はじめに
データベースに保存されている独自情報に類似した情報を取得し、生成AIに回答させる手段としてベクトル検索を用いたRAGを使用することが増えているのではないでしょうか。
この記事では、Azureが提供するNoSQLデータベース「Azure Cosmos DB for NoSQL」を使用してベクトル検索を実装する方法について説明します。
Azure CosmosDB for NoSQLとは
Azure Cosmos DB for NoSQLは、Auzreが提供するNoSQLデータベースです。
Azure公式では、以下のように説明されています。
Azure Cosmos DB for NoSQL では、構造化照会言語 (SQL) を JSON クエリ言語として使用してクエリを記述することで、データに対するクエリを実行できます。
Azure Cosmos DB for NoSQLを使用することで、JSON形式のデータをSQLライクに操作することができます。
Azure CosmosDB for NoSQLでのベクトル検索
2024年5月に開催されたMicrosoft Build 2024 で、Azure CosmosDB for NoSQLにベクトル検索が追加されました。
Azure公式では、以下のように説明されています。
Azure Cosmos DB のベクトル検索は、WHERE 句を使用して、サポートされている他のすべての Azure Cosmos DB NoSQL クエリ フィルターやインデックスと組み合わせることができます。 これにより、ベクトル検索をアプリケーションに最も関連性の高いデータにすることができます。
では、実際にAzure CosmosDB for NoSQLを使用してベクトル検索を実装してみましょう。
開発環境のセットアップ
概要説明
大まかに以下の流れで進めます。
- Azureアカウントの作成
- Azure Cosmos DB for NoSQL アカウントの作成
- Azure Cosmos DB for NoSQL におけるベクトル検索の有効化
- Azure CosmosDB for NoSQL におけるコンテナ・データベースの作成・ベクトルポリシーの設定
- 仮想環境の設定
- バックエンドの実装
- フロントエンドの実装
Azureアカウントの作成
今回は説明を割愛しますが、Azureアカウントをお持ちでない方は以下の公式ページを参考にアカウントを作成してください。
Azure Cosmos DB for NoSQL アカウントの作成
公式ページの「アカウントを作成する」からCosmos DBのアカウントを作成してください。
Azure Cosmos DB for NoSQL におけるベクトル検索の有効化
公式ページを参考にCosmos DBのベクトル検索を有効化します。
ここで、ベクトル検索を有効化しておくことで、後続の手順でコンテナ作成時にベクトルポリシーを設定することができます。
Azure CosmosDB for NoSQL におけるコンテナ・データベースの作成・ベクトルポリシーの設定
以下を参考にCosmos DBのコンテナ・データベースを作成し、ベクトルポリシーを設定します。
2024/12現在、作成したベクトルポリシーは変更できないため、ご注意ください。ベクトルポリシーを変更する必要がある場合、コンテナの再作成が必要となります。
サンプルプロジェクトのシステム概要とディレクトリ構成
概要
新規システム検討時に、既存の社内の類似システムの情報を知りたいと思うことがあるのではないでしょうか。
今回は新規システム検討時に、検討中のシステムの説明を入力することで、類似システムを検索するサンプルプロジェクトを作成しました。
類似システムの検索には、Azure Cosmos DBを使用したベクトル検索を用いています。
本プロジェクトでは、以下の2機能を実装しています。
DB登録機能
- フロントエンドではCosmos DBにデータを登録する画面を作成し、
登録を押下することでバックエンドの機能を呼び出します。 - バックエンドでは入力された
システム、システム説明、システム説明をOpenAIのAPIを用いてエンべディング化したベクトル値のセットでCosmosDBに登録しています。
ベクトル検索機能
CosmosDBからベクトル検索を行うときは、システム説明(今回はサンプル値としてインスタグラムを使用します)に相当する文言を入力します。
入力した文言をエンべディング化した値と類似度の高い上位3項目をCosmosDBから取得します。
ディレクトリ構成
ai-arch-chat/
├── backend/
│ ├── app/
│ │ ├── domain/
│ │ │ ├── services/
│ │ │ │ ├── register_service.py
│ │ ├── infrastructure/
│ │ │ ├── models/
│ │ │ │ ├── system_model.py
│ │ │ ├── repositories/
│ │ │ │ ├── cosmos_db_client.py
├── frontend/
│ ├── src
│ │ ├── page_list
│ │ │ ├── register_page.py
│ │ ├── streamlit_app.py
├── .env
仮想環境の有効化手順
筆者はMacを使用していますが、Windowsでも同様の手順で進めることができます。
- ai-arch-chatディレクトリに移動
cd ai-arch-chat - 仮想環境の作成
python -m venv .fullstack-venv - 仮想環境の軌道
source .fullstack-venv/bin/activate - 依存パッケージのダウンロード
pip install -r requirements.txt
requirements.txtには以下のパッケージが含まれています。
- requirements.txt
# backend
openai
pydantic_settings
load_dotenv
azure-cosmos
# frontend
streamlit
python-dotenv
.envファイルには以下の環境変数をします。
OpenAIのAPIキーの設定や、DBのアカウントキーやエンドポイント、データベース名、コンテナ名を設定してください。
.env
LIST_PAGE="システム一覧"
REGISTER_PAGE="システム登録"
SEARCH_ARCHITECHURE_PAGE="アーキテクチャ検討"
OPENAI_API_KEY = "{OpenAIのAPIキー}"
COSMOSDB_ENDPOINT = "https://{CosmosDBアカウント名}.documents.azure.com:443/"
COSMOSDB_KEY = "{CosmosDBのアカウントキー}"
DATABASE_NAME = "{CosmosDBのデータベース名}"
CONTAINER_NAME = "{CosmosDBのコンテナ名}"
実装サンプル
フロントエンド
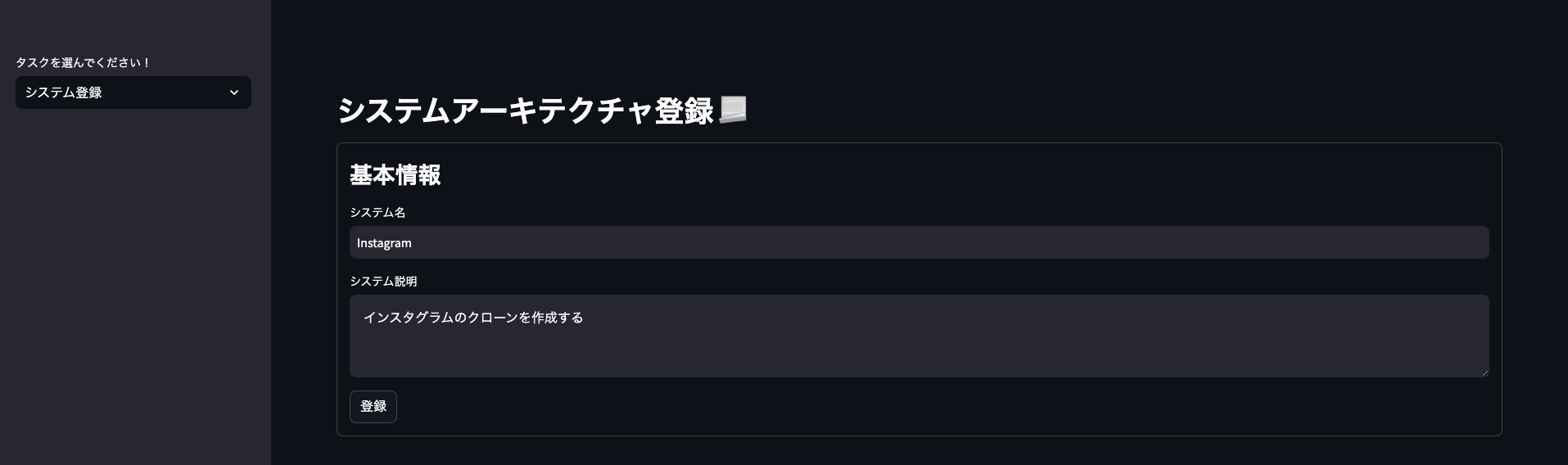
今回は、Streamlitを使用してCosmos DBにデータを登録する画面を作成します。
システム名とシステム概要を入力し、バックエンドの登録機機能を呼び出すことでCosmos DBにデータを登録します。
最終的には、以下のような画面が表示されます。
データ登録画面で値を入力すると、システム名とシステム概要に加え、システム概要をベクトル化した値がCosmos DBに登録されます。
frontend/src/streamlit_app.py(画面のエントリーポイント)
import os
import streamlit as st
from dotenv import load_dotenv
from page_list import register_page # noqa: E402
load_dotenv()
def main():
st.set_page_config(
page_title="Mr.Architect",
page_icon="🤖",
layout="wide"
)
# デフォルトのヘッダーを非表示にするCSS
hide_streamlit_style = """
<style>
#MainMenu {visibility: hidden;}
header {visibility: hidden;}
footer {visibility: hidden;}
</style>
"""
st.markdown(hide_streamlit_style, unsafe_allow_html=True)
register_page_name = os.getenv('REGISTER_PAGE')
# サイドバーでページ選択
task = st.sidebar.selectbox(
'タスクを選んでください!',
options=[
register_page_name],
index=0
)
if task == register_page_name:
register_page.run_page()
if __name__ == '__main__':
main()
frontend/src/page_list/register_page.py(データ登録画面)
import streamlit as st
from dotenv import load_dotenv
from typing import Dict
from backend.app.domain.services.register_service import RegisterService
load_dotenv()
def validate_system_data(data: Dict) -> tuple[bool, str]:
"""システムデータのバリデーション"""
required_fields = ['system_name', 'description']
# 必須フィールドチェック
for field in required_fields:
if field not in data:
return False, f"必須フィールドが不足しています: {field}"
return True, ""
def run_page():
st.header("システムアーキテクチャ登録 📃")
# サービスの初期化
register_service = RegisterService()
with st.form("architecture_form"):
# 基本情報
st.subheader("基本情報")
system_name = st.text_input("システム名", placeholder="例: 注文管理システム")
description = st.text_area("システム説明", placeholder="システムの概要、目的、主要機能などを記述してください")
submitted = st.form_submit_button("登録")
if submitted:
try:
# リクエストデータの作成
architecture_data = {
"system_name": system_name,
"description": description
}
# バリデーション
is_valid, error_message = validate_system_data(architecture_data)
if not is_valid:
st.error(error_message)
return
# 登録処理
with st.spinner("システムを登録中..."):
# 第二引数でベクトル化するプロパティを指定する
result = register_service.register_architecture_vectorize(architecture_data, "description")
# 成功メッセージとレスポンスの表示
st.success("システムが正常に登録されました!")
# 登録されたデータの表示
with st.expander("登録されたデータ", expanded=True):
st.json(result)
except Exception as e:
st.error(f"エラーが発生しました: {str(e)}")
if __name__ == "__main__":
run_page()
バックエンド
登録機能と検索機能は、Azure Cosmos DB for NoSQLのPython SDKを使用して実装しています。
cosmos_db_clientを実行することで、ベクトル検索の結果をコンソールで確認できるようになっています。
backend/app/domain/services/register_service.py
import os
from typing import Dict, List
from dotenv import load_dotenv
from backend.app.infrastructure.repositories.cosmos_db_client import CosmosDBClient
from backend.app.domain.services.embedding_service import EmbeddingService
class RegisterService:
def __init__(self):
self.cosmos_client = CosmosDBClient()
self.embedding_service = EmbeddingService(os.environ.get('OPENAI_API_KEY'))
def get_embedding(self, text: str) -> List[float]:
"""
テキストをベクトル化
Args:
text (str): ベクトル化するテキスト
Returns:
List[float]: ベクトル化されたリスト
"""
return self.embedding_service.get_embedding(text)
def register_architecture_vectorize(self, system_data: Dict, vectorize_property: str = 'description') -> Dict:
"""
システムアーキテクチャを登録し、結果を辞書形式で返すサービス
Args:
system_data (Dict): 登録するシステム情報
vectorize_property (str): ベクトル化する対象のプロパティ名(デフォルト: 'description')
Returns:
Dict: 登録結果を辞書形式で返す
"""
vector = self.get_embedding(system_data[vectorize_property])
vector = vector.tolist()
system_model = self.cosmos_client.register_system_architecture(system_data, vector)
return system_model
backend/app/domain/services/embedding_service.py
import numpy as np
from openai import OpenAI
import pickle
from pathlib import Path
import hashlib
class EmbeddingService:
def __init__(self, api_key: str, cache_dir: str = "embeddings_cache"):
self.client = OpenAI(api_key=api_key)
self.cache_dir = Path(cache_dir)
self.cache_dir.mkdir(exist_ok=True)
def _get_cache_path(self, text: str) -> Path:
"""キャッシュファイルのパスを生成"""
text_hash = hashlib.md5(text.encode()).hexdigest()
return self.cache_dir / f"{text_hash}.pkl"
def get_embedding(self, text: str, use_cache: bool = True) -> np.ndarray:
"""テキストのembeddingを取得(キャッシュ対応)"""
cache_path = self._get_cache_path(text)
if use_cache and cache_path.exists():
with open(cache_path, 'rb') as f:
return pickle.load(f)
response = self.client.embeddings.create(
model="text-embedding-3-small",
input=text,
dimensions=1536
)
embedding = np.array(response.data[0].embedding)
if use_cache:
with open(cache_path, 'wb') as f:
pickle.dump(embedding, f)
return embedding
backend/app/infrastructure/repositories/cosmos_db_client.py
from datetime import datetime
import os
import uuid
from azure.cosmos import CosmosClient, exceptions
from typing import List
from dotenv import load_dotenv
from typing import Dict
class CosmosDBClient:
def __init__(self):
"""
CosmosDB クライアントの初期化
"""
self.endpoint = os.environ.get('COSMOSDB_ENDPOINT')
self.database_name = os.environ.get('DATABASE_NAME')
self.container_name = os.environ.get('CONTAINER_NAME')
self._client = None
def register_system_architecture(self, system_data: Dict, vector: List[float]) -> Dict:
"""
システム情報を登録
Args:
system_data (Dict): 登録するシステム情報の辞書
vector (List[float]): ベクトル
Returns:
Dict: 登録されたシステム情報のレスポンス
Raises:
ValueError: システム情報の登録中にエラーが発生した場合
"""
try:
cosmos_item = {
"id": str(uuid.uuid4()),
**system_data,
"description_vector": vector,
"created_at": datetime.utcnow().isoformat(),
"updated_at": None,
"type": "dummy_system_architecture"
}
self.container = self.get_container()
created_item = self.container.create_item(body=cosmos_item)
return created_item
except ValueError as e:
raise
except Exception as e:
raise ValueError(f"Error creating system: {str(e)}")
def _get_client(self):
if not self._client:
key = os.environ.get('COSMOSDB_KEY')
if not key:
raise ValueError("COSMOSDB_KEY is required")
self._client = CosmosClient(self.endpoint, credential=key)
return self._client
def get_container(self):
try:
client = self._get_client()
database = client.get_database_client(self.database_name)
return database.get_container_client(self.container_name)
except exceptions.CosmosResourceNotFoundError as e:
raise ValueError(f"Container or database not found: {str(e)}")
except Exception as e:
raise ValueError(f"Error getting container: {str(e)}")
def search_similar_documents(self, query_vector: List[float], top_k: int = 3) -> List[Dict]:
"""
類似ドキュメントをベクトル類似度を使用して検索する。
Args:
query_vector: List[float]: 検索クエリのベクトル
top_k (int, optional): 取得する類似ドキュメントの最大数。デフォルトは3。
Returns:
List[Dict]: 類似ドキュメントのリスト。
Raises:
ValueError: 検索中にエラーが発生した場合。
"""
try:
query = {
'query': """
SELECT TOP @top_k
c.id,
c.system_name,
c.description,
c.description_vector,
VectorDistance(c.description_vector, @queryVector) as similarity
FROM c
WHERE IS_ARRAY(c.description_vector)
ORDER BY VectorDistance(c.description_vector, @queryVector)
""",
'parameters': [
{'name': '@top_k', 'value': top_k},
{'name': '@queryVector', 'value': query_vector}
]
}
self.container = self.get_container()
results = list(self.container.query_items(
query=query['query'],
parameters=query['parameters'],
enable_cross_partition_query=True
))
return results
except Exception as e:
raise ValueError(f"Error in search_similar_documents: {str(e)}")
if __name__ == "__main__":
from backend.app.domain.services.embedding_service import EmbeddingService
try:
load_dotenv()
embedding_service = EmbeddingService(os.environ.get('OPENAI_API_KEY'))
required_env_vars = ['COSMOSDB_ENDPOINT', 'COSMOSDB_KEY', 'DATABASE_NAME', 'CONTAINER_NAME']
for var in required_env_vars:
if not os.environ.get(var):
raise ValueError(f"Missing required environment variable: {var}")
cosmos_client = CosmosDBClient()
query_text = "インスタグラム"
query_vector = embedding_service.get_embedding(query_text)
query_vector = query_vector.tolist()
result = cosmos_client.search_similar_documents(query_vector)
# 結果の表示
print(f"取得件数: {len(result)}")
for system in result:
try:
similarity_score = float(system.get('similarity', 0))
print(f"""
Found system: {system.get('system_name', 'No name')}
Similarity Score: {similarity_score:.4f}
Description: {system.get('description', 'No description')}
-------------------""")
except ValueError as e:
print(f"Error formatting similarity score: {e}")
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
backend/app/infrastructure/models/system_model.py
from typing import Optional, List, Dict
from datetime import datetime
from pydantic import BaseModel
class DummySystemModel(BaseModel):
id: str
system_name: str
description: str
結果
サンプルとして、"インスタグラム"という文言をベクトル化した値をインプットにCosmos DBからベクトル検索してします。
ベクトルDB側に保存されたデータに類似したデータが取得取得できました。
今回はシステム説明に相当する文字数が少なかったため、システム説明に相当するDescriptionプロパティの文字数が少ないデータが取得されたのではないかと考えています。
ベクトル検索の実行例
$ python3 -m backend.app.infrastructure.repositories.cosmos_db_client
INFO:__main__:取得件数: 3
INFO:__main__:
Found system: instagram
Similarity Score: 0.4811
Description: instagramのクローンを作成します
-------------------
INFO:__main__:
Found system: instagram
Similarity Score: 0.4597
Description: instagramのクローンを作成します。ダミーデータ
-------------------
INFO:__main__:
Found system: PhotoShare
Similarity Score: 0.4560
Description: PhotoShareはInstagramライクな写真共有サービス。
-------------------
まとめ
Azure Cosmos DB for NoSQLを使用したベクトル検索の実装について説明しました。
今後Azure Cosmos DB for NoSQLを使ったベクトル検索を実装することがありましたら、参考にしていただければ幸いです。