https://arxiv.org/abs/1611.03530
Submitted on 10 Nov 2016
Cited by 4835
Zhang, Google Brain
結論
-
DLはノイズデータを丸暗記できる
- 汎化はノイズ率に応じて悪化する
- 正則化は汎化の必要条件でも十分条件でもない
- データオーグメンテーションは表現学習を改善するので有効なことが多そう
- Batch Normalizationも有効に見える
-
丸暗記できる条件の理論証明
- データ数n、次元数dのとき、パラメタ数2n+dで活性化関数がReLuの2層のDLは、データを丸暗記できる
-
SDGで学習すると陰的にl2正則化が効いた解に辿り着く
- 無限の解の中から、SDGによってXXα=yを条件としたw=Xαが導かれる
- l2正則化の解はよい汎化を示すが、よりよい汎化の解があるため、汎化の説明としては不完全
感想
-
複数の大切な論点を考察順に提起している論文
- 2010年代はこういう論文が多い。精読中に頭の切り替えが必要
- 2020年代に入ると論文の論点は絞られている
-
汎化理解に関する当論文後のアップデート
- ノイズ率の影響はnoise transition matrixの仮定で後ほど公式化される
- 実務上のノイズ対応は色々提起されているが未解決
- 正則化の影響は、実践時にアーキテクチャごとに調べるのがよい
- キャパの公式化・理論証明はNTKの観点等から進んでいる(実証多く理論の途中)
- SDG・minimum norm・汎化の関係も研究進んでいる(実証多く理論の途中)
- 汎化プロセス理解に大切な別の論点
- 宝くじ仮説
- 層ごとの役割
- 点群(多様体)
- ノイズ率の影響はnoise transition matrixの仮定で後ほど公式化される
詳細
ノイズの丸暗記
- レーベルやインプットをランダム等のノイズにしてもDLが丸暗記と示した初実験
-
ノイズレーベルの学習は、インプットをガウス分布にした場合より学習に時間がかかる
- 自然に認められる潜在表現の点群が正解とずれている、と理解
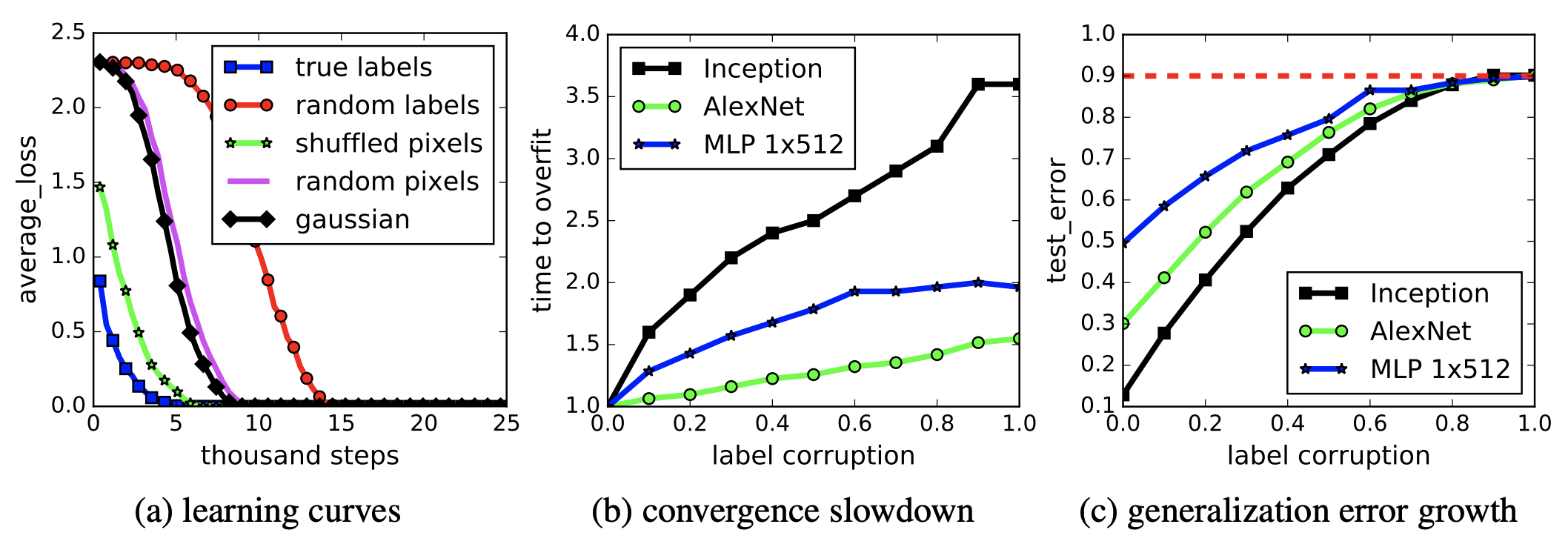
- 自然に認められる潜在表現の点群が正解とずれている、と理解
正則化の影響
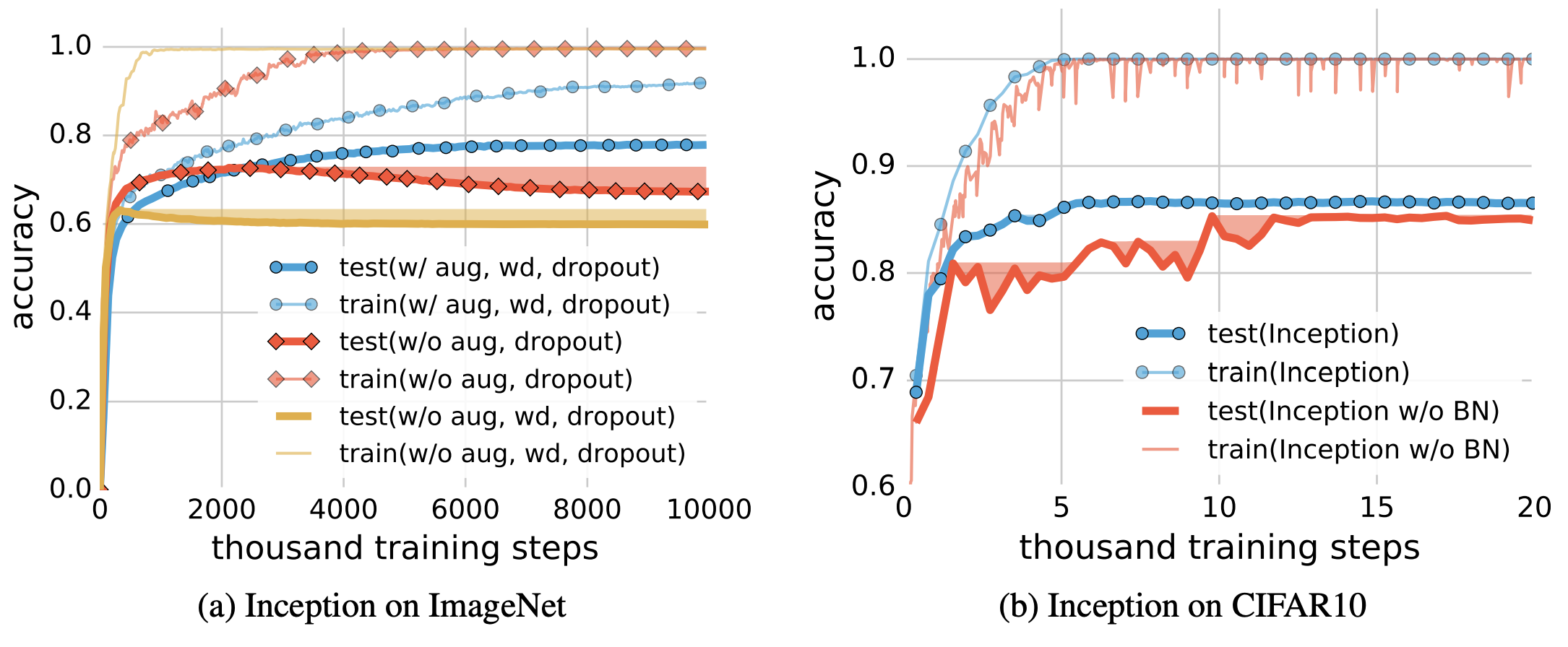
- データオーグメンテーションは表現学習を改善するので有効なことが多そう
- Batch Normalizationも有効に見える
丸暗記できる条件・理論証明
- 以下の2層ネットワークを想定する
- <a, x>-bが1層目(入力層)
- maxがReLU
- wjが2層目(出力層)
- w, bがn個で、aがd個のため、合計パラメタ数は2n+d個
- https://techblog.nhn-techorus.com/archives/16330
- 以下に示すフルランクのMatrix Aを作るために、この条件としている
- y=c(x)=Aw, Aij=max内とすると、任意のabでAをフルランクにできるので、wも解が存在 = 丸暗記

SDGによる陰的l2正則化
- 線形モデルで(Reluなし)、キャパ大きく無限の解が可能、と想定
- Xw = yとなる...1
- SDGの学習によりwt+1 = wt - ηexで更新される
- ηは学習率, eは損失, xはインプットデータ
- 学習の繰り返しで、w = Xαと表現される...2
- w0 = 0としている
- XXα=y(1, 2より)
- K=XXのカーネルマトリックスなので、l2を最小化する解wを導く
- https://www.iwanttobeacat.com/entry/2019/03/12/001051