OutSystemsで自分用アプリケーションを作ってみようという試みの一環(OutSystemsの技術支援を仕事にしているので、ドッグフーディング的に)。
SBI証券からダウンロードできる保有証券一覧のCSVは特殊な形式をしているので、これを題材に特殊な形式のCSVを処理する手順を確認する。
環境情報
ODC Studio (Version 1.4.26)
解析対象のCSV
口座管理 > 保有証券タブにある、「CSVダウンロード」のリンクから取得するCSVを対象とする。
CSVのサンプルとして、実際に自分のアカウントでダウンロードし、ファンド名と数値をマスクしたものを以下に示す。
なお、文字コードはSJIS、改行コードはLF。
保有証券一覧
投資信託(金額/特定預り)合計
評価額合計,評価損益合計
12345,+12345
投資信託(金額/特定預り)
ファンド名,保有口数,売却注文中,取得単価,基準価額,取得金額,評価額,評価損益,分配金受取方法
"ファンド1",12345口,,12345,12345,12345,12345,-12345,再投資
"ファンド2",12345口,,12345,12345,12345,12345,-12345,再投資
"ファンド3",12345口,,12345,12345,12345,12345,-12345,再投資
"ファンド4",12345口,,12345,12345,12345,12345,+12345,再投資
投資信託(金額/NISA預り(成長投資枠))合計
評価額合計,評価損益合計
12345,+12345
投資信託(金額/NISA預り(成長投資枠))
ファンド名,保有口数,売却注文中,取得単価,基準価額,取得金額,評価額,評価損益,分配金受取方法
"ファンド5",12345口,,12345,12345,12345,12345,-12345,再投資
"ファンド6",12345口,,12345,12345,12345,12345,+12345,再投資
"ファンド7",12345口,,12345,12345,12345,12345,-12345,受取
"ファンド8",12345口,,12345,12345,12345,12345,-12345,受取
投資信託(金額/NISA預り(つみたて投資枠))合計
評価額合計,評価損益合計
12345,+12345
投資信託(金額/NISA預り(つみたて投資枠))
ファンド名,保有口数,売却注文中,取得単価,基準価額,取得金額,評価額,評価損益,分配金受取方法
"ファンド9",12345口,,12345,12345,12345,12345,+12345,再投資
投資信託(金額/旧NISA預り)合計
評価額合計,評価損益合計
12345,+12345
投資信託(金額/旧NISA預り)
ファンド名,保有口数,売却注文中,取得単価,基準価額,取得金額,評価額,評価損益,分配金受取方法
"ファンド10",12345口,,12345,12345,12345,12345,+12345,再投資
"ファンド11",12345口,,12345,12345,12345,12345,+12345,再投資
CSVを読み解く
仕事でやるような開発なら、CSVの出力仕様を聞いて、それに基づいてやる。今回は、公開されている仕様が見つからなかったので、現物を読み解いて、必要なデータを抽出する方法を検討してみる。
(実データのみから検討するので、フォーマットや保有資産が変わるとエラーが出る可能性はある)
CSVをよく確認すると、恐らく、以下の仕様で出力されている。
(空行)
保有証券一覧
(空行)
(証券カテゴリごとの出力)× N個
(証券カテゴリごとの出力)は以下の仕様で、カテゴリに該当する資産を持っていないとカテゴリ自体をスキップしていそう。
(カテゴリ名)合計
(空行)
評価額合計,評価損益合計
12345,+12345
(空行)
(カテゴリ名)
(空行)
ファンド名,保有口数,売却注文中,取得単価,基準価額,取得金額,評価額,評価損益,分配金受取方法
"ファンド1",12345口,,12345,12345,12345,12345,-12345,再投資
"ファンド2",12345口,,12345,12345,12345,12345,-12345,再投資
"ファンド3",12345口,,12345,12345,12345,12345,-12345,再投資
"ファンド4",12345口,,12345,12345,12345,12345,+12345,再投資
(空行)
処理仕様を検討する
このCSVからどのデータが欲しいかというと、
- カテゴリ名
- 最後のテーブル形式のデータ
(証券カテゴリごとの出力)内では、カテゴリ名は5行目、テーブル形式のデータは8行目から次の空行の直前まで、と読める。
また、「(カテゴリ名)合計」というフォーマットなので「)合計」で終わっている行を見つけると、その位置がカテゴリの開始位置(合計だけで見ると、「評価額合計,評価損益合計」の行もヒットしてしまう)。
処理の流れ
以上の分析結果から、CSVファイルをアップロードして、中身を解析し、Entityに保存するプログラムの流れは以下の通り。
- ファイルのバイナリーデータをText型に変換
- 行ごとに分割
- 分割したリストをループして、カテゴリごとにTextのListに格納(さらにこれをList化する)
- 記録したカテゴリのリストをループして、カテゴリ毎に解析し、EntityのListに詰め替える
- Entityに保存する
以下でいくつかプログラム上のポイントを見ていく。
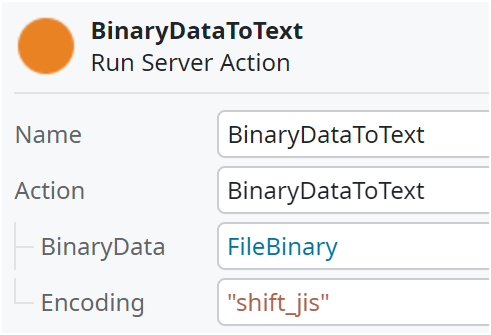
Shift-JISでエンコードされたファイルのBinary DataをText型に変換
Binary DataをText型に変換時、元のファイルがShift-JISでエンコーディングされているならば、Encodingパラメータには"shift_jis"を設定する。
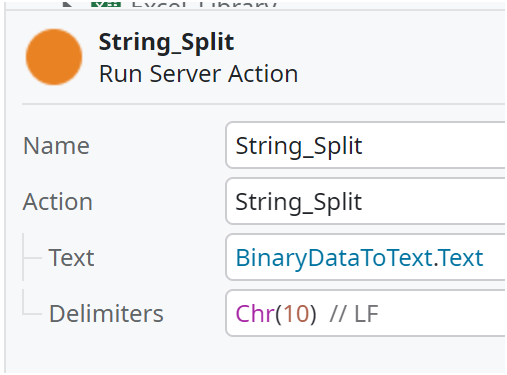
Text型データを改行コード(LF)で分割する
LFはASCIIコードで10。
そこで、Chr(10)をString_Splitに渡す。
行ごとに分割したTextのListから、カテゴリの開始位置を別のListに格納していく
コントロールブレークパターンを使う。
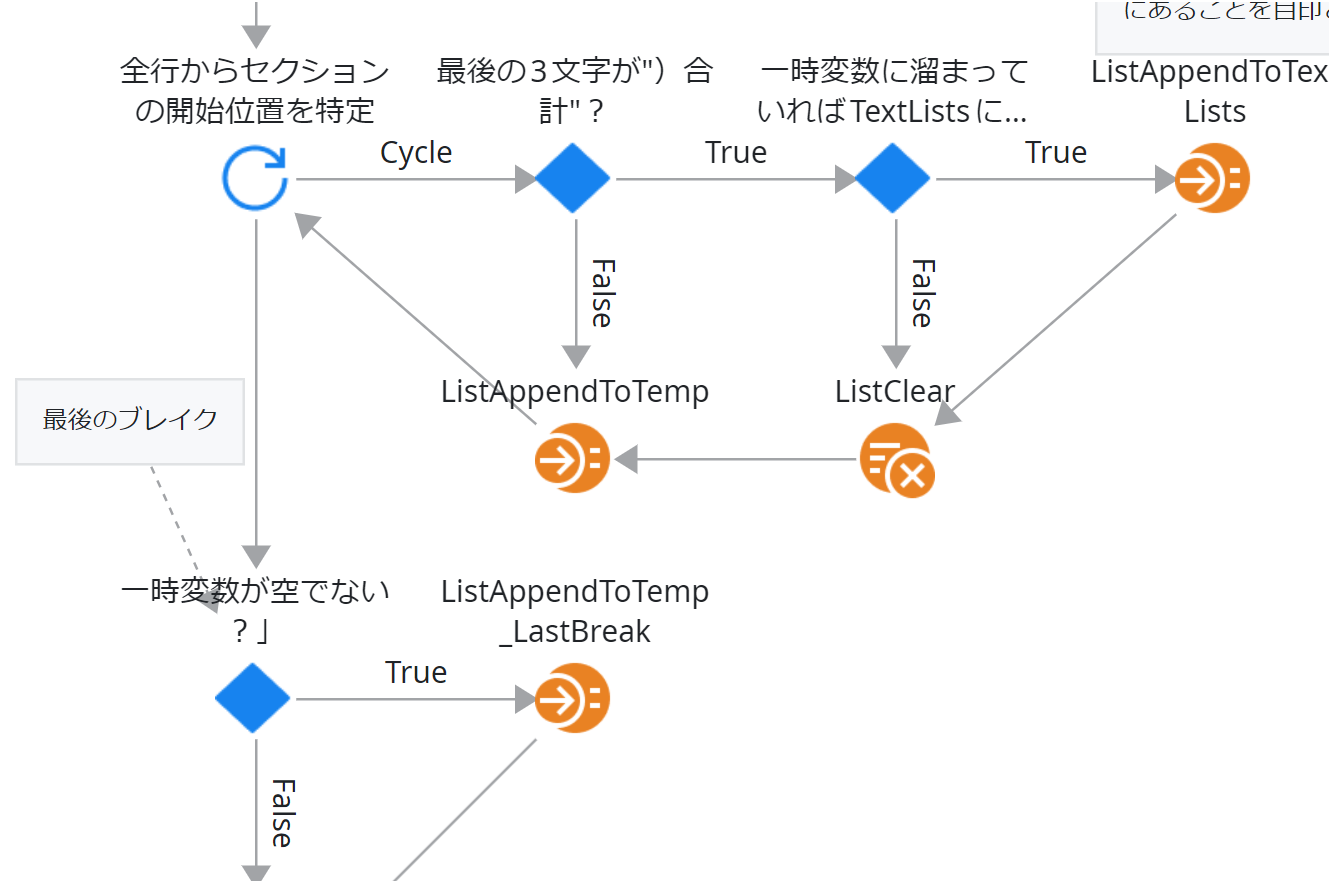
「最後の3文字が")合計"?」の条件に合致したら、コントロールブレークとする。
ループ対象のText型が「)合計」で終わっていることの判定は以下の式で行っている(CateGoryStartLineMarker=「)合計」)。
Index(String_Split.List.Current.Text.Value, CateGoryStartLineMarker, searchFromEnd: True) = Length(String_Split.List.Current.Text.Value) - Length(CateGoryStartLineMarker)
カテゴリの解析
カテゴリ内の各行を処理する。
まず、カテゴリ名の取得。カテゴリ内の5行目がそのままカテゴリ名となっている。Best Practiceで、Listのインデクサでアクセスするのを避けるというものがあるが、あれはAggregateの結果を全部メモリに格納してしまうというのが理由で、この場合はどうせメモリに乗っているはずなのでインデクサを使っている。
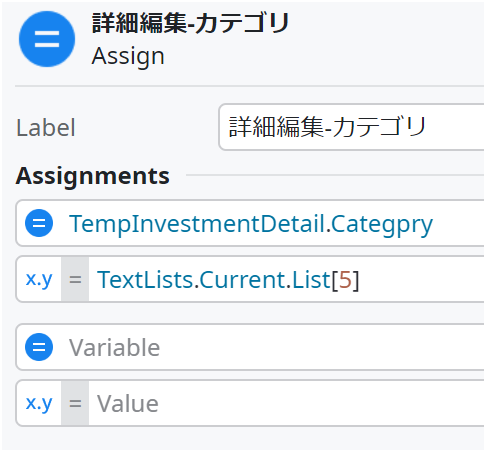
データ部分の各行を処理する部分。
行内は普通のカンマ区切りTextなので、Text/String_Split Actionで「,」を区切り文字として分割すると、各セルのListを取得できる。
↑と同じ理由でインデクサを使っていいので、各セルにはインデクサを使って値取得する。