S3をファイルシステムとしてマウントするためのデーモンをつくっています。ホームディレクトリ全体を共有できてしまえば、dotfilesまわりのセットアップを頑張らなくてもよいのでは、というのが開発の動機です。
なので、既存のS3を便利に見れるものと言うよりも、セキュアかつパフォーマンスがなるべく(ファイルによらず)フラットで高速なファイルシステムを目指しています。
juntaki/bucketsync: S3 backed FUSE Filesystem written in Go with dedup and encryption.
使い方
まずは、設定ファイルを作成します。$HOME/.bucketsync/config.ymlにファイルができます。S3のクレデンシャルが平文で入ってしまうので取扱は注意です。出力されたファイルには暗号化や圧縮のオプションがありますが、記事公開の時点では実装が間に合ってないため意味はないです。。
bucketsync config --bucket <Bucket name> \
--region <Region, e.g. ap-northeast-1> \
--accesskey <AWS access key> \
--secretkey <AWS secret key> \
--password <Password for data encryption>
bucket: ""
region: ""
access_key: ""
secret_key: ""
password: ""
logging: production
log_output_path: /home/juntaki/.bucketsync/bucketsync.log
cache_size: 1024
extent_size: 65536
encryption: true
compression: true
あとは適当なディレクトリに、マウントするだけです。
bucketsync mount --dir /path/to/mountpoint
アンマウントするには、このコマンドです。
bucketsync unmount
仕組み
使っているライブラリを中心に、全体的な設計を説明します。
FUSE
Linuxでは、FUSEという仕組みでユーザー空間でファイルシステムを作ってマウントすることが出来ます。
カーネルのFUSEモジュールを使うlibfuseを使って実装する方法もありますが、今回の実装ではGoで書かれたライブラリの、hanwen/go-fuse: FUSE bindings for Goを使っています。go-fuseで定義されているインターフェースを実装すれば、簡単にファイルシステムが作れます。
bucketsyncでは、pathwalkのあたりをガッツリ書きたかったので、pathfsを使っています。なので、実装したインターフェースはpathfs.Filesystemです。
データの格納方法
S3コンソール方式の問題
既存のS3を便利に見れるようにFUSEでマウントしようとすると、(S3のコンソールから見てもそうなってるように)オブジェクトのキーとファイルパスを1対1で対応させると思います。たとえば、マウントポイントからdirディレクトリの下に色々とファイルを格納すると、こんな感じのキーのオブジェクトが複数できます。
/dir/test1.txt
/dir/test2.txt
/dir/test3.txt
/dir/test4.txt
ここで、dirディレクトリをリネームすると、なんと、配下の全オブジェクトをリネームしなくてはなりません。(4つくらいならまだいいですが)
下記にもあるように、これはデータ構造の問題なので、プログラムの工夫でどうにかするにも限界があります。
Support for deep directory rename · Issue #312 · s3fs-fuse/s3fs-fuse
それに加えて、クライアントサイドでオブジェクトの暗号化や圧縮をしようと考えたとき、ランダムリード性と両立させようとすると、それらの実装の選択肢はかなり狭くなります。
bucketsyncのデータ構成
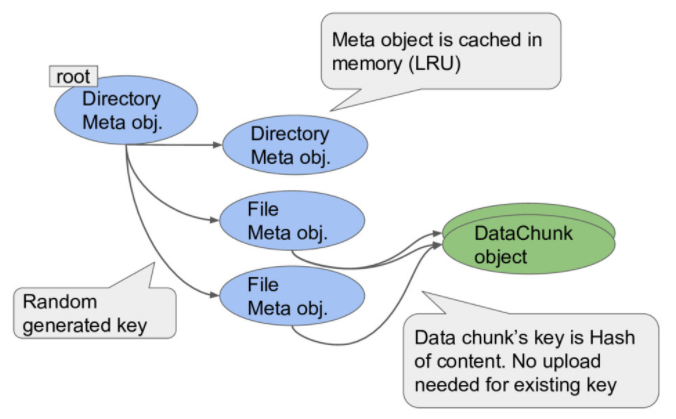
ファイルをS3のオブジェクトとして見ることを諦めると、いろいろな実装が考えられます。bucketsyncでは普通のファイルシステムのようにメタデータのオブジェクトとデータのオブジェクトを分けて格納しています。先程のリネーム問題はディレクトリのメタデータを一つ書き換えれば済むようになります。
メタデータの形式はfilesystem.goに書いています。
高速化の工夫
ローカルへのキャッシュ
メタデータだけは、pathwalkで頻繁に参照されるのでローカルにLRUでキャッシュします。@cache.go
また、S3へのAPIアクセスはAWS公式SDKを利用しています。
aws/aws-sdk-go: AWS SDK for the Go programming language.
ハッシュ:murmur3 hash
また、データ格納用のオブジェクトにはそのデータのハッシュをキーとしてつけることで、重複排除を実現しています。ハッシュはセキュアでなくてもよいので高速なmurmur3を採用しました。
spaolacci/murmur3: Native MurmurHash3 Go implementation
データのシリアライズ
メタデータはGoのオブジェクトで扱いたいので格納と読み出しで頻繁にSerializeとDeserializeする必要があります。ベンチマークを見ると、JSONのようなリフレクションを必要とする実装より、コード生成してしまうprotocol buffersなどの方が高速なようです。(あるいは、手で作ってしまっても良さそうですが。)
alecthomas/go_serialization_benchmarks: Benchmarks of Go serialization methods
※実装はまだJSONですが・・
あとがき
まだマウントできた!というレベルですが、徐々に使い物になるように改善していきます。
参考
juntaki/bucketsync: S3 backed FUSE Filesystem written in Go with dedup and encryption.
Understanding Filesystem using go-fuse, from scratch // Speaker Deck