はじめに
生成AIで回答の品質を向上するためのナレッジを以下の軸でまとめています。前回の記事ではユーザーからのクエリや生成AIによる回答に有害なコンテンツが含まれていないかフィルタリングによってチェックする仕組みをAzure AI Content Safetyを活用しながら確認しました。今回は開発フェーズにおいて生成AIの回答を評価する方法について考えます。他の記事もセットでぜひチェックしてみてください。
本記事は筆者の調査した内容や試した成功/失敗の体験をリアルにお伝えすることで、Azureの活用ノウハウを共有すると共にもっと効率的な方法などあればディスカッションすることで改善していくことを目的にしています。システムの動作を保証するものでないことはご了承ください。
| カテゴリ | 記事の概要 | 公開予定日 |
|---|---|---|
| プロンプトエンジニアリング | 目的に合った回答を生成できるように制限を与える:システムメッセージエンジニアリング | 公開済み |
| プロンプトエンジニアリングでよい回答を得るために意識したい方針 | 公開済み | |
| 外部ソースのデータを使った回答(RAG) | 【Azure AI Search】外部ソースのデータを活用した生成AIの回答生成の仕組み | 公開済み |
| 【Azure AI Document Intelligence】PDFなど非構造型データから生成AIの回答を生成する | 公開済み | |
| 安全に生成AIを活用する | 【Azure AI Content Safety】有害なコンテンツを検出し生成AIの回答の信頼性を向上 | 公開済み |
| モデルの信頼性を評価する | 本記事 |
本記事でやりたいこと
生成AIが生成する回答は必ずしも正しいことが保証されず、間違いを含む場合もあります。生成AIの回答生成プロセスはブラックボックスになっているため正確性を100%保証できないという課題があります。そこで可能な限り信頼のおけるサービスを構築するために生成AIの回答を評価するプロセスが注目されています。今回はLangChainを活用した教師データの作成と教師データによる評価手法を試してみたので本記事でご紹介します。
生成AIの回答を評価しモデルの信頼性を分析する
LangChainを活用した生成AIの回答を評価するプロセスを例と共に紹介します。シナリオは以下Microsoft WhatTheHack(セルフ学習、トレーニングイベント開催用のコンテンツ集)を参照しています。この方法だと教師データを生成AIで生成しているため、評価が高い場合に教師データが正しければいいのですが、教師データが不足している場合に課題があると私は感じています。他に有効な手法などご存知であればコメントいただけると嬉しいです。
LangChainは生成AIアプリ開発を容易にすることを目的としたPython・JavaScript用のフレームワークで様々なモジュールを提供しています。LLM(大規模言語モデル)はプロンプトを基に回答を生成することができますが、”用途によって活用するLLMを変更したい”、”外部のデータソースを基にした回答を行いたい”、”他のサービスと連携したい”、”過去の会話を保持する仕組みを実装したい”などの様々な複雑な処理に容易に対応させるためにはオーケストレーションの役割をするLangChainが必要になってきます。今回ご紹介するQAGenerationChainもLangChainのモジュールの一つです。
本記事で紹介する評価プロセス
- 外部データソースのドキュメントからQAセットを生成AIで生成し、教師データとする(QAセットを事前に用意できる場合、このステップは省略できます)
- 外部データソースのドキュメントを基に、質問に対する生成AIによる回答を生成する
- 教師データと生成AIによる回答を比較し、生成AIの回答を評価する
本記事で紹介する評価プロセス全体像の概念図
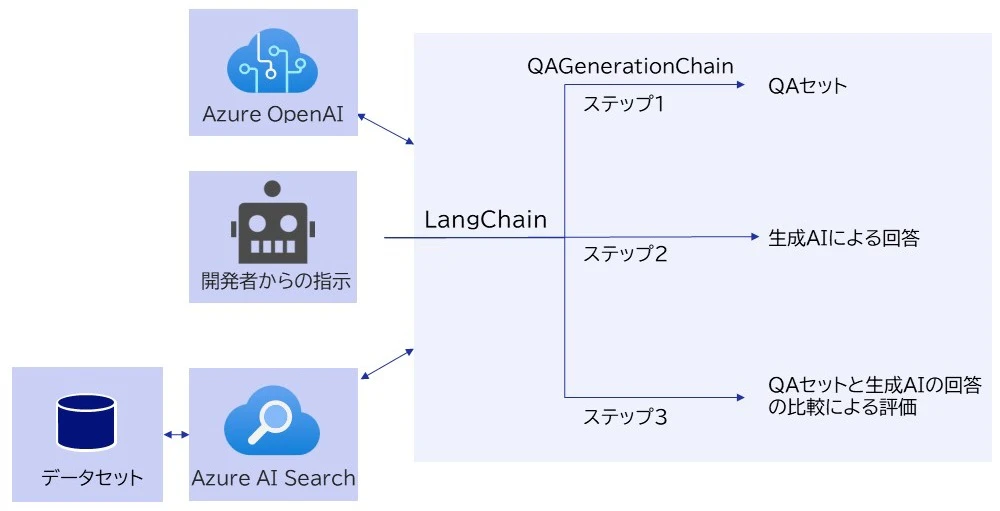
外部データソースのドキュメントからQAセットを生成AIで生成し、教師データとする
QAセットが既に存在する場合はこのステップは省略できます。与えられたデータからQAセットを生成するためにQAGenerationChainを活用します。データセットはCNNニュース記事(Hugging Faceから取得できます)を使用します。QAGenerationChainはテキストを与えるとテキストからQAセットを生成するモジュールで、今回のような外部ソースを活用した生成AIの回答を評価する目的で使われます。詳細はLangChainのドキュメントをご確認ください。
実装に必要なコードは前述のWhatTheHackのNotebookをご確認ください。この部分に関するコードは3. Evaluating Models for Truthfulness using GPT without Ground Truth Datasetsから記載されています。
※MicrosoftのトレーニングではAzureOpenAIのライブラリを使用していますが、私の環境ではGPT-3.5+AzureOpenAIライブラリで上手く動きませんでした。AzureChatOpenAIライブラリに変更するとプロンプトの解釈が向上したのか正しく動作しました。
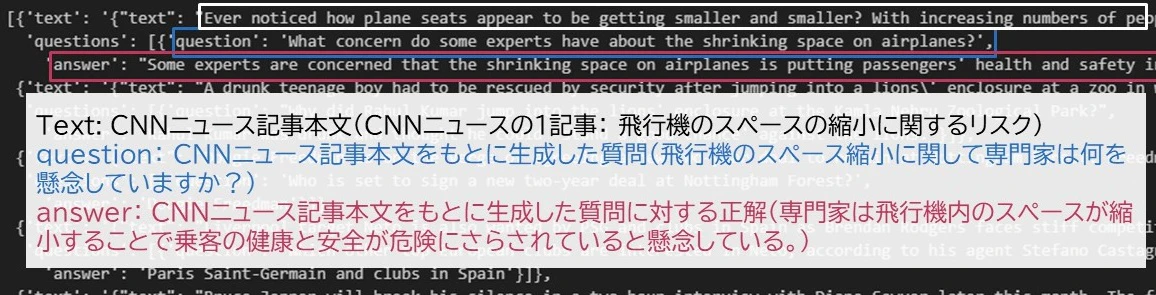
QAGenerationChainを実行すると各CNNニュースに対するQAセットが生成されました。QAGenerationChainには以下テンプレートプロンプト(簡単に要約すると、”与えられたテキストに対するQAセットを生成しJSON形式で返しなさい”)がデフォルトで設定されており、プロンプトの内容を実行した結果が実行結果として返ってきます。実行結果はJSONの形式で以下の内容が保存されています。こういったプロンプトや必要な処理を自分で用意せずとも簡単に活用できるところがLangChainなどのフレームワークのメリットです。
- Text:CNNニュース記事本文(図中白枠)
- question:CNNニュース記事本文をもとにQAGenerationChainで生成した質問(図中青枠)
- answer:CNNニュース記事本文をもとにQAGenerationChainで生成した質問に対する回答(図中赤枠)
QAGenerationChainに含まれるテンプレートプロンプト
You are a smart assistant designed to help high school teachers come up with reading comprehension questions.\nGiven a piece of text, you must come up with a question and answer pair that can be used to test a student\'s reading comprehension abilities.\nWhen coming up with this question/answer pair, you must respond in the following format:\n```{{"question": "$YOUR_QUESTION_HERE",\n"answer": "$THE_ANSWER_HERE"}}```\n\nEverything between the ``` must be valid json. Return RAW, VALID JSON.\n\nPlease come up with a question/answer pair, in the specified JSON format, for the following text:\n----------------\n{text}'
QAGenerationChainの実行結果
外部データソースのドキュメントを基に、問題に対する生成AIの回答を生成する
外部データソースのドキュメントを基に前節で生成したQAセットの問題に対する生成AIの回答を生成します。【Azure AI Search】外部ソースのデータを活用した生成AIの回答生成の仕組みで説明していますのでぜひご確認ください。実装に必要なコードは前述のWhatTheHackのNotebookをご確認ください。この部分に関するコードは3.2 Instantiate the Cognitive Search Indexから記載されています。
外部ソースのデータを活用して生成AIの回答を生成するコードを実行し、一覧で確認しやすいようにデータフレームにセットした結果が以下です。一覧で比較してみるとCNNニュース記事をもとにした生成AIの回答はQAGenerationChainで生成したQAセットに比べ、かなり詳細な説明が含まれていることがわかります。
- 1列目(question):前節で生成したQAセットの質問
- 2列目(truth_answer):前節で生成したQAセットの解答
- 3列目(prompt_answer):本節で生成した生成AIの回答
- 4列目(context):CNNニュース記事本文
実行結果

教師データと生成AIによる回答を比較し、生成AIの回答を評価する
前節までで得られた結果と以下のプロンプトを用い生成AIの回答を評価します。ここでの評価は特別なツールを使っているわけではなく、QAセットとして生成した質問と解答を正(教師データ)とし、生成AIが生成した回答と比較することによってA~Fの6段階で評価するといったプロンプトをLLMモデルに実行させます。
プロンプト
- Question:前節で紹介したquestionを入れます(QAセットで生成した質問です)
- Query:前節で紹介したtruth_answerを入れます(QAセットで生成した解答です)
- Predicted Query:前節で紹介したprompt_answerを入れます(生成AIの回答です)
- 生成AIによる回答がQAセットで生成した解答と意味的に同じか確認し、A~Fで評価し理由を述べなさい
You are trying to answer the following question from the context provided:
> Question: {question}
The correct answer is:
> Query: {truth_answer}
Is the following predicted query semantically the same (eg likely to produce the same answer)?
> Predicted Query: {prompt_answer}
Please give the Predicted Query a grade of either an A, B, C, D, or F, along with an explanation of why. End the evaluation with 'Final Grade: <the letter>'
> Explanation: Let's think step by step.
上記プロンプトから得られた結果は以下です。最終的な評価結果はBとランク付けられました。評価の理由としてまず冒頭で元の質問と同じ懸念事項に対して回答していることが評価されています。ただし全体的に多く提供された関連情報が詳細すぎる点で一つグレードを下げられてしまっています。
実行結果

QAセットを教師データとしていますのでQAセットの質がとても重要となることがわかります。評価結果がよい場合でもQAセットが期待する内容でなければ、評価結果も信頼性が損なわれる可能性があります。今回の方法(特にQAセットを自動生成した場合)は評価によって生成AIの信頼性を保証する使い方ではなく、評価結果が悪い場合に改善すべき回答になっている可能性が高いので、全体的な傾向の把握、最低限改善すべき回答を洗い出すという使い方に適していると思います。
すべてのQAセットに対してこのプロセスを繰り返すことで、外部データソースのドキュメントを基にした生成AIの回答品質の分析や質の悪い回答の洗い出しをすることが可能です。不正確な回答が多く行われているようであれば、検索の仕組みやプロンプトの書き方を見直す、或いはLLMのFoundationモデル自体を変更するなどの検討が必要です。
まとめ
生成AIの回答生成プロセスはブラックボックスになっており、生成AIの回答品質の評価は多くの企業で課題になっています。今回紹介した評価手法が全てのケースで活用できるわけではないですが、改善のポイントを分析するために有効にご活用いただくことはできるのではないかと思います。ただし本文中にも述べた通り正解データまで生成AIに生成させることは便利な一方で信頼性に不安を感じます。評価プロセスについても様々な研究や検証が重ねられていると思いますので、他の手法についても比較してみたいと思います。もしチェックすべきコンテンツなどご存じでしたらコメントなどで教えていただけると幸いです。