Kendra
AWS Kendraとは
Amazon Kendra は、機械学習を原動力とする高精度で使いやすいエンタープライズ検索サービスです。Kendra は、ウェブサイトおよびアプリケーションに強力な自然言語検索機能を提供するため、エンドユーザーは企業全体に散在する膨大な量のコンテンツ内で必要な情報をより簡単に見つけることができます。
re:Invent 2019で発表された。
エンタープライズ検索って言って社内ドキュメントの中から、欲しい情報を簡単に探せるよっていうサービスっぽい。日本語はまだ未対応。
簡単にデータソースの設定ができて、深層学習モデルをアクティブに再訓練して、検索の正確性がどんどん上がっていく、と。
S3にファイルアップロード
今回はデータソースはS3を使うので、適当にネットから拾ってきたデジカメの取扱説明書を置いておく。英語しか対応していないので英語版。
日本語対応するまでは実用するとしてもドキュメントを英語に変換する必要がある(AWS Translateと使ってアップロード時に翻訳変換かければいいかもしれないけど精度は不明)
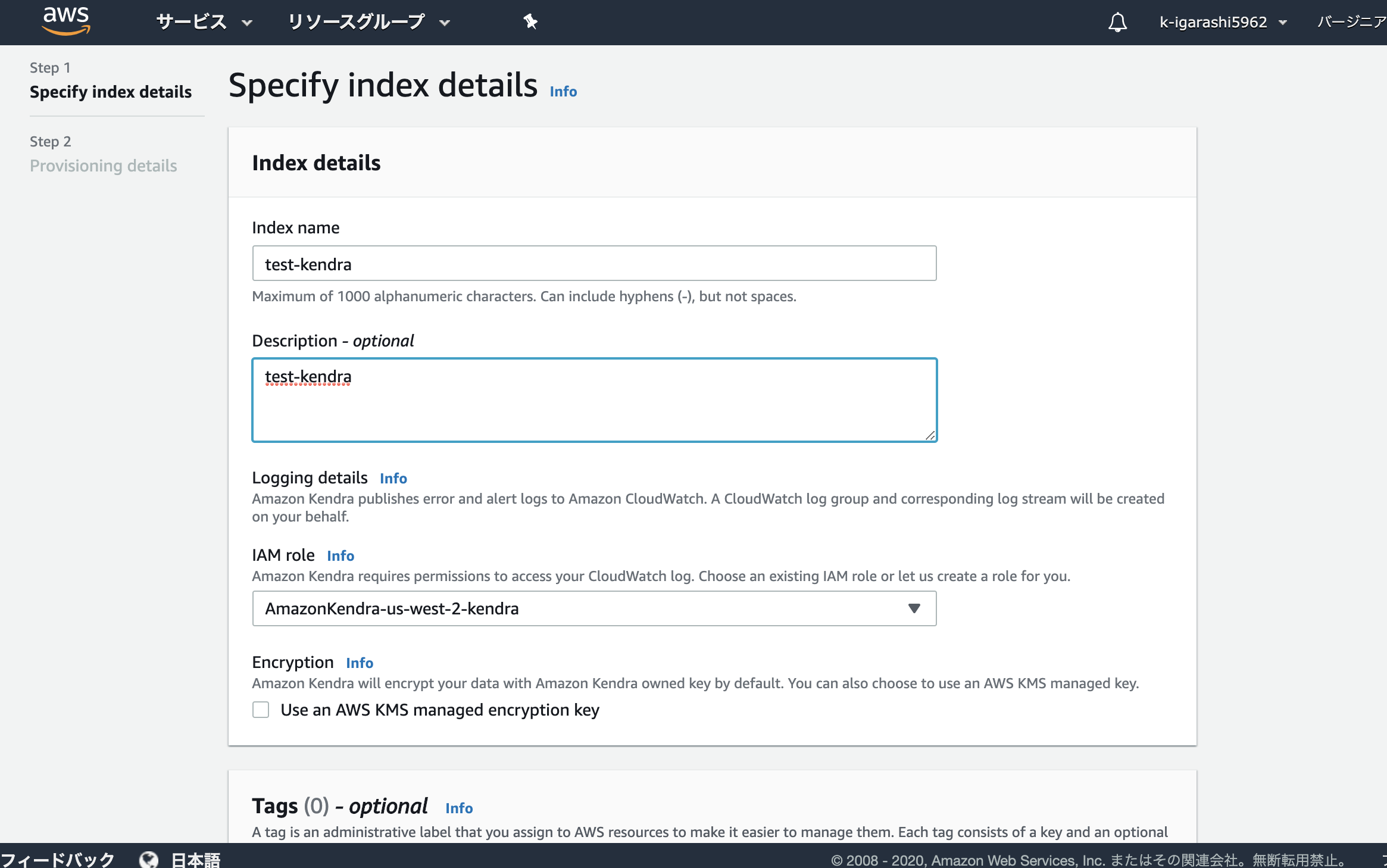
INDEX作成
Kendraは日本リージョンないのでus-west-2を選択。
Roleの設定とかポチポチやるだけ。30分くらいかかるみたい。ほっといたら出来てた。
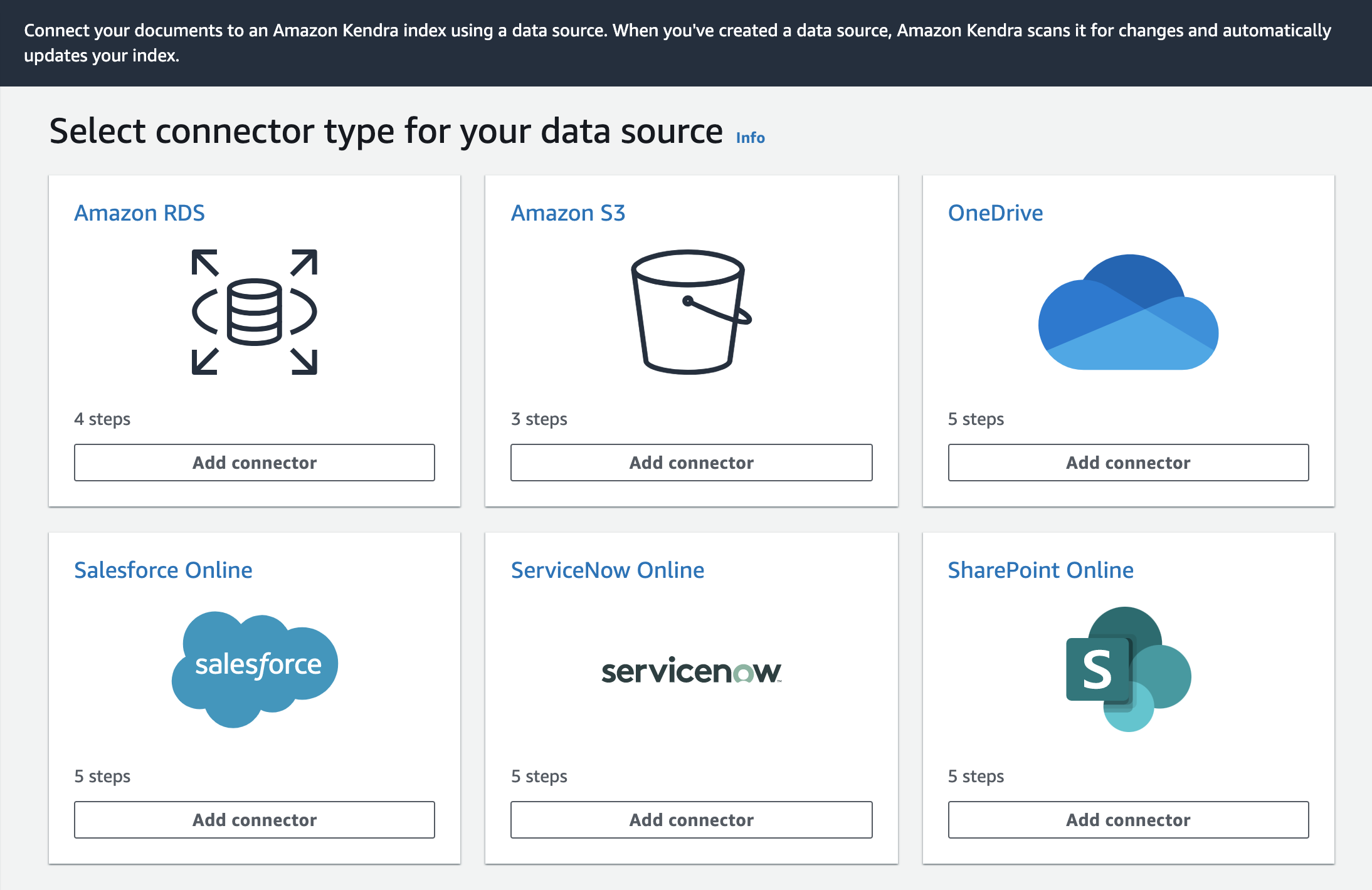
データソース設定
今回はS3を使ってみる。
SharePoint Onlineもあるので、社内ドキュメントとは相性良いのかも。
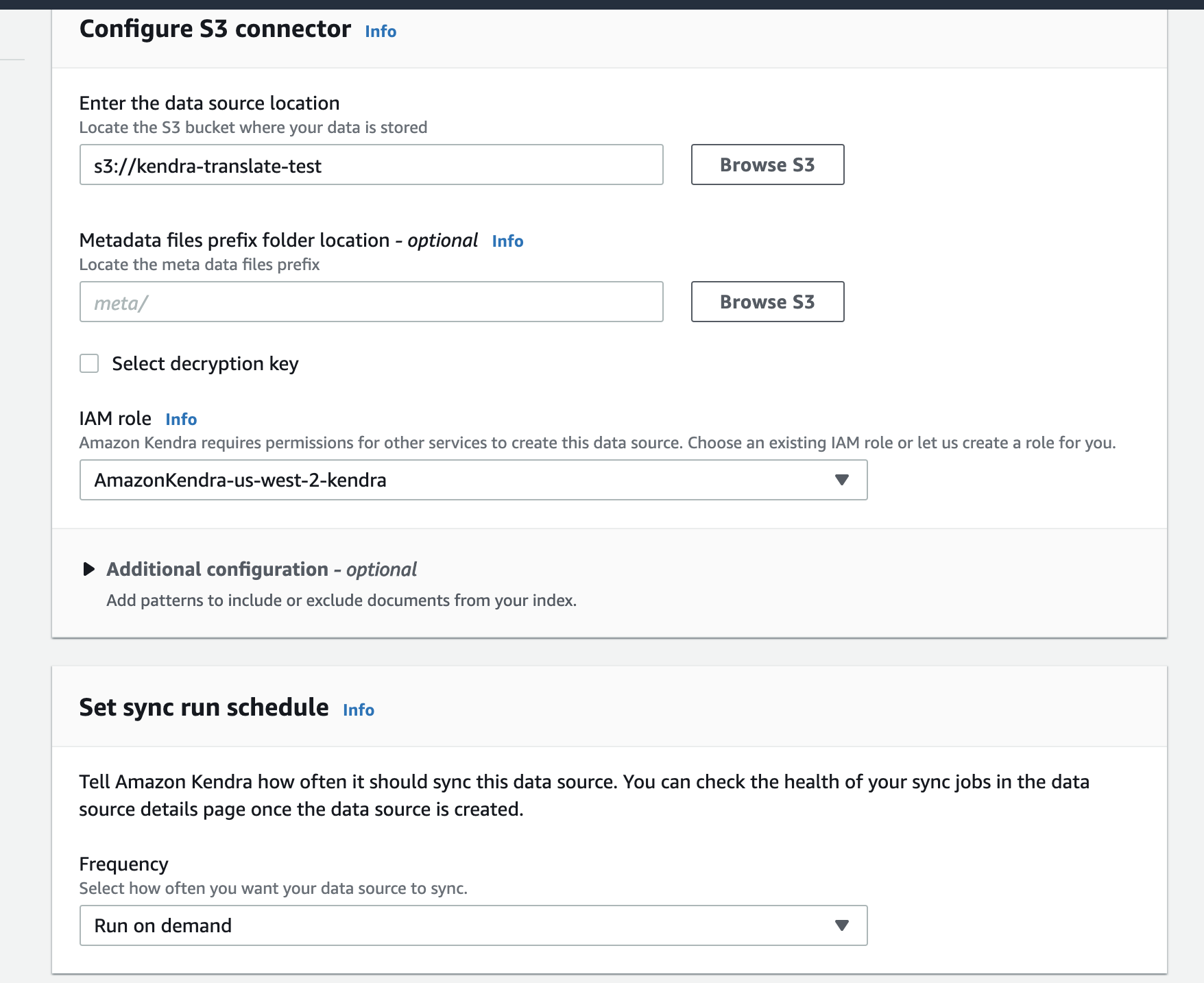
対象のバケットと、Roleと、データ同期のスケジュールを設定する。
今回はファイル更新しないのでRun on demandに設定。
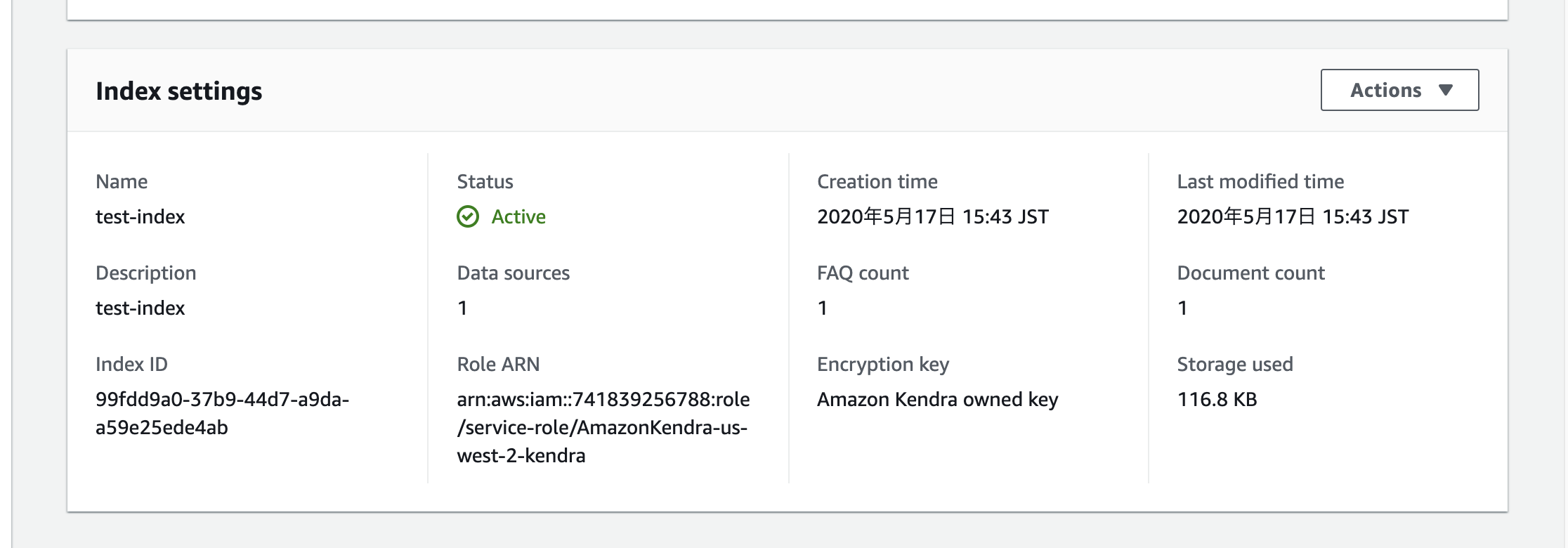
出来た。Index IDは検索する際に使う。
Document Countが1で、1ファイルが対象ドキュメントになっているのがわかる。
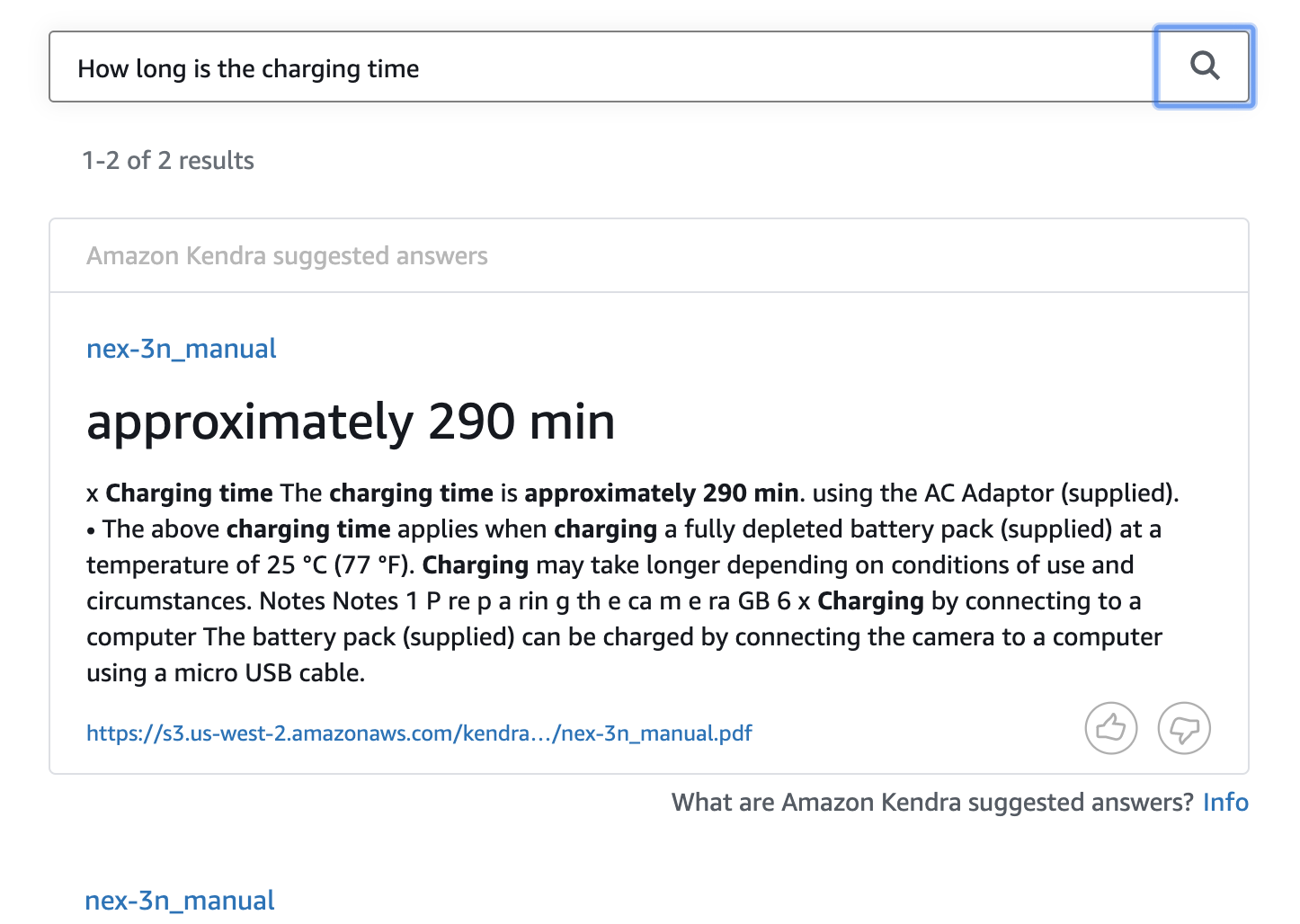
Search Consoleで検索できるか確認
もちろん英語で。
Q、充電時間はどのくらい?
A、約290分だよ
出来た。
Slackからスラッシュコマンドで使ってみる(APIGateWay+Lambda)
Lambda設定
- Python3.8で。
- 実行ロールにKendraへのアクセスを許可する
- あとはタイムアウト値を伸ばした(デフォルトって3秒なんですね。3秒だとタイムアウトになったので10秒に。)
import boto3
from urllib import parse
def lambda_handler(event, context):
kendra = boto3.client('kendra')
# SlashCommandから送られた引数
text = parse.parse_qs(event['body'])['text'][0]
# kendraにIndexID指定して投げる
response = kendra.query(IndexId='XXXXXXXXXXXXXXXXXXXXXXXXXXX', QueryText=text)
# jsonレスポンスをごにょごにょしてTextを抽出Slackに返す
item = response['ResultItems'][0]
res = item['AdditionalAttributes'][0]['Value']['TextWithHighlightsValue']['Text']
response = {
"statusCode": 200,
"body": res
}
return response
APIGateway設定
特に変わった設定はなし。
作成されたURLをSlash Command側で使う。

Slash Command設定
SlackAPIで自分で作ってもいいけど、Slackが提供しているアプリがあったのでこれを使う。
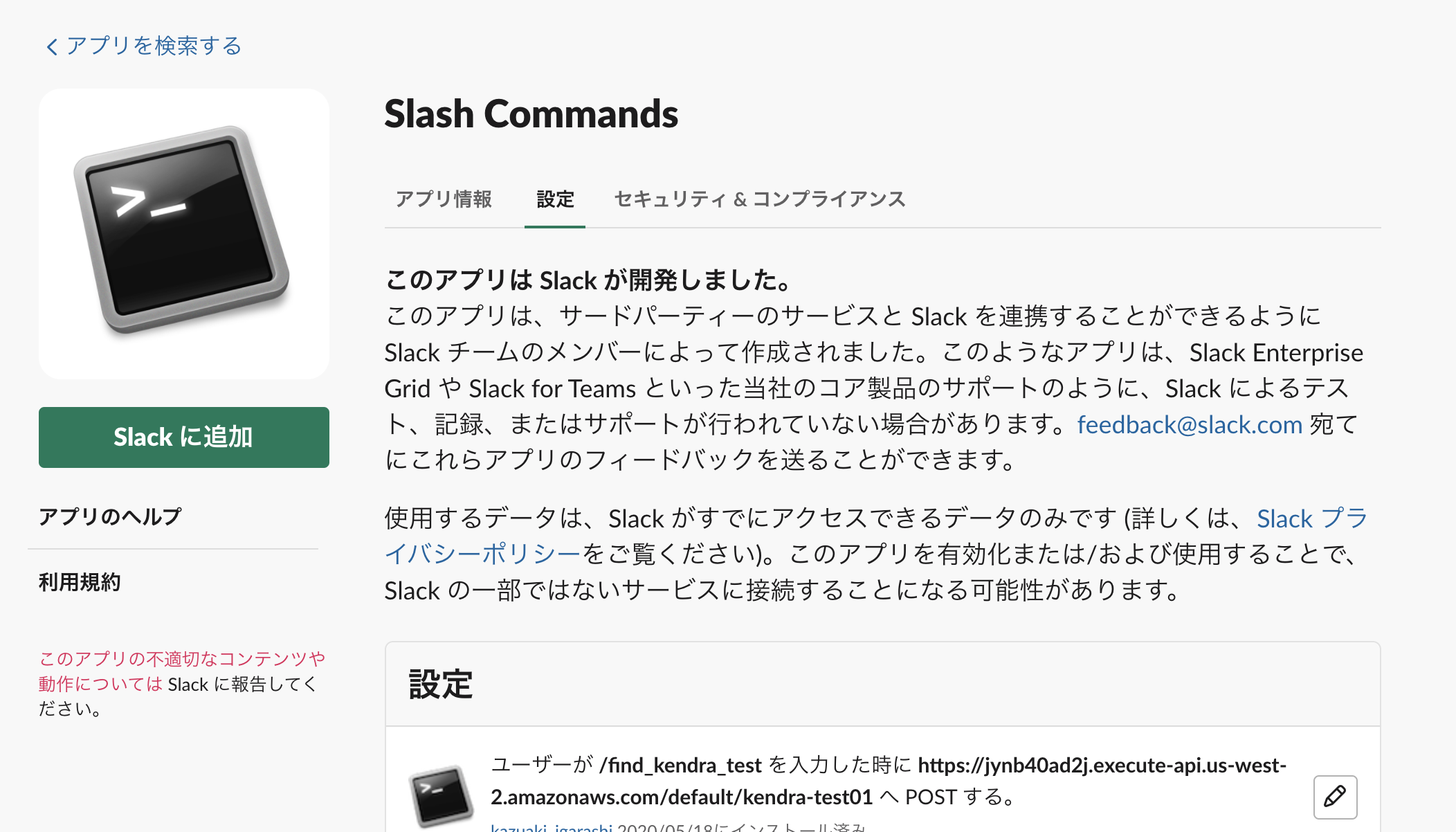
コマンドと、POST先のAPIGatewayのURLを設定する

Slash Commandsで送られるPOSTデータの中身
token=mFrLp0CXBndhvtRvBQY6Y6ke
team_id=T0001
team_domain=example
channel_id=C2147483705
channel_name=test
user_id=U2147483697
user_name=Steve
command=/weather
text=94070
response_url=https://hooks.slack.com/commands/1234/5678
完成
画面をみながらやってみます