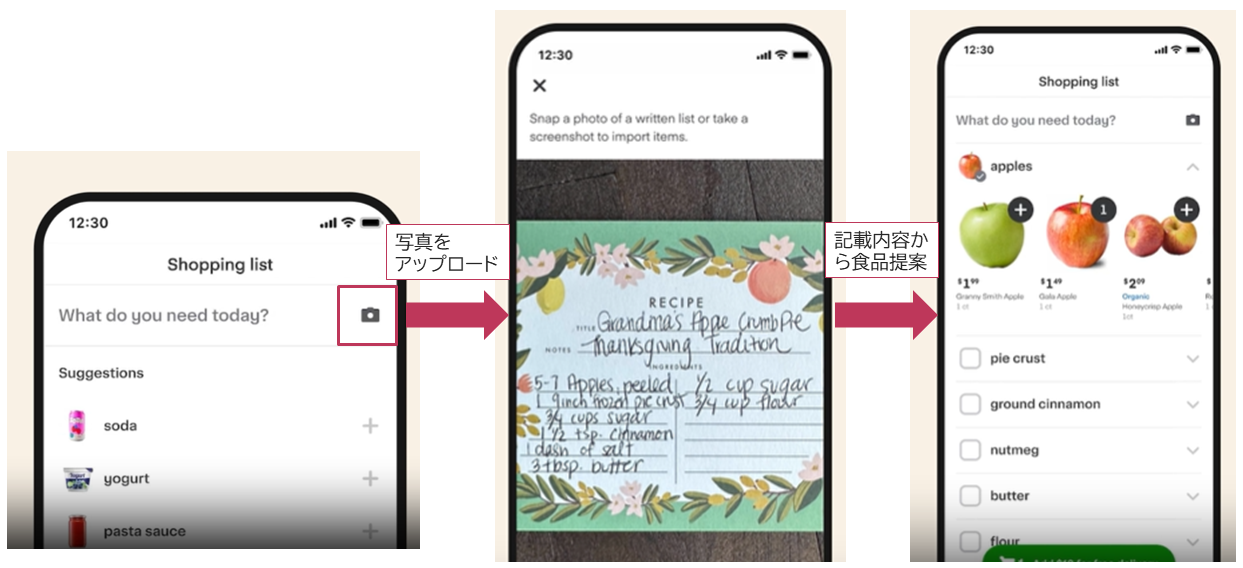
詳細はこちら(英語)で説明されています。
アップロードした画像や動画コンテンツの説明を生成し、コンテンツを分析する
会社概要
WPPはイギリスに本社を置き、100ヵ国以上に展開する世界最大級の広告サービスグループです。
マルチモーダルAIの活用
WPPでは動画の広告コンテンツの評価や最適化にマルチモーダルAIを活用しています。動画ファイルをシステムに入力すると、動画コンテンツの要約が生成されます。生成したテキスト形式の要約を独自のAIツールに与えることで、広告コンテンツの有効性について分析することを可能にしています。同社はこのような動画からテキストを生成するツールを2年以上検証していたが、その中でGPT-4 Turbo with Visionが一番よいツールだと説明しています。

詳細はこちら(英語)で説明されています。
まとめ
生成AIのインプットに画像や動画を活用した事例を整理しました。POCではありますが、すでに実用化が始まっていることがわかりました。今回まとめた事例からは(1)レコメンドを提供する、(2)コンテンツを分析するの2つの使い方が見えてきました。もう少し事例が増えてきたら他の使い方も整理してみたいと思います。