この記事は、[一休.comアドベントカレンダー2017]の9日目です。
https://qiita.com/advent-calendar/2017/ikyu
こんにちは。@juri-tです。
一休.comでマーケティング施策の実行を支援するシステムの開発やデータ分析を担当しています。
前段
みなさんはスマートスピーカーは知っていますか?
ご存知の方も多いと思いますが、対話型の音声操作に対応したスピーカーで、音声で買い物をしたり家電を操作したりといったことが可能になります。今年の夏にGoogle Homeが発売されたことで注目を集めています。Google HomeのほかにもAmazon EchoやLINE Clova WAVEといった製品があります。
スマートスピーカーで音声操作で宿泊予約やレストラン予約ができる未来も着実に近づいてます!
Google Trendで見る検索数の推移
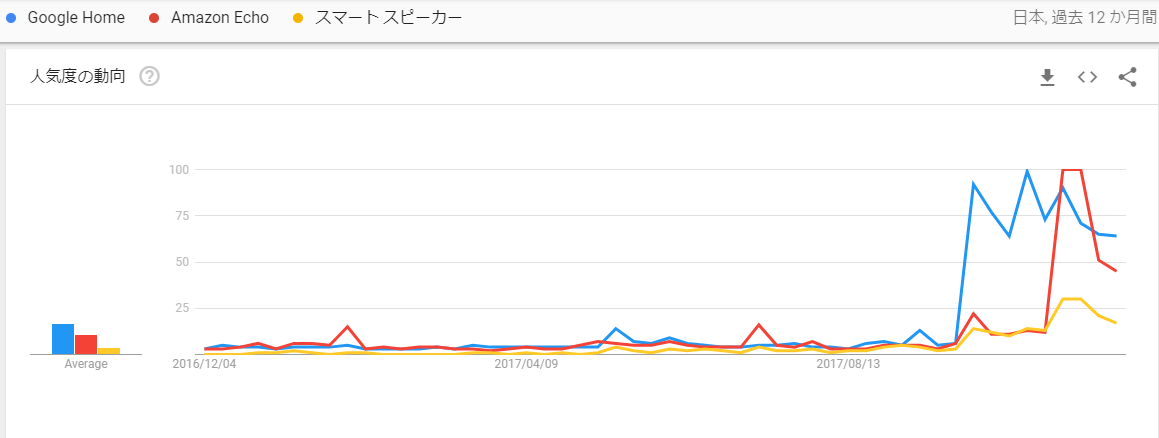
まだまだ検索数はそこまで多くはないですが、夏頃から検索されているのがわかります。
本題
スマートスピーカーが進歩しているのは、人が話す口語を理解する**「自然言語処理」が近年大きく進歩しているからです。Googleが開発したword2vec**といったこの数年で登場した技術も影響しています。といいつつ、私自身きちんと理解できていないので、この機会に試してみたいと思います。
word2vecを試してみるだけだと二番煎じな感じも否めないので、同じく自然言語処理で利用されることの多いLatent Dirichlet Allocation(LDA)と比較してみたいと思います。
Google Trendで見る最近の人気
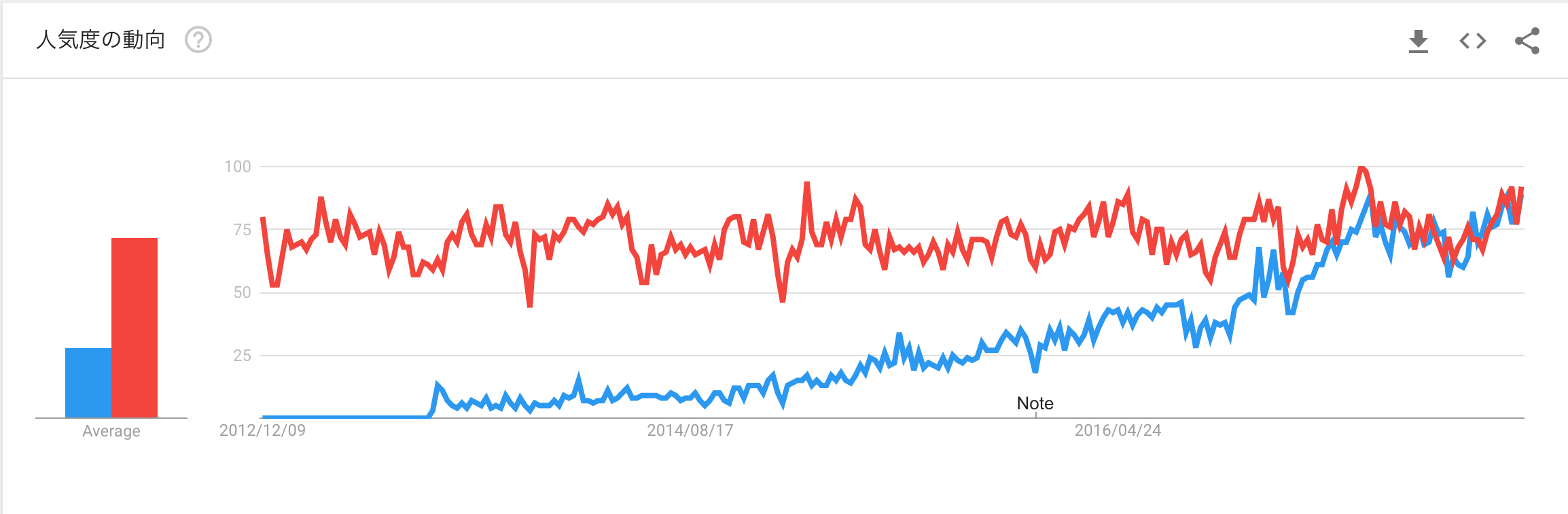
赤がLDA(Latent Dirichlet allocation)、青がword2vecです。
ここ数年でどんどん伸びていることがわかります。
Word2Vecとは
いくつかの解説を流し読みした感じだと、以下の感じのようです。
- 文章や単語を意味のベクトルで表現できる
- ニューラルネットワークによる学習
- 前後の文脈から、ある単語と一緒に使用されやすい単語の確率を推定
- 低次元の空間に埋め込むことで意味を表現できる
- 単語の足し算や引き算などの演算ができる
LDAとは
- 文章や文字をトピックの確率ベクトルで表現できる
- 基本的には単語の出現確率で学習
- 文章はトピックの分布で表現される(ニュース50%、芸能30%、スポーツ20%など)
- トピックは単語の分布で表現される(スポーツは「野球」「サッカー」「テニス」など)
それぞれベクトルで表現でき、低次元の意味を解釈できそうになるところは近いものの、いくつか違いが見えますね。とは言っても百聞は一見に如かずということで、それぞれ試してみましょう。
(私の理解なので、上記は間違っているかもしれません。ご容赦ください)
Pythonでやってみた
word2vec
データ準備
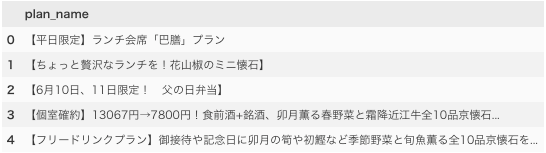
レストランのプラン名をPandasに読み込んでいます。
手元で試したい場合は、適当に文章のデータを用意してください。
前処理
日本語で自然言語処理するときの必須処理です。定番のMeCabで行いました。
ググれば詳細な記事がたくさんあるんで、MeCabの説明は割愛します。
また、ストップワードの除去やステミングなどは今回やりません。
import MeCab
def get_token_list(text):
token_list = []
tagger = MeCab.Tagger("-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd")
tagger.parse('')
node = tagger.parseToNode(text)
while node:
feats = node.feature.split(',')
if feats[0] in ['名詞', '形容詞']:
token_list.append(node.surface)
node = node.next
return token_list
df['token'] = df.plan_name.map(lambda x: get_token_list(x))
学習
ハイパーパラメータは特にいじらず、初期値を使って学習してみます。
from gensim.models import word2vec
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentence = list(df['token'])
model = word2vec.Word2Vec(sentence, min_count=1)
予測
学習が終わると、下記のメソッドで知りたい単語に類似している単語を抽出できます。
model.most_similar(positive=['パスタ'], topn=10)
model.most_similar(positive=['寿司'], topn=10)
パスタに近い単語

寿司に近い単語

なんとなく良い感じです。
LDA
続いてLDAで試してみます。
データはword2vecと同じものを使います。
学習
単語とIDを辞書を作り、各ドキュメントにおける単語に重み付けをします。
単語の重み付けはTfIdfで行いました。
from gensim import corpora, models, similarities
dictionary = corpora.Dictionary(sentence)
corpus = [dictionary.doc2bow(text) for text in sentence]
tfidf_instance = models.TfidfModel(corpus)
lda = models.ldamodel.LdaModel(corpus=tfidf_corpus[corpus], id2word=dictionary, num_topics=10)
予測
LDAの場合は、単語から類似する単語を探すこと直接できません。(たぶん)
単語が属する確率の高いトピックと、そのトピックを代表する単語がわかります。
パスタが属するトピック
DataFrame(lda.get_document_topics(dictionary.doc2bow(['パスタ'])))[1]
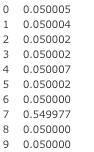
トピック7が高いので、「パスタ」はトピック7の意味合いで使われる単語のようです。
では、「トピック7」とはどんなトピックなんでしょう?
トピック7に属する単語から雰囲気を掴んでみます。
for word, rate in lda.show_topic(7):
print('{}: {:.3f}'.format(word, rate))

余計なデータも入ってますが、なんとなくパスタと一緒に使われそうなトピックです。
寿司が属するトピック
DataFrame(lda.get_document_topics(dictionary.doc2bow(['寿司'])))[1]
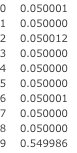
こちらはパスタとは異なるトピック9に属しているようです。
こちらもトピック9に属する単語から雰囲気を掴んでみます。
for word, rate in lda.show_topic(9):
print('{}: {:.3f}'.format(word, rate))

こちらもノイズがありつつ、近そうな単語も抽出できています。
ただ、word2vecと比較するとなんとなく分類できている感はあるものの、もう少し前処理やパラメータチューニングなどやらないと精度は低そうです。
まとめ
今回どちらも使ってみた感想としては、word2vecのほうがシンプルに使え、精度も高い印象を受けました。
それにしても、どちらもPythonで簡単に使えるのはすごいですね。
みなさんもお持ちのデータでぜひお試しください。
明日は @yu-saさんによる「ドメイン駆動でインターフェース指向な開発」です。
参考にさせていただきました
word2vec
https://m0t0k1ch1st0ry.com/blog/2016/08/28/word2vec/
https://rare-technologies.com/word2vec-tutorial/
LDA
https://radimrehurek.com/gensim/wiki.html#preparing-the-corpus
http://kensuke-mi.hatenablog.com/entry/20131021/1382384297
https://rstudio-pubs-static.s3.amazonaws.com/79360_850b2a69980c4488b1db95987a24867a.html