はじめに
今回はChatGPTを一気にマルチモーダル化できる「HuggingGPT」について、簡単な説明とデモを紹介していきたいと思います。
ChatGPTといえば、「テキスト」というイメージが強いと思いますが、今回紹介するHuggingGPTを使う事で、実際AIの細かい事はよくわからない・・という方でも、テキストに加えて、画像・音声・動画に対しても、ChatGPTと同様のやりとりで、マルチモーダルなAIの活用が可能になります。
今回はHuggingGPTを知らないという方、名前は聞いた事があるけれど具体的にはよくわからないという向けに「HuggingGPTで何ができるのか」に焦点を当てて説明していきたいと思います。
[元論文]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
HuggingGPTで何ができるのか?
さて、ではHuggingGPTで何ができるようになるのでしょうか?
一言で言ってしまえば、「抽象度の高い入力に対して、ChatGPTが必要なAIモデルを自ら探してタスクを解いてくれる」という事になります。
実際のイメージがないとわかりにくいと思いますので、論文の画像を引用します。
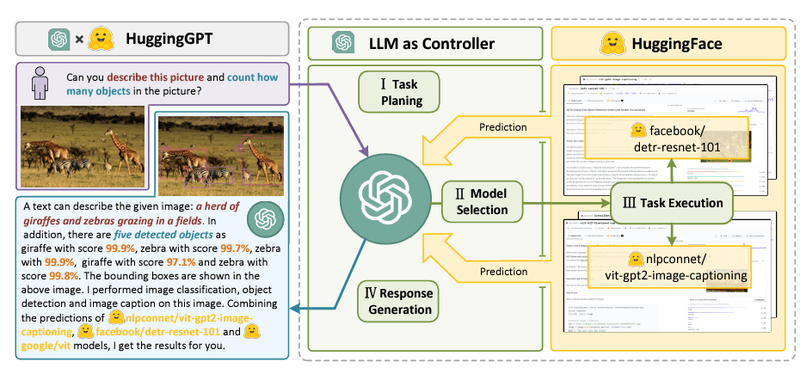
左側の紫色の枠がユーザーのインプットで、青枠がHuggingGPTのレスポンスになります。
この例では、ユーザーからの要求は「この絵について説明し、絵の中に写っている物体の数を数えてくれますか?」という事になります。
当然これはテキストのタスクではないので、通常のChatGPTにそのまま投げても解くことはできないのですが、HuggingGPTの応答では「この画像は、草原で草を食べているキリンとシマウマの群れで、5つの物体が写っています」と回答しています。
そしてよく見てみると、単純な回答だけではなく、各物体のオブジェクト検出時のスコアと、どういうタスクをどのAIモデルで解いたのかという説明もついています。
つまり、AIエンジニア目線で言うと、
「画像を説明してという事だから、ImageToTextのタスクで、ImageToTextのモデルで一番良いのは・・これだな。実装は・・なるほどこうやって使うのか。で、結果はこう返したほうが良さそうだな。次は、オブジェクトを数えてと言っているからObjectDetectionのタスクで・・」
というような事を全て自動でやってくれているという事です。
実際にどうやっているかというと、上記画像の灰色の点線で囲まれている箇所になるのですが、簡単な概念図は以下です。

まず最初にユーザーからのプロンプト要求に対して、タスク計画(Stage1)を実施します。
上記のAIエンジニアの目線で言うと、「このタスクを解くためにはImageToTextとObjectDetectionが必要だな」という箇所になります。
続いて、各タスクを解くために必要なAIモデルをHuggingFace上のAIモデルの中から選択します(Stage2)。ImageToTextだとこのAIモデル、ObjectDetectionだとこのAIモデルという風に、AIモデルを探す箇所も自動化してくれるという事になります。
そして、選択したAIモデルで実際に各タスクを実行した上で(Stage3)、どのようにタスクを解いたのかというタスク計画とどのAIモデルを使ったのかという説明付きのレスポンスを生成し(Stage4)、プロンプト応答を返すという流れになります。
HuggingFaceって何?という人のために説明しておくと、HuggingFaceは世界中のAIモデルがある図書館のようなイメージになります。
以下がHuggingFaceのサイトですが、左側に解きたいタスク、右側に各AIモデルが並んでいます。
HuggingFaceのモデル一覧
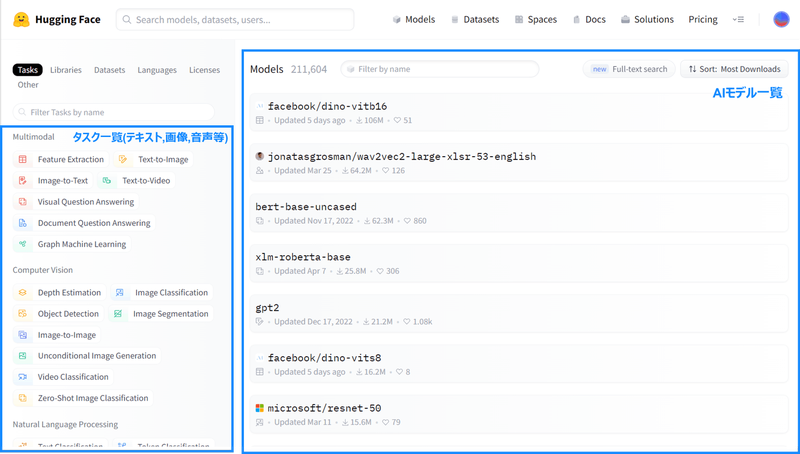
タスク一覧には、自然言語処理だけでなく、画像・音声・動画も含まれるため、この中からタスクを解くために必要なAIモデルを選ぶという形を取る事で、マルチモーダルが実現できるという事になります。
HuggingGPTで何ができるかという事を別の言い方で言えば、「HuggingFace上の一覧に含まれるタスクと、その組み合わせタスクを解くことができる」という事になります。
そして、このモデル選択と実行はHuggingGPTが自動でやってくれるので、各AIモデルを意識する必要はありません。
少し雑に言ってしまうと、「AIあまりよくわからないけど、これってAIでできないのかな?」という状態で、HuggingGPTに依頼を丸投げできるという事になります。世界中の有名なAIモデルを一定使いこなせるAIエンジニアが味方についたようなイメージです。
そして、HuggingGPTの最も特徴的な点の一つが、単純に結果だけを返すのではなく、何をやったのかを説明してくれるという事です。
裏側は完全にブラックボックスで、結果だけを返すという事ではなく、どういうタスク計画で実際にどのAIモデルを使って解いたのかという事を説明してくれるので、処理内容のトレースができます。
2つ目の例として以下の「入力画像に似た姿勢で、女の子が本を読んでいる画像を作る」という別の例のレスポンスを見てみると、「The first thing I did was (私が最初にやった事は)、…… Lastly, …」というように、タスクを解くために何をやったのかを順序立てて説明してくれています。

人間でも、ここまでちゃんと報連相を常にやれているかというと難しいところで、AIエンジニア目線で言えばかなり雑なインプットに対しても、文句一つ言わず、説明付きで丁寧に答えを返してくれます。
ここまでをまとめると、HuggingGPTの特徴は以下になります。
- テキストだけでなく、画像・音声・動画を含むマルチモーダルなタスクが解ける
- タスクを解くためのタスク計画と、必要なAIモデルの選択・実行を自動でやってくれる
- 何をどの順番でやったのか、どのAIモデルを使ったのかという説明付きで結果を回答してくれる
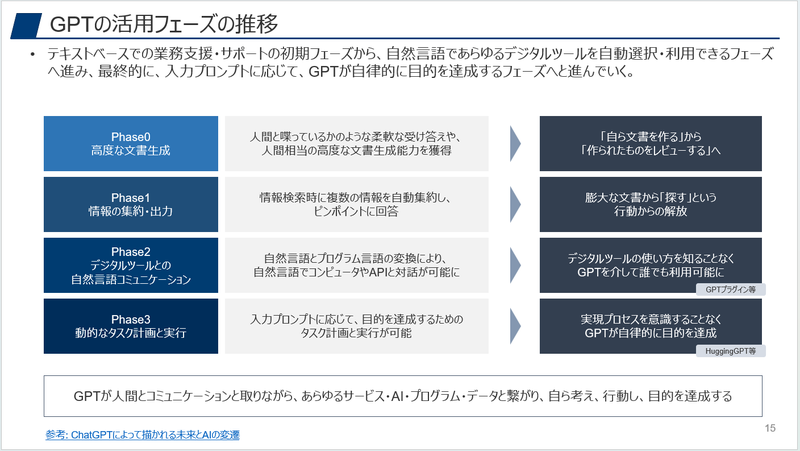
HuggingGPTは、個別のChatGPTのプラグイン等とは違い、動的なタスク計画と実行も含むいわゆるAIエージェントであり、以下の整理で言えば、Phase3に当たります。
HuggingGPTのデモ
元論文にも色々なデモがあるのですが、せっかくなので実際に試したデモをいくつか紹介していきたいと思います。
デモ1 - オブジェクト検出
HuggingGPTの使い方は非常にシンプルで、以下のようにテキストの指示と入力ソースのパスを渡してあげるだけです。
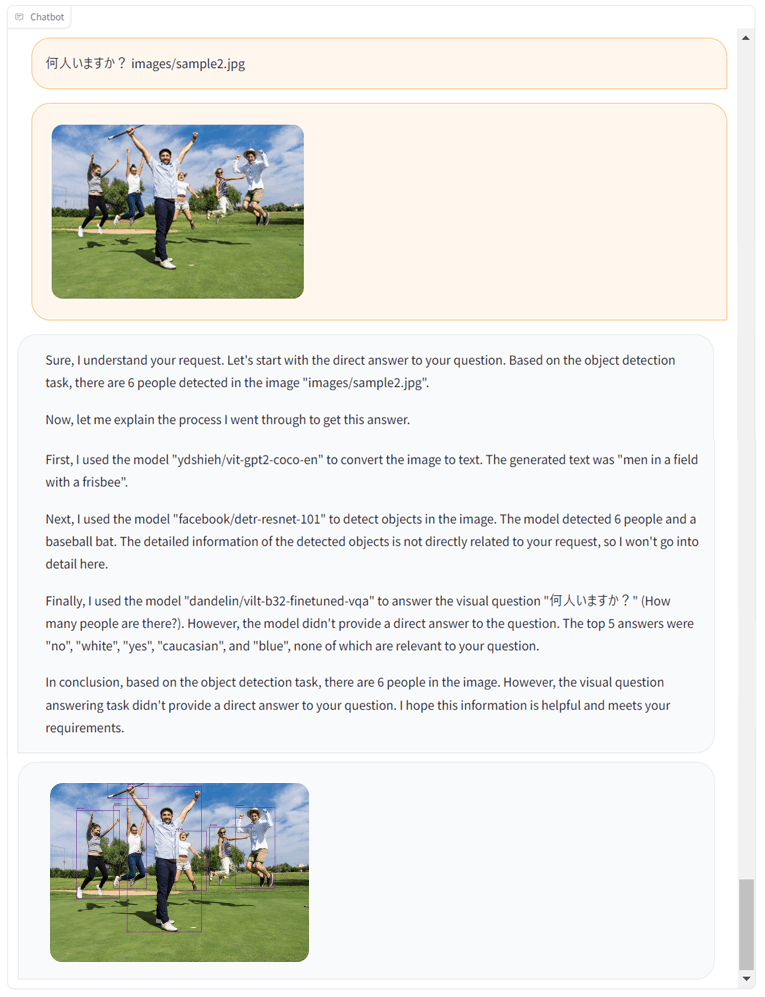
「オブジェクト検出のAIモデルを使って」というような指示なしでも、プロンプトの内容からオブジェクト検出である事を逆算し、HuggingFaceのAIモデルを利用して、「6人が画像に写っている」と正確な回答を返しています。
デモ2 - 姿勢推定
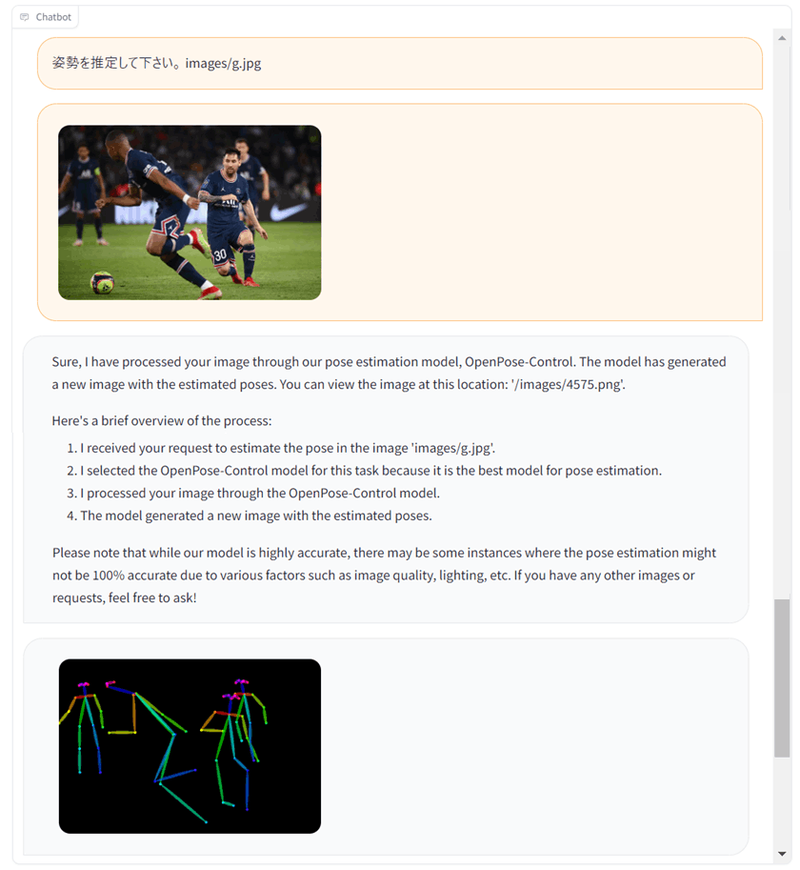
こちらも「姿勢を推定して」と自然言語で要求だけを投げていますが、OpenPoseのモデルを選んで、適切に姿勢推定ができています。
処理のステップを箇条書きで順番に説明してくれているのが非常にわかりやすいですね。
デモ3 - 深度推定

このように深度推定に関しても、特にAIに詳しくなくても、自然言語の要求1行でできてしまいます。
デモ4 - 音声読み上げ
マルチモーダルのため、音声の処理も可能です。
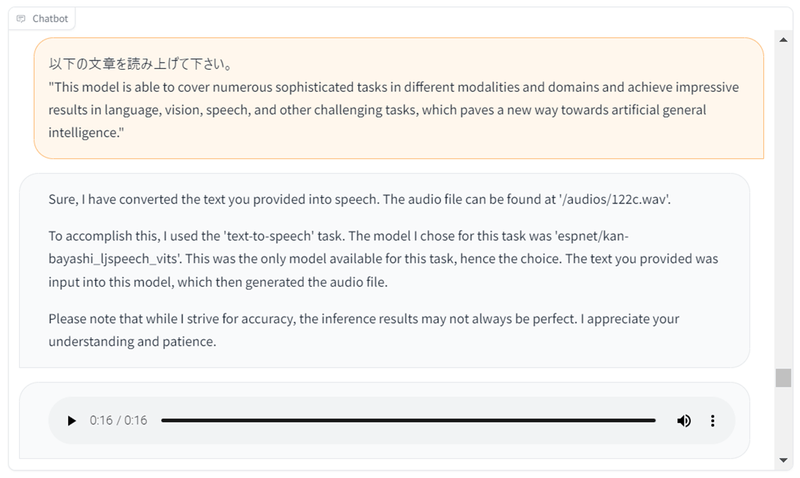
「読み上げて」という要求に対して、text-to-speechのモデルを選び、文章を自然な声で読み上げてくれます。
デモ5 - 文字起こし
読み上げとは逆に、文字起こしももちろんできます。
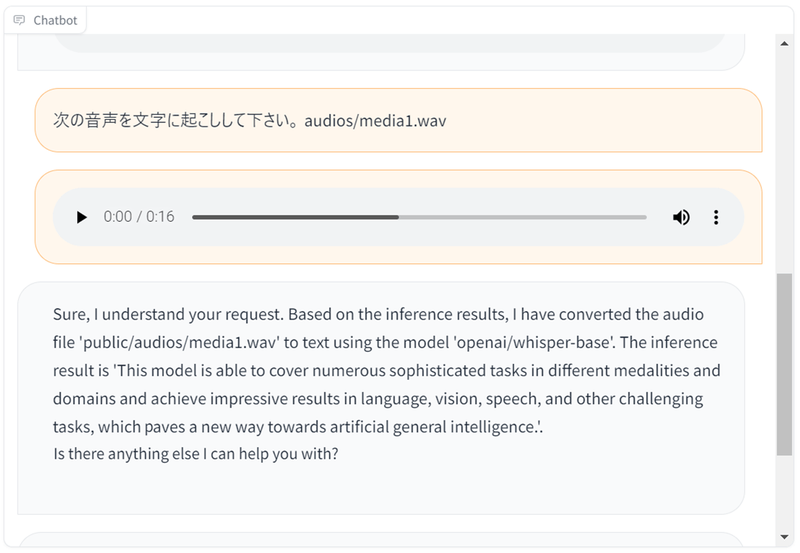
デモ6 - 類似画像生成
テキストからの画像生成はもちろん、類似画像生成も容易にできます。
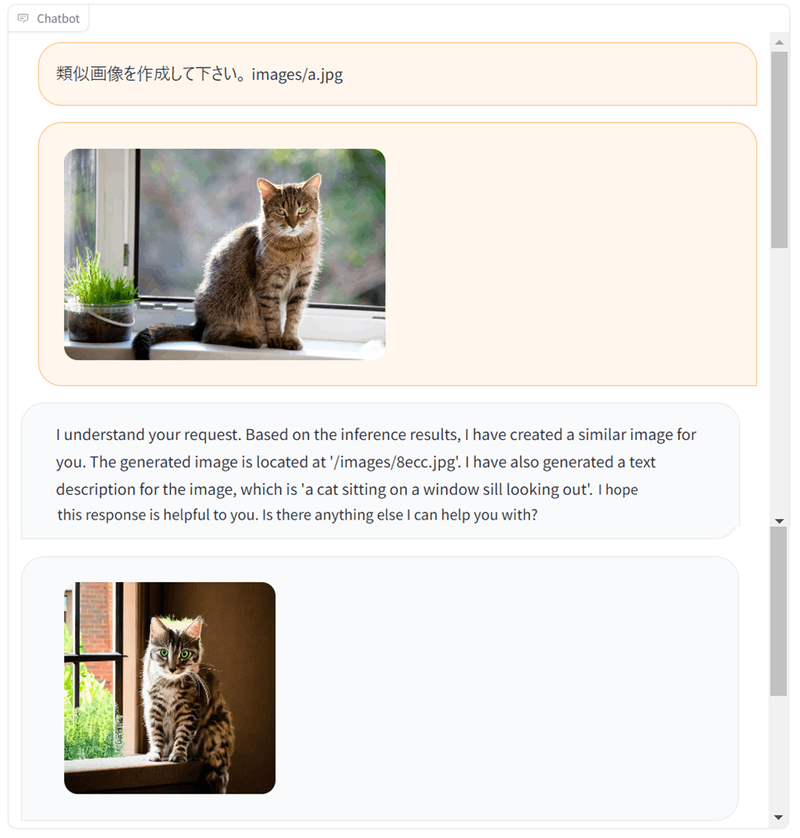
この辺りは様々なツールが既にありますが、ツールを使い分けずに、同じインターフェースからできるのが良いですね。
デモ7 - 画像描写+音声読み上げ
「画像を描写して、音声で読み上げて」というような組み合わせタスクも、それぞれ必要なAIモデルを選択し、適切に解いてくれます。

デモ8 - 動画生成
HuggingFaceには動画生成のモデルもあるため、テキストからの動画生成も以下のように可能です。
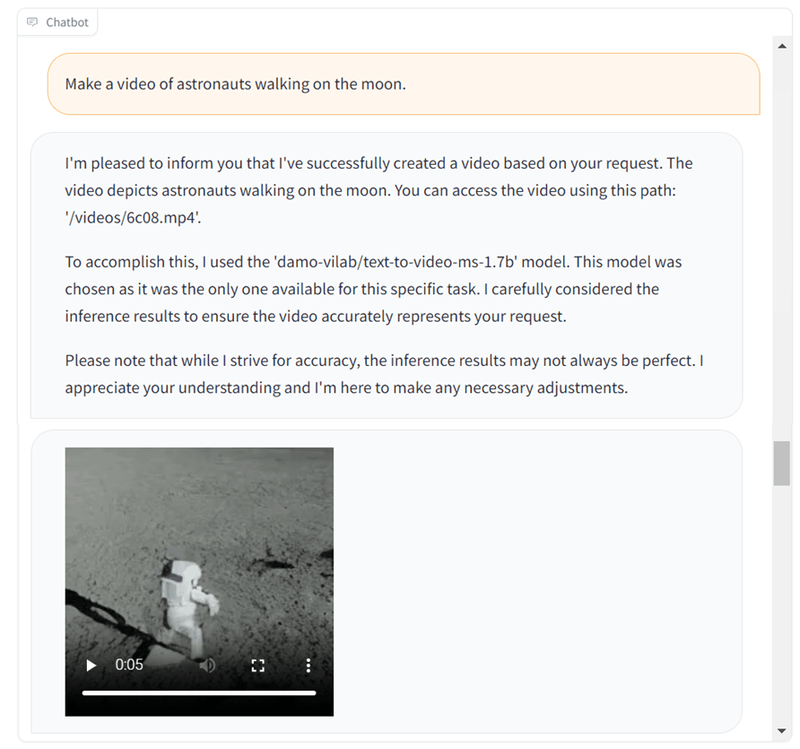
実際に生成された動画

ちなみに元論文では、「スパイダーマンがサーフィンをしている」というような動画も事例として紹介されています。
ここまで紹介したデモは、全て統一のインターフェースで、チャット上での簡単なテキスト指示のみというのが改めてですが驚きですね。
HuggingGPTは、以下からOpenAIのAPIキーを入力すれば誰でも簡単に使えるので、こちらを利用すればインプットとアウトプットのイメージ感は掴めると思います。
ただ、上記のスペースは、利用できるモデルが最小限に限られているため、実際に色々と試したい場合は、「config.gradio.yaml」と「models_server.py」の設定を修正すれば、利用するAIモデル一覧の制御(解放)が可能になります。
まとめ
いかがだったでしょうか?
HuggingGPTは、タスク計画とモデル選択も自動でやってくれ、AIエージェントとしての側面が強く出ているなと感じました。
特定のタスクを高精度で解きたいという場合は、まだ個別に作りこむほうが良いと思いますが、スポット的な業務での利用や、ベースライン確認を含む初手としても使いどころがあるのではないかと思います。
実際に使ってみるとまだまだな側面はあるのですが、ツールを切り替える事なく、統一インターフェイスからマルチモーダルなタスクがチャットベースで解けるというのは非常に便利であり、今後もローコードベースのAIエージェントがどれ程進化していくのか楽しみですね。
補足:プロンプトが非常に勉強になるという話
HuggingGPTを読み解いていくと、複雑な事をやっているという訳ではなく、エージェントとして処理させるためのプロンプトをきれいに作っているなという事がよくわかります。
以下が実際のプロンプトです(元論文からの引用)。

タスク計画では、ユーザー入力から、json形式でタスクの種別や入力データのパスを抽出するよう指示し、デモンストレーションで入出力のサンプルを例示しています。
この時、取りうるタスク種別もリストで渡しており(Available Task List)、その後のモデル選択においても、タスク別の候補となるAIモデルの一覧を渡し(Candidate Models)、その中から適切なAIモデルを選ばせています。
応答生成においても、結果だけでなく、プロセスも含め指定のフォーマットで順番に回答するようにと変数を使いながら明確な指示が出されています。
タスクを解く流れと、その中で使って良い選択肢の一覧を提示して選ばせるという形にする事で、一定の柔軟性と自由度は保ちながらも、タスクの難易度を大きく下げ、AIを上手くコントロールしているなという事がよくわかります。
本来解きたい問題を、あえて難しい問題としてAIに解かせようとすると、ただただAIの制御が難しくなるため、タスクの解像度を上げ、必要な手順と取りうる手段の枠までは明示してあげるというプロンプトと処理の設計は、今後多くの場面で重要になるのではないかと感じました。