AWS画像認識サービスを調べたり触る機会がありましたので、ちょっとした解説です。
前提として、以下があるので、ご注意ください。
- 動作確認は、主にlinux(ubuntu)を使い、awsのcliやpythonライブラリ(boto3)を活用しました。
- 2020年1月頃に調べたり動作確認した内容が含まれています。
目次
1.はじめに
2.AWS画像認識サービス
2.1.RekognitionとRekognition Videoを触ってみた
2.2.好みの画像分析が作成できるRekognitionカスタムラベルとSageMaker
3.おわりに
a.参考リンク
1. はじめに
人の行動を分析することをやりたくて、有名で身近にあるAWSの画像認識サービスを調べていきました。
画像から人や物(服や帽子も)が検出され、ものの名前や、顔のオブジェクトの座標や年齢等のデータが得られるので、
得られたデータをもとに、マーケティング等の色々な分析や、お店でのVIPお客様対応等の支援等、幅広い活用が聞かれます。
精度的に、どうしても判断しにくい画像になってくると、検出漏れや誤検出、というのはありますので、
そういったことが起きにくくするか、起きても許容される形で活用するのが、難易度が低く進めやすいかと思います。
例えば、人を特定しても、犯人と断定せず、容疑者として抽出し、管理者等が確認して、決定づける。という感じですね。
ちなみにですが、私は、オフィスで人同士の距離が近いかどうかを、推定する検証を行いました。
人の顔検出データ(顔パーツの座標等)をもとに大まかな位置を推定し、DataBaseに記録し、ユーザによる確認や追跡を支援する。といった感じです。
2. AWS画像認識サービス
画像認識の中身の話になりますが、AWSの画像認識のサービスには、主に、以下があります。
| サービス名 | 概要 | 認識対象 | 備考 |
|---|---|---|---|
| Rekognition | 静止画の分析 | ラベル、カスタムラベル(任意)、コンテンツの節度、テキスト抽出、顔検出と分析、顔検出と検証、有名人の認識、Personal Protective Equipment (PPE) の検出 | SageMakerと同様にユーザが画像認識モデルの作成が可能(カスタムラベル) |
| Rekognition Video | 映像の分析 | ラベル、顔検出と分析、顔検索、人物追跡、不適切コンテンツ、有名人の認識、テキスト検出 | リアルタイムのライブストリーミング分析の場合、顔検出や顔探索のみのようです |
| SageMaker | ユーザが何を分析するかのモデルを作成し、そのモデルを活用して画像の分析 | ユーザ作成モデルによる画像認識(任意) |
2.1. RekognitionとRekognition Videoを触ってみた
以下のようなイメージの構成で、画像認識を試しました。
EC2のローカルにある画像ファイルを、Rekognitionへ送信(バイト配列で)して画像認識。
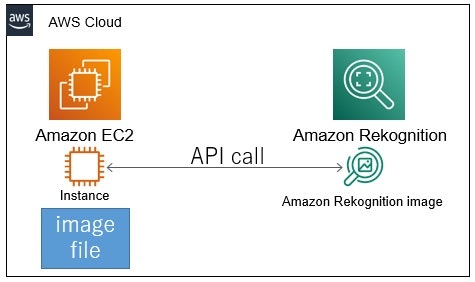
S3にある画像ファイルを、Rekognitionで画像認識。
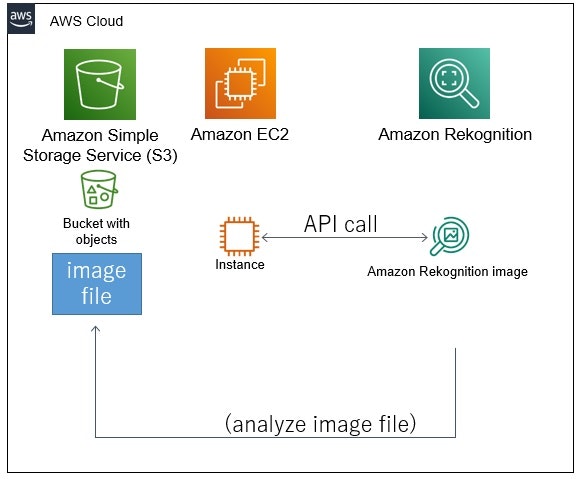
S3にある映像ファイルを、Rekognition Videoで画像認識。
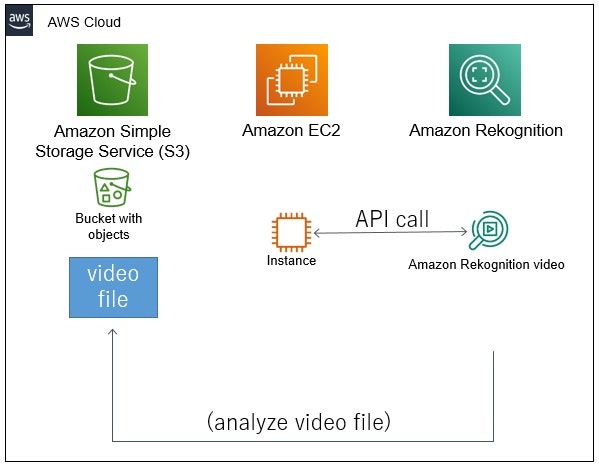
S3にある映像ファイルをKinesis Video Streamsにアップロードして、Rekognition Videoで画像認識。(Kinesis Video Streamsを使うことで、カメラ映像もリアルタイムで画像認識させることも可能です)

S3に画像ファイルをPUTし、S3のPUTイベントコールから実行されたLambda関数から、Rekognitionで画像認識。
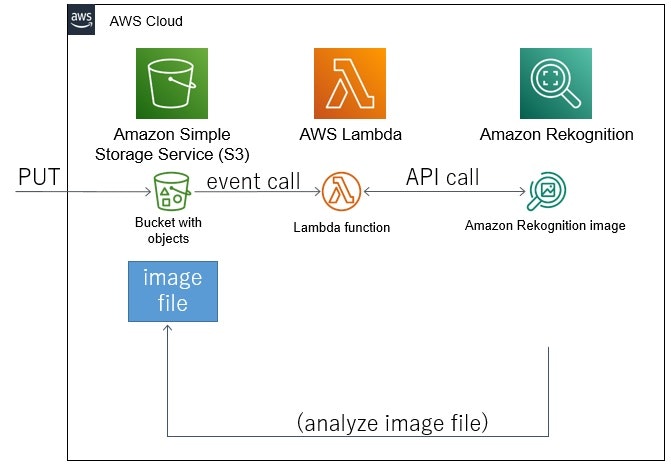
これらのように、簡単に試した範囲ですが、
Rekognitionの認識結果について、
顔検出と分析(detect-faces)のデフォルトモードでは、顔の矩形座標や、顔パーツ(5点:両目、鼻、口の左右の端)の座標、あと顔向きや輝度、シャープネス、顔のスコアの情報が取得できました。
そして、詳細モード(ALL)では、上記に加え、顔のパーツが他25点(眉や顎等含め)、年齢幅、性別、スマイルや感情等、口や目等、ひげや眼鏡といった情報も取得できました。
ラベルのdetect-labelsでは、シーンのスコアや、人や服等だと矩形座標やスコアが取得できました。
Rekognition Videoの認識結果について、
顔検出やラベルでは、2FPS(約500ms毎)で、フレーム画像から顔やラベルを検出をした結果が取得できました。
人物追跡では、顔は5FPS(約200ms毎)で、人は15FPS(約66ms毎)で、フレーム画像から顔や人検出した結果が取得できました。
なお、人には、番号が振られており、番号により人の追跡を見分けられるようです。そして、顔は、検出された人に紐づいていました。
RekognitionやRekognition Videoの入力サイズについて、
映像の連続するフレーム画像を、リアルタイムに順次処理できるか気になり、入力方法を調べたのですが、画像の入力方法によって許容サイズが異なるようです。
以下のように大きいサイズを指定したい場合、S3経由でなければいけません。
| サービス名 | 入力方法 | 許容サイズ | 備考 |
|---|---|---|---|
| Rekognition | S3 | 15 MB | |
| Rekognition | バイト配列 | 5 MB | |
| Rekognition Video | S3 | 10 GB か 6 時間 | |
| Rekognition Video | Kinesis Video | なし※1 | リアルタイム対応可能 |
| ※Rekognition Videoの場合、映像ファイルをバイト配列で送信して入力する方法はできなかったです。S3経由でした。 | |||
| ※1 長時間は未検証ですが記載を見つけられなかったので制限がないと思われます。 |
また解像度についても、画像認識に影響があるようです。
QAにも、RekognitionやRekognition Videoについての記載があり、それぞれ以下のようです。
Rekognitionの解像度について、
Amazon Rekognition は縦横両方のサイズが 80 ピクセル以上の画像に対応していますが、QVGA (320x240) より解像度が低い場合は顔や物体、不適切なコンテンツを認識しない可能性が高くなります。
上記引用の通りですが、
縦横80ピクセル以上で、VGA (640x480) 以上が推奨されてます。
QVGA (320x240) 未満は、顔等の対象を認識しなくなる可能性が高いそうです。
通常は、画像内に表示されている最小の物体または顔が、画像の短い辺のサイズ (ピクセル) の 5% 以上になるようにしてください。
こちらも、上記引用の通り、
検出対象(物体や顔等)が、画像の縦か横の短いピクセルサイズの、5%以上必要のようです。
実際に、360°カメラの解像度6080x3040で顔検出しましたが、小さい顔が検出されず、画像の解像度を小さく変更すると検出されましたので、対象によっては事前に加工が必要ですね。
Rekognition Videoの解像度について、
推奨の解像度は 720p (1280×720 ピクセル) から 1080p (1920x1080 ピクセル) までです。他のアスペクト比における同等の解像度でも最適な結果が得られます。解像度が低すぎる場合 (QVGA または 240p) や低画質な動画の場合は、結果の質にマイナスの影響が出る可能性があります。
上記引用の通り、
推奨の解像度があり、解像度が低すぎる場合だと、よくないようです(検出漏れ等の精度に影響すると思われます)。
2.2. 好みの画像分析が作成できるRekognitionカスタムラベルとSageMaker
好きなものを画像認識させるといったカスタマイズができるのは、Rekognitionのカスタムラベルと、SageMakerのようです。
画像認識モデル作成に注目すると、それぞれ以下の違いがあるようですね。(私は触ったことがないので、あくまでも資料を見たり、聞いた話です。)
| サービス名 | 特徴 | 備考 |
|---|---|---|
| Rekognitionカスタムラベル | ラベル付け等のRekognitionの既存機能をベースに、少ないデータで効率的な画像認識モデルを作成 | SageMakerのラベル付け支援(Ground Truth)も利用可能 |
| SageMaker | 開発者やデータサイエンティスト向けの各種ツール(統合開発環境(Studio)、ラベル付け支援(Ground Truth)、エッジデバイス管理(Edge Manager)等)を活用し、高精度の画像認識モデルを作成 |
課金については、以下の違いがあります。
Rekognitionは、推論リソースの数と時間当たりで決まっているのですが、SageMakerは、EC2のインスタンスを起動することもありインスタンスタイプに依存した料金となるようです。
Rekognitionは、開始すると時間当たり$4程度かかってしまいますが、SageMakerの場合、EC2インスタンスタイプによって料金が決まるため、
例えばですが、1時間に数回で、24時間監視したいといった、あまり頻繁に映像分析を行わない場合は、お得に活用できそうです。
| サービス名 | フェーズ | 料金 |
|---|---|---|
| Rekognitionカスタムラベル | 学習 | $1/時間 |
| Rekognitionカスタムラベル | 画像認識 | $4/時間*推論リソース数 |
| SageMaker | 学習・分析・画像認識 | EC2インスタンスタイプに依存 |
4. おわりに
というように複数のサービスがあり、どれを活用していくか、悩ましいところがありますが、最初は、Web上にデモも用意され、すぐ使えるRekognitionの静止画の分析(ラベル検出等)を試してみるのがよさそうです。
次に、既存のRekognitionが画像認識に対応していなければ、カスタムラベルで、画像認識モデルを作成し利用したり。
凝った分析や最適な精度や料金によるサイジング等、突き詰めていく場合、SageMakerを利用する。といったユーザの活用スタイルによって順に進めていくのがよさそうに思えています。
今後、自分でも、カスタムラベルで好みの画像認識モデルを作成してみたいと思います。