AWS Glueを使う理由
Glueとは、ETLジョブの開発を行うための仕組みのことです。
大規模なデータ処理や抽出を行いたい時に使うのがSparkというフレームワーク。
弊社では過去取引の動向を分析するデータセットを作るときによく利用します。
Spark実行時には、Glueの開発エンドポイントを立ち上げる必要があります。
AWS Glueは金食い虫
Sparkの実行終了時には、Glueの開発エンドポイントを切る必要があります。
使わなくなったら自動で消してくれるわけではありません。(SageMakerのNotebook Instanceと同じ)
もし停止し忘れると、1日で約7,000円かかります....!
(5個のDPUを24時間利用した場合。5 * 0.44 * 24 * 130(円))
AWS Glueの料金
開発エンドポイントのプロビジョニング時には、5 個の DPU が割り当てられます。開発エンドポイントを 24 分 (5 分の 2 時間) 実行すると、DPU 時間あたり 0.44 USD で 5 DPU * 2/5 時間、つまり 0.88 USD が請求されます。
ミスを見越して、監視・停止できる機能を作った
毎回ちゃんと停止することを覚えよう!と思うのは得策ではありません。
lambdaを活用して、開発エンドポイントの消し忘れを防げるようにしました。
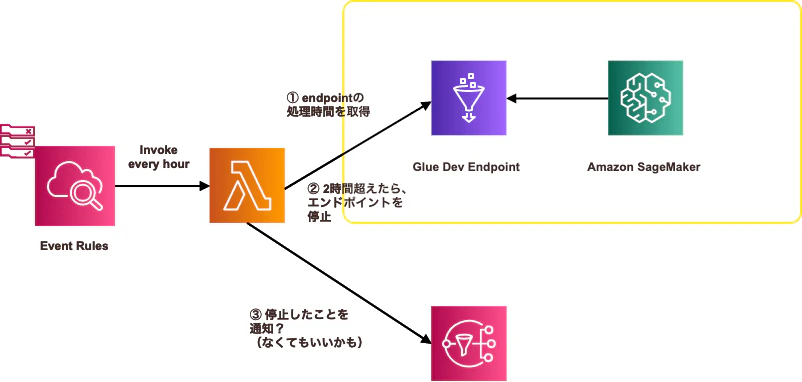
監視機能の概要
- 環境内のGlue開発エンドポイントと起動時間を定期的にチェックする
- 指定した時間以上起動していた場合、停止する
<簡易なアーキテクチャー図>
実装内容
Boto3というライブラリを使って、Glueの開発エンドポイントを取得・停止できるようにしました。
.py
import json
import boto3
from logging import getLogger
import datetime
MAX_TIME = 60 * 60 * 2
def lambda_handler(event, context):
logger = getLogger(__name__)
endpoints = get_glue_endpoints()
now_datetime = datetime.datetime.now(datetime.timezone.utc)
logger.info("endpoints exists -> {}".format(len(endpoints)))
longtime_endpoints = [e for e in endpoints if (now_datetime - e['CreatedTimestamp']).total_seconds() > MAX_TIME]
if longtime_endpoints:
logger.info("longtime endpoints -> {}".format(longtime_endpoints))
for e in longtime_endpoints:
logger.info(delete_glue_endpoints(e['EndpointName']))
return "{} Endpoints deleted".format(len(longtime_endpoints))
return "No Endpoints detected"
def get_glue_endpoints():
logger = getLogger(__name__)
logger.info("get glue client")
cli = boto3.client('glue')
endpoints = cli.get_dev_endpoints()['DevEndpoints']
logger.info("Glue Endpoint -> {}".format(endpoints))
return endpoints
def delete_glue_endpoints(name):
cli = boto3.client('glue')
response = cli.delete_dev_endpoint(EndpointName=name)
return response