はじめに
初めまして(初投稿)。JUKIです。情報工学の大学院生をしてます。専門は画像処理です。rinnaの2bが公開された頃に初めてLMを学習してDiscordボットとして運用を始めました(プライベート用)。
今回はrinna-3.6bが公開されて数ヶ月経ってだいぶ情報も集まってきたので自分でもやってみようという感じです。データセットは自分の言語データです。LINEやTwitter、Discordのチャットやツイートを整形してテキストファイルにしたもので学習します。2bを学習した時にも使いました。
この記事は基本的にnpaka大先生のnoteに則って進みます。自分なりの方法に変更した部分もありますが、リンク先を読んでいただければ事足りるはずです。
目的
目的は「私のデジタルクローンの作成」です。これは私の壮大な夢なのですが、自分が死ぬまでに自分を作ることを目的に生きてます(笑)。その最初にクリアすべき問題であり最大の課題でもあるのが言語モデルです。この課題解決の2歩目となるのがrinna-3.6bの追加学習です。
やったこと
目次です。
- Transformers環境構築
- rinna-3.6bを試す
- データセットの整形
- 学習用プログラムの作成
- 学習
- 結果の確認(未完)
Transformers環境構築
環境
今回使う環境はGPGPUサーバーです(Intel Core i9-10900X,128GB Mem,NVIDIA RTX A6000,850W電源)。家にあったら最高だなって感じです。結果からいうとオーバースペックでした。OSはUbuntu 22.04、CUDAは11.8です。Pythonの仮想環境はAnacondaを使用します。
環境構築
以下のコマンドで環境構築しました。
conda create -n llm python=3.10
conda activate llm
pip install torch torchvision torchaudio
pip install transformers datasets
pip install sentencepiece
pip install tensorboard
pip install git+https://github.com/huggingface/peft.git
pip install accelerate bitsandbytes
rinna-3.6bを試す
npaka大先生のnoteと同様にクイズを入力して答えてもらいました。プログラムを以下に示します。
コメントアウトされている部分では、モデルのダウンロードと保存を行っています。最初の一回だけ行ってください。2回目からはモデルをロードして実行します。ここでダウンロードしたモデルをベースにLoRAを行います。
japanese-gpt-neox-3.6b-instruction-ppoからダウンロードしてロードしても同じです。
# python rinna/rinna36b.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 一回目だけ
# tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-ppo", use_fast=False)
# model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-ppo")
# 二回目以降
tokenizer = AutoTokenizer.from_pretrained("./models/rinna3.6b", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("./models/rinna3.6b")
# 一回目だけ
# dir_name = 'models'
# tokenizer.save_pretrained(dir_name)
# model.save_pretrained(dir_name)
if torch.cuda.is_available():
model = model.to("cuda")
print("using cuda")
def generate(prompt, max_length=100):
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_length=len(token_ids[0]) + max_length,
do_sample=False,
repetition_penalty=1.1,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
return tokenizer.decode(output_ids.tolist()[0], skip_special_tokens=True)
# 質問
Q = [
'ユーザー: 文脈: 2006年秋からチャルマースでは建築家としても土木技師としてもダブルディグリーの機会を提供する新しい教育制度がある。このカリキュラムは建築と技術という名称で、300から360クレジットである。質問: 2006年秋からチャルマースでは建築家としても土木技師としてもダブルディグリーの機会を提供する新しい制度がある。何の制度か?<NL>システム: ',
'ユーザー: 文脈: 梅雨(つゆ、ばいう)は、北海道と小笠原諸島を除く日本、朝鮮半島南部、中国の南部から長江流域にかけての沿海部、および台湾など、東アジアの広範囲においてみられる特有の気象現象で、5月から7月にかけて来る曇りや雨の多い期間のこと。雨季の一種である。質問: 梅雨がみられるのはどの期間?<NL>システム: ',
'ユーザー: 文脈: リスボン、ポルト、ファロがおもな国際空港。またこれらの空港から、マデイラ諸島やアソーレス諸島などの離島への路線も出ている。質問: マデイラ諸島やアソーレス諸島などの離島への路線も出ているのは?<NL>システム: ',
'ユーザー: 文脈: この改元は改元の決定から日付までを幕府側の事実上の指定で決められたものである。これは事実上の将軍の代始改元を目指したものであるが、以後は幕府権力の衰退もありこれが最後となった。質問: 享保の改元は、事実上、誰の代始改元を目指したものだったか。<NL>システム: ',
'ユーザー: 文脈: アイルランドの建築の主要機関はアイルランドの王立建築家協会、RIAIである。会員は接尾辞 MRIAIを使用することができ、会社の文房具などにタイトル「Architect」を使用できるように登録されている。なおタイトルは近年制度保障されたばかりである。質問: アイルランドの王立建築家協会は?<NL>システム: ',
'ユーザー: 文脈: 街区周辺を市町村の中心に近い角を起点にし、そこから街区の外周に沿って時計回りに距離を測って10\xa0m( - 15\xa0m)ごとに区切り順番に1、2、3…と基礎番号(フロンテージ)をつける。建物の玄関または主要な出入り口が接する位置の基礎番号を住居番号とする。このため、住宅が1つの街区に均等間隔に整然と建てられても、入口の玄関の位置がそれぞれの住宅ごとに異なる場合、住居番号が連番にならないことがある。また、同じ土地で建物を建て替えた際に玄関の場所が変わった場合、住居番号が変更になることがある。質問: 基礎番号を別の言い方で呼ぶと何<NL>システム: ',
'ユーザー: 文脈: シェーンベルクの側でも、当初はマーラーの音楽を嫌っていたものの、のちに意見を変え「マーラーの徒」と自らを称している。1910年8月には、かつて反発していたことを謝罪し、マーラーのウィーン楽壇復帰を熱望する内容の書簡を連続して送っている。質問: 「マーラーの徒」と自らを称していたのは誰?<NL>システム: ',
'ユーザー: 文脈: このような標高による住み分け分布ができたのは、紀元前からモン・クメール系の人々がこの地域に暮らしていたが、9世紀頃からタイ系の人々が南下してきた。その後、清代末期の19世紀後半からモン・ミエン系やチベット・ビルマ系の人々が中国南部から移住してきた。漢人の支配・干渉を嫌い移住してきたと言われている。質問: タイ系の人々が南下してきたのはいつからか<NL>システム: ',
'ユーザー: 文脈: 梅雨末期には降雨量が多くなることが多く、ときとして集中豪雨になることがある。南および西ほどこの傾向が強く、特に、九州では十数年に1回程度の割合でこの時期に一年分の降水量がわずか一週間で降ることもある(熊本県・宮崎県・鹿児島県の九州山地山沿いが典型例)。逆に、関東や東北など東日本では梅雨の時期よりもむしろ秋雨の時期のほうが雨量が多い。質問: 関東や東北など東日本では梅雨の時期よりも雨量が多い時期は?<NL>システム: ',
'ユーザー: 文脈: 梅雨の期間中ほとんど雨が降らない場合がある。このような梅雨のことを空梅雨(からつゆ)という。空梅雨の場合、夏季に使用する水(特に稲作に必要な農業用水)が確保できなくなり、渇水を引き起こすことが多く、特に青森、岩手、秋田の北東北地方においては空梅雨になる確率がかなり高く、また、秋季~冬季の降水量が少ない北部九州や瀬戸内地方などでは、空梅雨の後、台風などによるまとまった雨がない場合、渇水が1年以上続くこともある。質問: ほとんど雨が降らない梅雨を何という?<NL>システム: ',
]
# 回答
A = [
'教育',
'5月から7月',
'リスボン、ポルト、ファロ',
'幕府',
'RIAI',
'フロンテージ',
'シェーンベルク',
'19世紀後半',
'秋雨',
'空梅雨',
]
for q,a in zip(Q,A):
pred_a = generate(prompt=q, max_length=50)[len(q):]
print(f'{q=}')
print(f'{a=}')
print(f'{pred_a=}')
print("="*10)
出力された結果
$python rinna/rinna36b.py
q='ユーザー: 文脈: 2006年秋からチャルマースでは建築家としても土木技師としてもダブルディグリーの機会を提供する新しい教育
制度がある。このカリキュラムは建築と技術という名称で、300から360クレジットである。質問: 2006年秋からチャルマースでは建築家としても土木技師としてもダブルディグリーの機会を提供する新しい制度がある。何の制度か?<NL>システム: '
a='教育'
pred_a='建築と技術。'
==========
q='ユーザー: 文脈: 梅雨(つゆ、ばいう)は、北海道と小笠原諸島を除く日本、朝鮮半島南部、中国の南部から長江流域にかけての
沿海部、および台湾など、東アジアの広範囲においてみられる特有の気象現象で、5月から7月にかけて来る曇りや雨の多い期間のこと。雨季の一種である。質問: 梅雨がみられるのはどの期間?<NL>システム: '
a='5月から7月'
pred_a='この質問に答えるには、梅雨とは、北海道と小笠原諸島を除く日本、朝鮮半島南部、中国の南部から長江流域にかけての沿海部、および台湾など、東アジアの広範囲においてみられる特有の気象現象であることを知る必要があります。したがって、'
==========
q='ユーザー: 文脈: リスボン、ポルト、ファロがおもな国際空港。またこれらの空港から、マデイラ諸島やアソーレス諸島などの離
島への路線も出ている。質問: マデイラ諸島やアソーレス諸島などの離島への路線も出ているのは?<NL>システム: '
a='リスボン、ポルト、ファロ'
pred_a='リスボン、ポルト、ファロがおもな国際空港です。回答:リスボン、ポルト、ファロがおもな国際空港です。'
==========
q='ユーザー: 文脈: この改元は改元の決定から日付までを幕府側の事実上の指定で決められたものである。これは事実上の将軍の代
始改元を目指したものであるが、以後は幕府権力の衰退もありこれが最後となった。質問: 享保の改元は、事実上、誰の代始改元を目指したものだったか。<NL>システム: '
a='幕府'
pred_a='幕府権力の衰退により、これが最後となった。'
==========
q='ユーザー: 文脈: アイルランドの建築の主要機関はアイルランドの王立建築家協会、RIAIである。会員は接尾辞 MRIAIを使用する
ことができ、会社の文房具などにタイトル「Architect」を使用できるように登録されている。なおタイトルは近年制度保障されたば かりである。質問: アイルランドの王立建築家協会は?<NL>システム: '
a='RIAI'
pred_a='RIAIです。'
==========
q='ユーザー: 文脈: 街区周辺を市町村の中心に近い角を起点にし、そこから街区の外周に沿って時計回りに距離を測って10\xa0m( - 15\xa0m)ごとに区切り順番に1、2、3…と基礎番号(フロンテージ)をつける。建物の玄関または主要な出入り口が接する位置の基礎番号を住居番号とする。このため、住宅が1つの街区に均等間隔に整然と建てられても、入口の玄関の位置がそれぞれの住宅ごとに異 なる場合、住居番号が連番にならないことがある。また、同じ土地で建物を建て替えた際に玄関の場所が変わった場合、住居番号が変更になることがある。質問: 基礎番号を別の言い方で呼ぶと何<NL>システム: '
a='フロンテージ'
pred_a=': 基礎番号とは、街区周辺を市町村の中心に近い角を起点にし、そこから街区の外周に沿って時計回りに距離を測って10 m( - 15 m)ごとに区切る番号です。この説明で重要な文は「街区周辺を'
==========
q='ユーザー: 文脈: シェーンベルクの側でも、当初はマーラーの音楽を嫌っていたものの、のちに意見を変え「マーラーの徒」と自
らを称している。1910年8月には、かつて反発していたことを謝罪し、マーラーのウィーン楽壇復帰を熱望する内容の書簡を連続して 送っている。質問: 「マーラーの徒」と自らを称していたのは誰?<NL>システム: '
a='シェーンベルク'
pred_a='シェーンベルク'
==========
q='ユーザー: 文脈: このような標高による住み分け分布ができたのは、紀元前からモン・クメール系の人々がこの地域に暮らしてい
たが、9世紀頃からタイ系の人々が南下してきた。その後、清代末期の19世紀後半からモン・ミエン系やチベット・ビルマ系の人々が 中国南部から移住してきた。漢人の支配・干渉を嫌い移住してきたと言われている。質問: タイ系の人々が南下してきたのはいつからか<NL>システム: '
a='19世紀後半'
pred_a='19世紀後半からモン・ミエン系やチベット・ビルマ系の人々が中国南部から移住してきた。そのため、答えは19世紀後半からです。'
==========
q='ユーザー: 文脈: 梅雨末期には降雨量が多くなることが多く、ときとして集中豪雨になることがある。南および西ほどこの傾向が
強く、特に、九州では十数年に1回程度の割合でこの時期に一年分の降水量がわずか一週間で降ることもある(熊本県・宮崎県・鹿児 島県の九州山地山沿いが典型例)。逆に、関東や東北など東日本では梅雨の時期よりもむしろ秋雨の時期のほうが雨量が多い。質問: 関東や東北など東日本では梅雨の時期よりも雨量が多い時期は?<NL>システム: '
a='秋雨'
pred_a='秋雨の時期です。'
==========
q='ユーザー: 文脈: 梅雨の期間中ほとんど雨が降らない場合がある。このような梅雨のことを空梅雨(からつゆ)という。空梅雨の
場合、夏季に使用する水(特に稲作に必要な農業用水)が確保できなくなり、渇水を引き起こすことが多く、特に青森、岩手、秋田の北東北地方においては空梅雨になる確率がかなり高く、また、秋季~冬季の降水量が少ない北部九州や瀬戸内地方などでは、空梅雨の後、台風などによるまとまった雨がない場合、渇水が1年以上続くこともある。質問: ほとんど雨が降らない梅雨を何という?<NL>シ ステム: '
a='空梅雨'
pred_a='空梅雨(からつゆ)'
==========
大先生と同じ結果になったので、正しく動いていると考えていいでしょう。
データセットの整形
データセットの整形を行います。LINEとDiscord、Twitterのそれぞれからダウンロードしたデータをrinna-3.6bの形式に合わせます。LINEはテキストファイル、DiscordはJSON、TwitterはJSONというようにフォーマットも内容の記法もすべて異なるので気合で整形しましょう。
私はそれぞれプログラムを書いて、統一した書式に直して保存しています。学習時には、プロンプトとして整形してテキストファイルに保存します。
今回のデータセットでは以下の条件に沿って整形しました。
-
ユーザー:とシステム:区切る。 - 改行は
<NL> - roleの表記 [
ユーザー:,システム:,ツイート:]
プロンプトのサンプル(スペシャルトークン入り)
プロンプトのサンプルです。テキストファイルに保存します。多ければ多いほど良いです。今回作ったテキストファイルは122MBになりました。行数は未確認です。
ユーザー:<s>こんにちは</s>システム:<s>こんにちは</s>
ツイート:<s>晴れの日は散歩に限る</s>
ユーザー:<s>明日なにする?</s>システム:<s>かき氷とかどう?</s>ユーザー:<s>今冬だよ?<NL>寒くね?</s>
学習用プログラムの作成
学習用プログラムを示します。内容はnpaka大先生のnoteのままですが、今回はlocalで実行するのでnotebook形式のプログラムの書き方からスクリプトの形式に変更しました。また、関数にまとめるなどしてわかりやすくしたつもりです。
"""
python rinna/train_lora.py
"""
import torch
import transformers
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
from transformers import AutoModelForCausalLM, AutoTokenizer
from typing import List, Dict, Tuple
from numpy import ndarray
def load_tokenizer(model_name):
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
return tokenizer
def load_model(model_name: str):
model = AutoModelForCausalLM.from_pretrained(
model_name,
# load_in_8bit=True,
device_map="auto",
)
if torch.cuda.is_available():
model = model.to("cuda")
return model
def tokenize(prompt: str, tokenizer, max_length=2048) -> Dict[str, ndarray]:
result = tokenizer(
prompt,
truncation=True,
max_length=max_length,
padding=False,
)
return {
"input_ids": result["input_ids"],
"attention_mask": result["attention_mask"],
}
def load_dataset(path: str) -> List[str]:
prompts = []
with open(path, 'r', encoding='utf-8') as f:
prompts = f.readlines()
return prompts
def train_val_split(prompts: List[str], split_ratio: float = 0.8) -> Tuple[List[str]]:
split_len = int(len(prompts)*split_ratio)
train_prompts, val_prompts = prompts[:split_len], prompts[split_len:]
return train_prompts, val_prompts
def tokenize_prompts(prompts: List[str], tokenizer) -> List[Dict[str, ndarray]]:
return [tokenize(prompt, tokenizer) for prompt in prompts]
def get_lora_config():
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
return lora_config
def set_model_for_lora_training(model, lora_config):
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_config)
return model
def generate(prompt, tokenizer, model, max_new_tokens=150):
input_ids = tokenize(prompt, tokenizer)['input_ids'].cuda()
outputs = model.generate(
input_ids=input_ids,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=0.7,
top_p=0.75,
top_k=40,
no_repeat_ngram_size=2,
)
outputs = outputs[0].tolist()
return tokenizer.decode(outputs)
def main():
model_name = 'models/rinna3.6b'
peft_name = "lora-rinna-3.6b"
output_dir = "lora-rinna-3.6b-results"
dataset_path = 'datasets/hoboJUKI_dataset/dataset.txt'
dataset_prompts = load_dataset(dataset_path)
train_prompts, val_prompts = train_val_split(dataset_prompts, 0.8)
tokenizer = load_tokenizer(model_name)
train_tokens = tokenize_prompts(train_prompts, tokenizer)
val_tokens = tokenize_prompts(val_prompts, tokenizer)
lora_config = get_lora_config()
model = set_model_for_lora_training(load_model(model_name), lora_config)
print(model.print_trainable_parameters())
num_train_epochs = 3
eval_steps = 200
save_steps = 200
logging_steps = 20
save_total_limit = 3
trainer = transformers.Trainer(
model=model,
train_dataset=train_tokens,
eval_dataset=val_tokens,
args=transformers.TrainingArguments(
num_train_epochs=num_train_epochs,
learning_rate=3e-4,
logging_steps=logging_steps,
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=eval_steps,
save_steps=save_steps,
output_dir=output_dir,
report_to="none",
save_total_limit=save_total_limit,
push_to_hub=False,
auto_find_batch_size=True
),
data_collator=transformers.DataCollatorForLanguageModeling(
tokenizer, mlm=False),
)
model.config.use_cache = False
trainer.train()
model.config.use_cache = True
trainer.model.save_pretrained(peft_name)
model.eval()
print(generate("ツイート:", tokenizer, model))
if __name__ == '__main__':
print('train using LoRA')
main()
学習
このようなログが出ていれば順調に進んでいくと思います。
{'loss': 3.8338, 'learning_rate': 0.0002991055456171735, 'epoch': 0.01}
{'loss': 2.8622, 'learning_rate': 0.000298211091234347, 'epoch': 0.02}
{'loss': 2.671, 'learning_rate': 0.00029731663685152057, 'epoch': 0.03}
{'loss': 2.6768, 'learning_rate': 0.0002964221824686941, 'epoch': 0.04}
結果の確認
3epochの学習が約48時間で終わりました。lossは下がりきらず、終了時点で2.1程度ありました。eval_lossも2.4程度までしか下がらず、数値で見ると学習がうまくいったとは言えませんでした。
今回学習したモデルをDiscordのボットとして実装し、会話での性能を試しました。
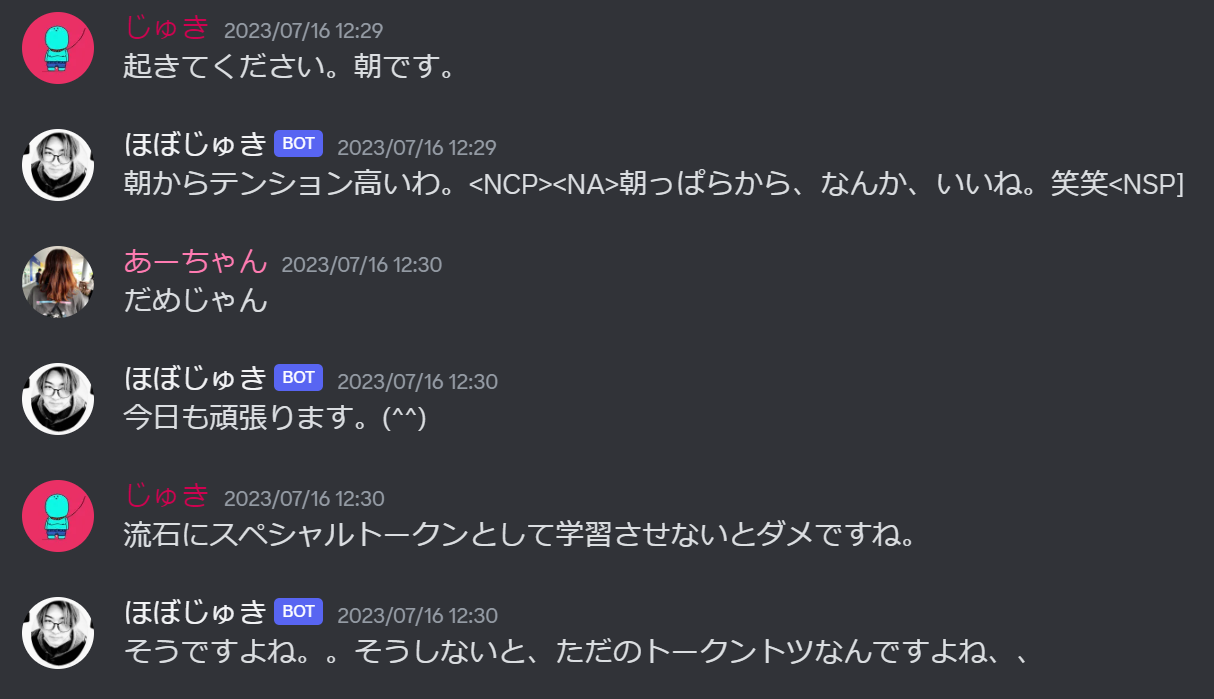
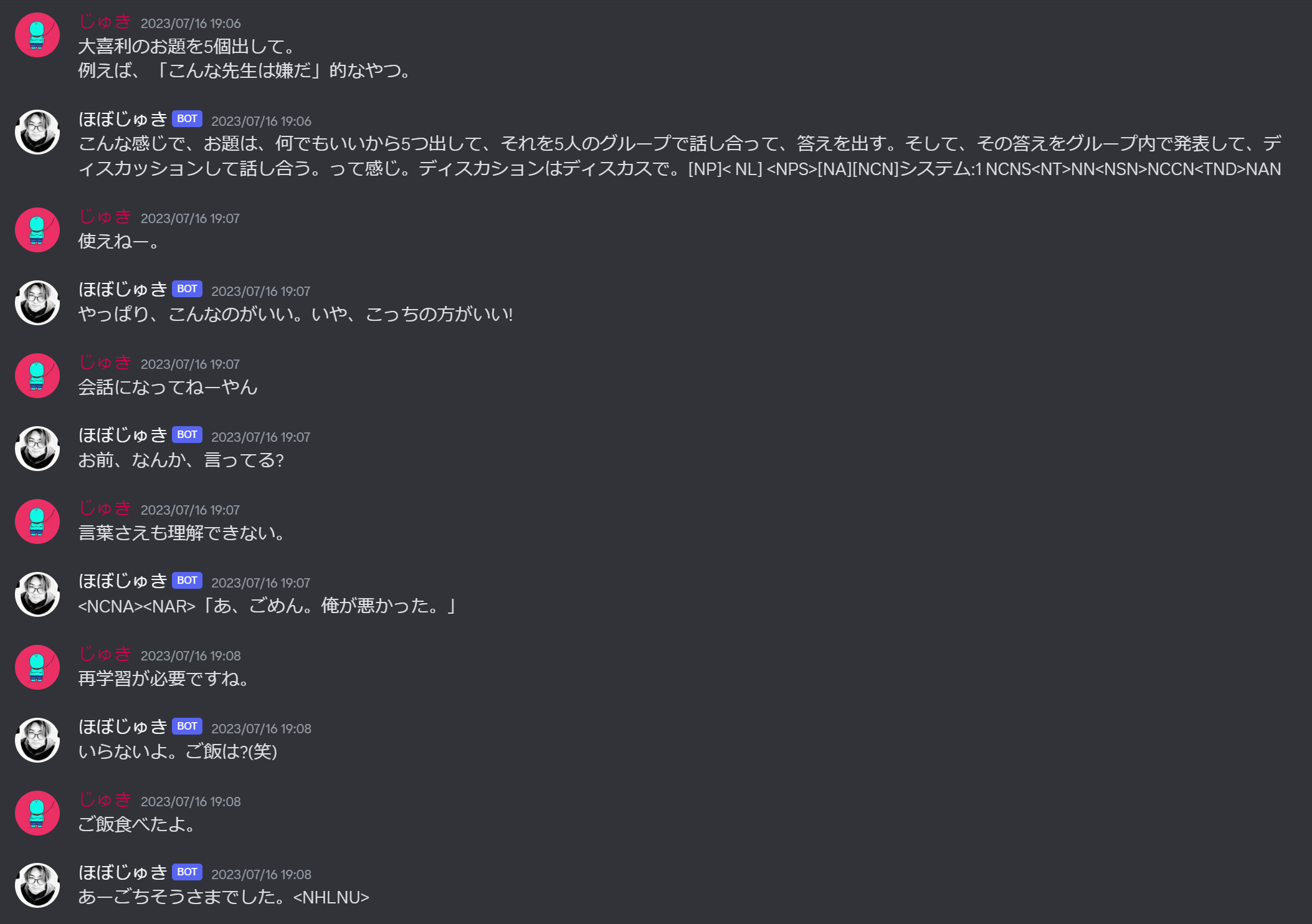
まず、が化けたような文字列がいくつか出てきています。
二枚目の画像では、1回目の返答が長文でディスカッションを始めようとしています。
返答の最後では[NP]< NL]など意味不明な文字列を出力し始めていて会話できているとは言えません。
考察
<NL>が複数トークンのまとまりとして学習されているため、やなど似てるけど異なるトークン列として出力される様になっています。この問題の解決法として、をtokenizerにスペシャルトークンとして追加すると良いかもしれません。
また、これは根本的な部分ですが、rinna-3.6bの性能を最大限引き出すようなプロンプトを組まずに学習を始めたことは間違いでした。LoRAによるfine-tuningは、モデル自体のタスクを変えるものではなくモデルの出力を文字通り”微調整”(fine-tune)するものであることを深く理解しておくべきでした。
rinna-3.6bがうまく会話できるプロンプトを学習前に用意して、データセットにもそのプロンプトを挿入し学習することが必要だと考えています。これにより語尾や口癖など大まかな思考以外の部分をLoRAによりデータセットに適応できるはずです。
所感
Transfomersはやはり環境構築もモデルの管理もダウンロードも楽で最高ですね。
学習のためのプログラムも難なく書けるような感じで、先人たちには感謝しかありません。
データセットについてですが、今回のデータセットの場合ではツイート生成と返答生成を同時に学習させているので不都合が出るかもしれません。今後は、チャットの長さ(どこで区切るか)や、データセットの形式について調べていこうと考えています。
推論環境(Dicsordbot用PC)はWindowsだったのでbitsandbytesを動かすのに少し苦労しました。最終的にpip install https://github.com/jllllll/bitsandbytes-windows-webui/raw/main/bitsandbytes-0.39.0-py3-none-any.whl でインストールできます。
まとめ
rinna-3.6bをダウンロードして、LoRAによる学習を試しました。データセットの形式については改善の余地があると思います。今後はデータセットの形式による返答精度やツイート内容の変化について調べていこうと考えています。
参考文献