※注意
以降に記載の通り、執筆時点(2020年8月)でapache-incubatorに登録されたばかりのプロジェクトであり、案の定公式ページの移動なども頻繁に起きています。
また、HPを見るとバージョンが新しくなるとパッケージ名がGeoSparkから変更されていくと考えられます。
今後しばらく変化が大きそうな感じがするので、公式ページなどで最新の動向をフォローするようにお願いいたします。
0. 経緯
PythonでGeoSpatialなデータを取り扱う際、小〜中規模なものであればGeoPandasをよく使うのですが、大規模なデータを取り扱おうとすると限界があります。
そうすると、軽く調べた感じではPostgreSQLの拡張機能であるPostGISがよく使われている印象で、他にNoSQLだと例えばMongoDBなどでもGeometry型を使えそう(参考)でしたが、いかんせんデータベースを立ち上げてスキーマを用意してテーブルorコレクションを作って、、、というのは結構面倒で、この辺り興味はあるのですがまだ手を出せていません。
個人的には大規模なデータ処理にはよくpysparkを使うのでこれを使って何か出来ないか、と探しているとGeoSparkなるものを見つけました。
まだまだ発展途上のライブラリのようですが、見て頂ければ分かる通りで2020-07-19(※記事執筆日時:2020-08-08)にはApache Sedonaの名前でApache Incubatorに登録されています。
(あまり詳しくないのですが、今後うまく軌道に乗れれば正式なApacheプロジェクトになる、ということのようです。また、管理がApache側へ移るので上記のリポジトリ・ドキュメントも~~そのうち移動されると思います。~~移動しました。)
大規模なデータを処理出来る可能性を持ちつつ、pandasやgeopandasに比較的近い感覚(スキーマ設計などせず適当な感じでも使える)でデータ処理可能なのはかなり面白そう、ということで少し遊んでみた次第です。
1. 環境構築
※以下、Apache Spark、pyspark自体の初歩的な説明は省略します。
手元の環境:
Linux(Ubuntu20.04)
(省略しますが、Windowsでも大体同じ雰囲気で作れます)
Python環境はpyenv+miniconda3(つまりconda)で用意しましたが、別に何でも良いと思います。
1-1. 仮想環境作成
例えば以下のようなYAMLファイルを用意:
name: geospark_demo
channels:
- conda-forge
- defaults
dependencies:
- python==3.7.*
- pip
- jupyterlab # for test
- pyspark==2.4.*
- openjdk==8.*
- pyarrow
- pandas
- geopandas
- folium # for test
- matplotlib # for test
- descartes # for test
- pip:
- geospark
-
folium、matplotlib、descartes、jupyterlabはgeospark的に必須ではないですが、テスト用に可視化する目的で入れています -
pysparkとjava8は自前で用意しているなら不要です- なお、
geospark(1.3.1)が対応するApache Sparkのバージョンは執筆時点(2020年8月)で2.2 - 2.4系までなので、pysparkは2.4系を指定します
- なお、
これで
conda env create -f create_env.yml
# 作った仮想環境に入る
conda activate geospark_demo
などとすると、geospark_demoという名前のconda仮想環境が作れます。
(パッケージや仮想環境名などの諸々の調整は例えばここなどを参照)
(別にconda使わなくても同等なことは出来ると思います)
1-2. 環境変数設定
上記の例(conda仮想環境利用)であればPATHの設定や、JAVA_HOMEくらいまでは勝手にやってくれますが、いくつか追加で環境変数を設定する必要があります。
まずgeosparkでは内部でSPARK_HOMEを参照するときがあるので、Apache Sparkのインストール場所を環境変数で設定します。
なお、今回の例のようにcondaなどでApache Sparkを入れている場合、どこにSparkの本体がいるのか分かりづらいときがあるので、例えばここを参考にして
# Apache Sparkのインストール場所を確認
echo 'sc.getConf.get("spark.home")' | spark-shell
# SPARK_HOME設定
export SPARK_HOME=<上で出てきたパス>
みたいにして設定します。筆者はSPARK_HOME=/home/<ユーザー名>/.pyenv/versions/miniconda3-latest/envs/geospark_demo/lib/python3.7/site-packages/pysparkみたいな感じになりました。
また、インストールされているpyarrowのバージョンが0.15以降の場合、ここに従って
export ARROW_PRE_0_15_IPC_FORMAT=1
を設定しておく必要があります(pyspark2.x系で必要な設定)。
あるいは、pyarrow==0.14.*を指定してインストールしておくようにします。
この辺いちいち手でやるのは面倒なので、個人的にはファイルに書いておいてsourceするようにするか、あるいはDockerでENVなどを使って設定するなどしています。
2. 動作確認
公式のGitHub上にpython用のJupyter Notebookと必要なテストデータ(python/data/に格納)が置いてあるので、それらを使って問題なく動作することを確認します。
例えば、
# 作業ディレクトリに移動
cd /path/to/workdir
# githubからnotebookをダウンロード
wget https://raw.githubusercontent.com/apache/incubator-sedona/master/python/GeoSparkCore.ipynb
wget https://raw.githubusercontent.com/apache/incubator-sedona/master/python/GeoSparkSQL.ipynb
# svnを使ってgithubから特定のディレクトリだけダウンロードする
svn export https://github.com/apache/incubator-sedona/trunk/python/data/
のような感じで取得出来ます。
なお、svnを使ったGitHubからのディレクトリのダウンロードはここやここを参考にしました。
あとはjupyterlabかjupyter notebookを立ち上げて↑のnotebookを実行します。
これで動作確認をしつつ、どういう雰囲気で使えるものかの参考になると思います。
2-1. 少し遊んでみる
↑の動作確認で使ったnotebookや公式ドキュメントのTutorialの方がよっぽどためになるのですが、せっかくなので自分でも少し遊んでみます。
実行概要
市区町村界データのshpファイルを使って、以下のようなことを試してみます:
- shpファイルをGeoPandasで読み込んで、parquetファイル(hiveテーブル)の形で保存
- ↑で作ったparquetファイルを読み込んで、Geometryタイプを含むDataFrameを生成・操作
以下、jupyterlab上で動作確認を行っています。
下準備
# 必要なライブラリのインポート
import os
import folium
import geopandas as gpd
from pyspark.sql import SparkSession
from geospark.register import GeoSparkRegistrator
from geospark.utils import GeoSparkKryoRegistrator, KryoSerializer
from geospark.register import upload_jars
# sparkセッションの生成
upload_jars()
spark = SparkSession.builder.\
master("local[*]").\
appName("TestApp").\
config("spark.serializer", KryoSerializer.getName).\
config("spark.kryo.registrator", GeoSparkKryoRegistrator.getName) .\
getOrCreate()
GeoSparkRegistrator.registerAll(spark)
テストデータ読み込み
sdf_japan = spark.createDataFrame(
# 全国市区町村界データをgeopandasで読み込み
gpd.read_file("path/to/<全国市区町村界データファイル名>.shp")
)
# 確認
sdf_japan.show(5)
# +-----+------+----------+----+------+----------+--------------------+--------+--------+--------------------+
# |JCODE| KEN| SICHO| GUN|SEIREI|SIKUCHOSON| CITY_ENG| P_NUM| H_NUM| geometry|
# +-----+------+----------+----+------+----------+--------------------+--------+--------+--------------------+
# |01101|北海道|石狩振興局|null|札幌市| 中央区|Sapporo-shi, Chuo-ku|235449.0|141734.0|POLYGON ((141.342...|
# |01102|北海道|石狩振興局|null|札幌市| 北区|Sapporo-shi, Kita-ku|286112.0|151891.0|POLYGON ((141.408...|
# |01103|北海道|石狩振興局|null|札幌市| 東区|Sapporo-shi, Higa...|261777.0|142078.0|POLYGON ((141.446...|
# |01104|北海道|石狩振興局|null|札幌市| 白石区|Sapporo-shi, Shir...|212671.0|122062.0|POLYGON ((141.465...|
# |01105|北海道|石狩振興局|null|札幌市| 豊平区|Sapporo-shi, Toyo...|222504.0|126579.0|POLYGON ((141.384...|
# +-----+------+----------+----+------+----------+--------------------+--------+--------+--------------------+
# only showing top 5 rows
DataFrame保存
# ファイルとして保存(デフォルトではsnappy.parquet形式)
sdf_japan.write.save("japan") # japanディレクトリ下にファイルが保存される
# hiveテーブル形式で保存(実体ファイルはデフォルトではsnappy.parquet)
spark.sql("CREATE DATABASE IF NOT EXISTS geo_test") # 必須でないが、データベース作成
sdf_japan.write.saveAsTable("geo_test.japan") # データベースgeo_test上のテーブルjapanとして保存
↑saveおよびsaveAsTableのオプションでformatやcompressionを変えることができ、zlib.orcやjson.gzipなどでも保存出来るようです。(それが嬉しいのかはさておき)
読み込み
# ファイル読み込み
# 実体ファイルが保存されているディレクトリを指定する。parquet以外の形式で保存した場合はloadのオプションでformatを指定する。
sdf_from_file = spark.read.load("japan")
sdf_from_file.show(5)
# +-----+------+-----+------+------+----------+--------------+-------+-------+--------------------+
# |JCODE| KEN|SICHO| GUN|SEIREI|SIKUCHOSON| CITY_ENG| P_NUM| H_NUM| geometry|
# +-----+------+-----+------+------+----------+--------------+-------+-------+--------------------+
# |32207|島根県| null| null| null| 江津市| Gotsu-shi|23664.0|11513.0|MULTIPOLYGON (((1...|
# |32209|島根県| null| null| null| 雲南市| Unnan-shi|38479.0|13786.0|MULTIPOLYGON (((1...|
# |32343|島根県| null|仁多郡| null| 奥出雲町| Okuizumo-cho|12694.0| 4782.0|POLYGON ((133.078...|
# |32386|島根県| null|飯石郡| null| 飯南町| Iinan-cho| 4898.0| 2072.0|POLYGON ((132.678...|
# |32441|島根県| null|邑智郡| null| 川本町|Kawamoto-machi| 3317.0| 1672.0|POLYGON ((132.487...|
# +-----+------+-----+------+------+----------+--------------+-------+-------+--------------------+
# only showing top 5 rows
# table読み込み
sdf_from_table = spark.table("geo_test.japan") # 読み込むテーブル名を指定
sdf_from_table.show(5)
# +-----+------+-----+------+------+----------+--------------+-------+-------+--------------------+
# |JCODE| KEN|SICHO| GUN|SEIREI|SIKUCHOSON| CITY_ENG| P_NUM| H_NUM| geometry|
# +-----+------+-----+------+------+----------+--------------+-------+-------+--------------------+
# |32207|島根県| null| null| null| 江津市| Gotsu-shi|23664.0|11513.0|MULTIPOLYGON (((1...|
# |32209|島根県| null| null| null| 雲南市| Unnan-shi|38479.0|13786.0|MULTIPOLYGON (((1...|
# |32343|島根県| null|仁多郡| null| 奥出雲町| Okuizumo-cho|12694.0| 4782.0|POLYGON ((133.078...|
# |32386|島根県| null|飯石郡| null| 飯南町| Iinan-cho| 4898.0| 2072.0|POLYGON ((132.678...|
# |32441|島根県| null|邑智郡| null| 川本町|Kawamoto-machi| 3317.0| 1672.0|POLYGON ((132.487...|
# +-----+------+-----+------+------+----------+--------------+-------+-------+--------------------+
# only showing top 5 rows
単純なファイルとしてもテーブル形式でも保存と読み込みが出来ることが確認出来ました。
なお、体感ではgeopandasからpysparkのDataFrameへ変換は遅いように感じたので、geopandas<->pysparkの変換は最小限の回数に抑えた方が良いのだと思いました。
※dtypes
sdf = sdf_from_file # 以下、ファイルから読み込んだ方をsdfとする
display(sdf.dtypes)
# [('JCODE', 'string'),
# ('KEN', 'string'),
# ('SICHO', 'string'),
# ('GUN', 'string'),
# ('SEIREI', 'string'),
# ('SIKUCHOSON', 'string'),
# ('CITY_ENG', 'string'),
# ('P_NUM', 'double'),
# ('H_NUM', 'double'),
# ('geometry', 'udt')]
geometryはgeosparkライブラリ内で定義されたudt型として扱われているようです。
(なので、geosparkの設定をせずにファイルやテーブルを読み込もうとするとエラーが起きます)
簡単なクエリの実行と確認など
公式ドキュメントから特に以下を参照:
- http://sedona.apache.org/api/sql/GeoSparkSQL-Constructor/
- http://sedona.apache.org/api/sql/GeoSparkSQL-Function/
- http://sedona.apache.org/api/sql/GeoSparkSQL-Predicate/
# spark sqlを使えるようにDataFrameをTEMP VIEWとして登録しておく
sdf.createOrReplaceTempView('esri_japan')
# 大元のデータ数確認
sdf.count() # 1907
# 経度:135-140、緯度:35-40の範囲でfilter
sdf_filtered = spark.sql("""
SELECT * FROM japan
WHERE ST_Contains(ST_PolygonFromEnvelope(135., 35., 140., 40.), japan.geometry)
""")
sdf_filtered.show(5)
# +-----+------+-----+--------+------+----------+----------------+-------+------+--------------------+
# |JCODE| KEN|SICHO| GUN|SEIREI|SIKUCHOSON| CITY_ENG| P_NUM| H_NUM| geometry|
# +-----+------+-----+--------+------+----------+----------------+-------+------+--------------------+
# |06401|山形県| null|西置賜郡| null| 小国町| Oguni-machi| 7612.0|3076.0|POLYGON ((139.911...|
# |06426|山形県| null|東田川郡| null| 三川町| Mikawa-machi| 7400.0|2387.0|POLYGON ((139.842...|
# |07364|福島県| null|南会津郡| null| 檜枝岐村| Hinoemata-mura| 557.0| 202.0|POLYGON ((139.259...|
# |07367|福島県| null|南会津郡| null| 只見町| Tadami-machi| 4366.0|1906.0|POLYGON ((139.366...|
# |07368|福島県| null|南会津郡| null| 南会津町|Minamiaizu-machi|15679.0|6707.0|POLYGON ((139.530...|
# +-----+------+-----+--------+------+----------+----------------+-------+------+--------------------+
# only showing top 5 rows
sdf_filtered.count() # 573 <- original: 1907
DataFrameの個数も減り(1907 -> 573)、ちゃんとフィルター出来ていそうだが念のため可視化して確認してみる
# matplotlib
gdf_filtered = gpd.GeoDataFrame( # geopandasに変換しておく
sdf_filtered.toPandas(),
geometry='geometry'
)
gdf_filtered.plot()
(plot結果)
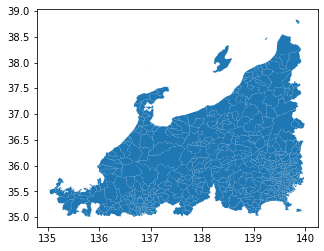
ちなみにですが、オリジナルの市区町村界データ全体をplotすると
gpd.read_file("path/to/<全国市区町村界データファイル名>.shp") \
.plot()
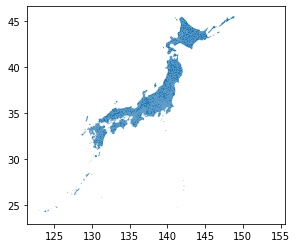
という感じなので、ちゃんとフィルタリング出来ていそうです。
また、インタラクティブに可視化するには例えばfoliumを使って、
m = folium.Map(
location=(37.5, 137.5), # 緯度、経度の順なので注意
zoom_start=7,
control_scale=True,
)
m.add_child(folium.LatLngPopup()) # クリックするとポップアップで緯度経度を確認出来る
# フィルタリングしたDataFrameをGeoJSONに変換してfoliumに渡す
m.add_child(
folium.GeoJson(gdf_filtered.to_json())
)
folium.LayerControl().add_to(m) # LayerControlを追加
m.save('df_filterd.html') # 保存
m # jupyter上で表示
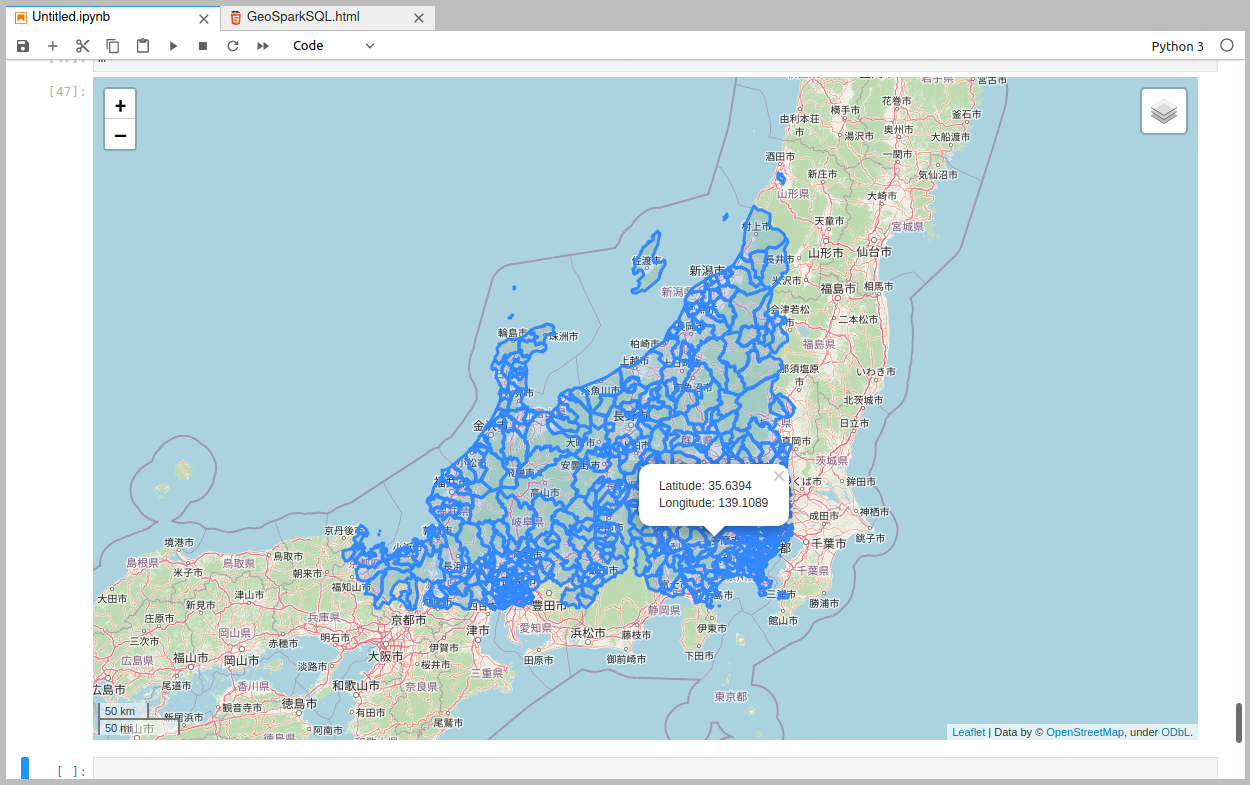
めでたくfolium上でも可視化出来ました。
3. 雑感
- 今回は小さいデータにごく簡単なクエリかけただけなのであまり嬉しさはなかったものの、PostGISのような雰囲気のことがSpark上で出来そうなのは面白かったです
- 後半で可視化するところは結局geopandas+matplotlibとfoliumでgeosparkあまり関係なかったのですが、可視化用の機能(GeoSpark Viz)もあるようなので、時間があるときに試せたら、と思います
- この辺に近いことが出来ると便利そう
- 序盤で書いたとおりApache Incubatorに入った関係で、今後の発展は期待出来そうですが仕様変更やパッケージ名の変更などがなされていって、今回書いたことがすぐに使えなくなるかもしれない。。。