アメリカ在住のJava女子です。
StreamSetsというサンフランシスコのスタートアップ(というか自分が働いている会社なんですがw)が開発している、Data Collecterについて紹介してみます。
Data Collectorとは何?
会社のホームページによると
StreamSets Data Collector is a lightweight, powerful engine that streams data in real time. Use Data Collector to route and process data in your data streams.
軽量でパワフルなデータストリーミングエンジンで、データの移動と変換が簡単にGUIで出来ますよ、という製品です。オープンソース製品なのでソースコードが公開されています(github.com/streamsets)
例えばローカルのファイルを、field validationをしながらHadoop FSに移動させたり、Apache Web serverのログをElasticSearchに移動させ、途中の過程でalertを検出したり。
製品のGUI画面です。ホームページより引用。
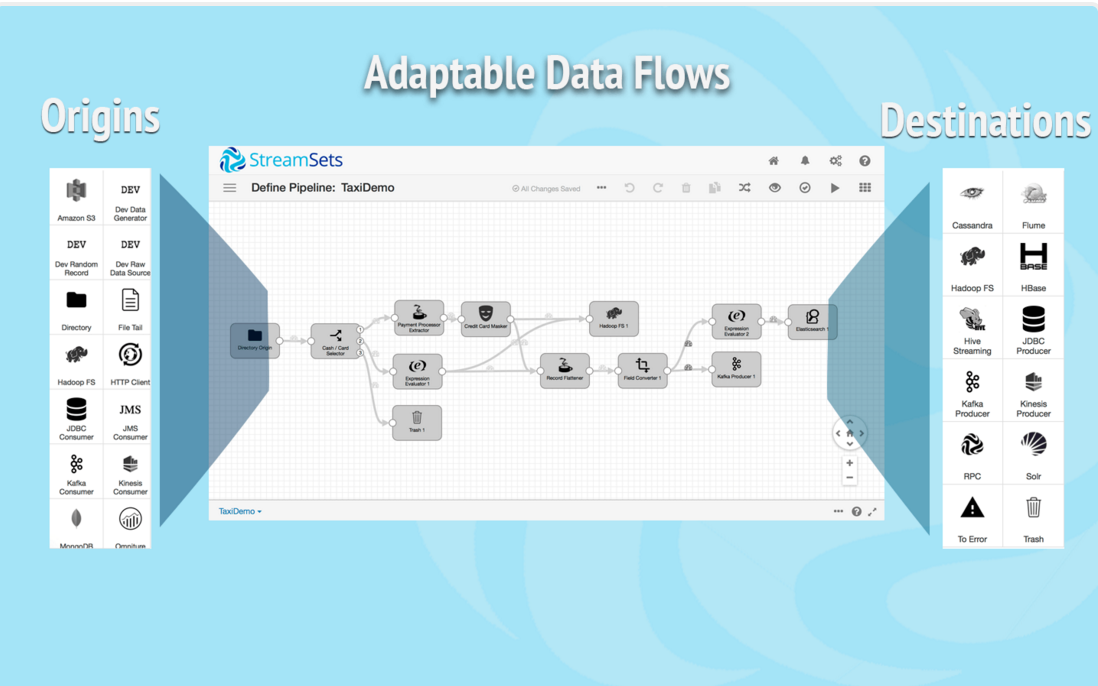
現時点でのデータ入力元
- ローカルファイル
- File Tail
- Hadoop FS
- JDBC
- HTTP Client
- Amazon S3
- Kafka
- MongoDB
- Omniture
- MapR
- RPC
- UDP
- RabbitMQ
データ入力先は
- Cassandra
- Elasticsearch
- Flume
- Hadoop FS
- HBase
- Hive Streaming
- InfluxDB
- JDBC
- Kafka
- Kinesis
- MapR
- RabbitMQ
- SDC RPC
- Solr
- Error/Trash
インストールしてGUI画面を見ればなんとなく分かると思うので、早速インストールと起動をしてみよう。
インストールと起動
動作環境
- Mac OS
- Java 1.8インストール済み
streamsets.comのサイトへ行き、右上のDownload Open Sourceをクリック。
ダウンロードサイトからtarballをダウンロード。適当なディレクトリで、
$ tar xvzf streamsets-datacollector-all-1.2.2.0.tgz
$ streamsets-datacollector-1.2.2.0/bin/streamsets dc
ブラウザからhttp://localhost:18630 にアクセスすると、ログインページが表示されます!
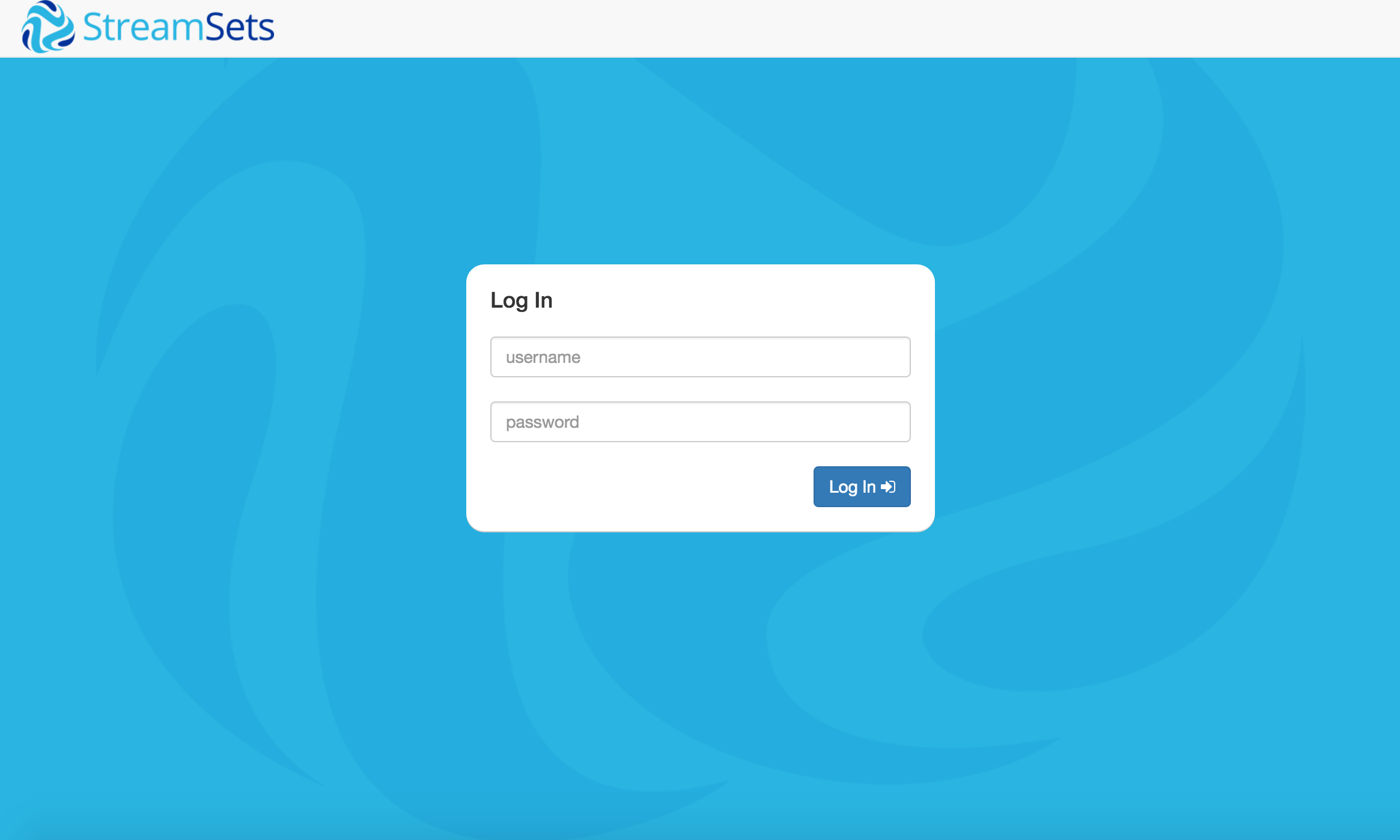
UsernameとPasswordは両方 admin でログイン。
Create new pipelineのボタンをクリック。適当にパイプラインの名前を入力します。
こちらがGUI画面です。(初期状態はエラーが2つ表示されているはずです)
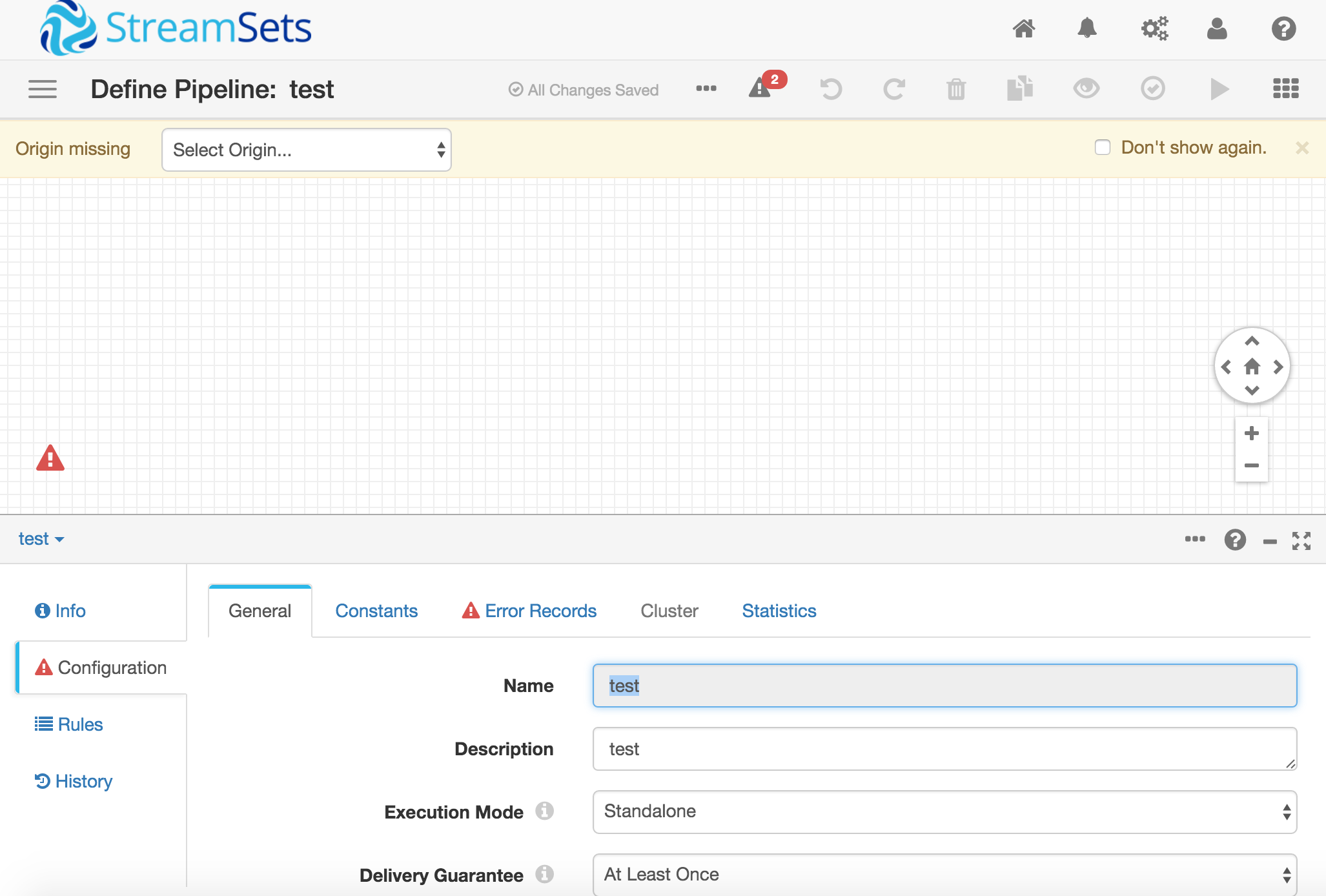
このキャンパスの上に入力元や入力先のアイコンを置いて、データストリーミングのパイプラインを作っていきます!
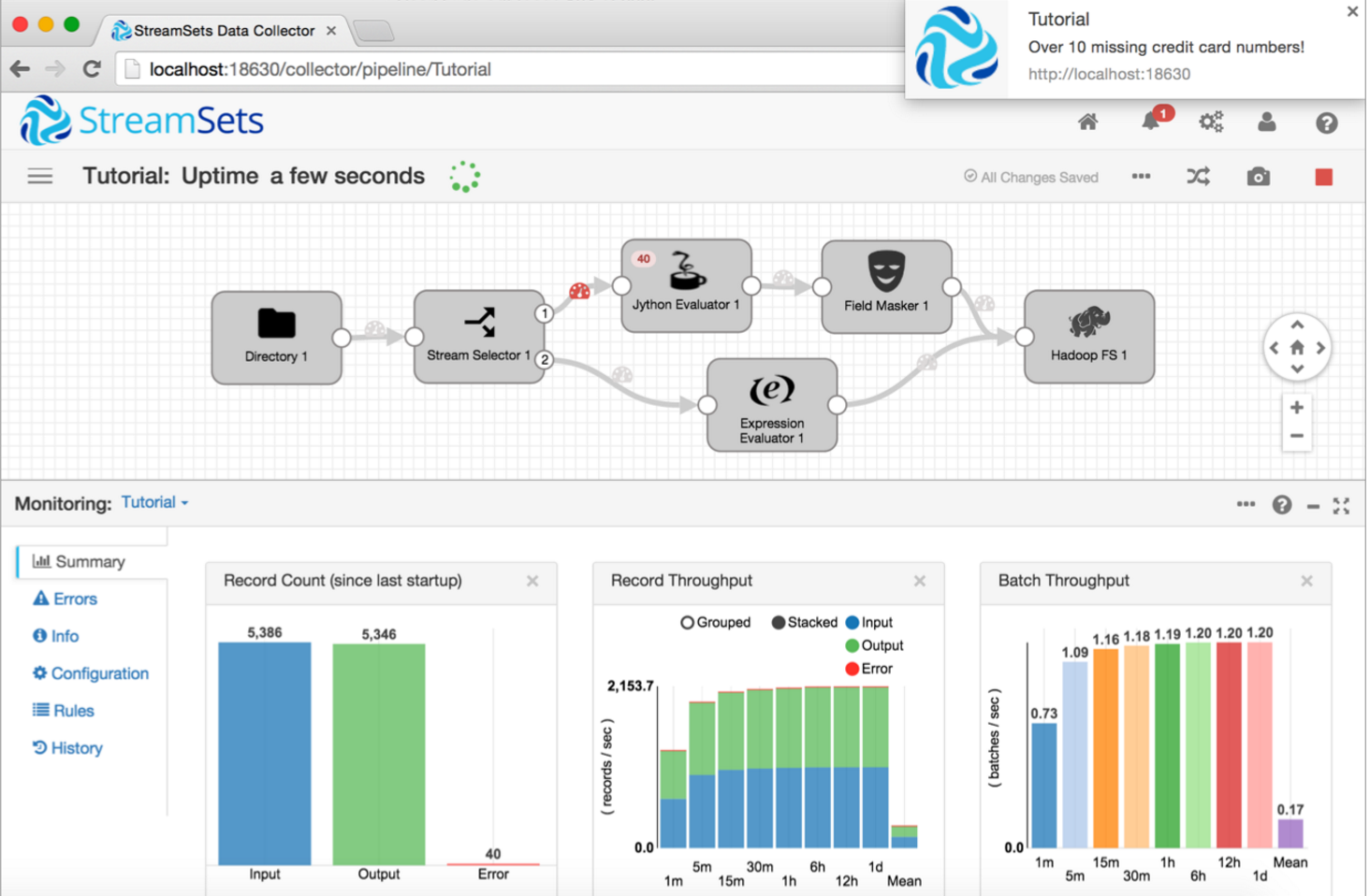
例えば、ローカルのファイルからデータを2種類に分け、Jython EvaludatorとField Maskerを使いながらデータをクリーンアップし、最終的にHadoop FSへと移動させるパイプライン例。
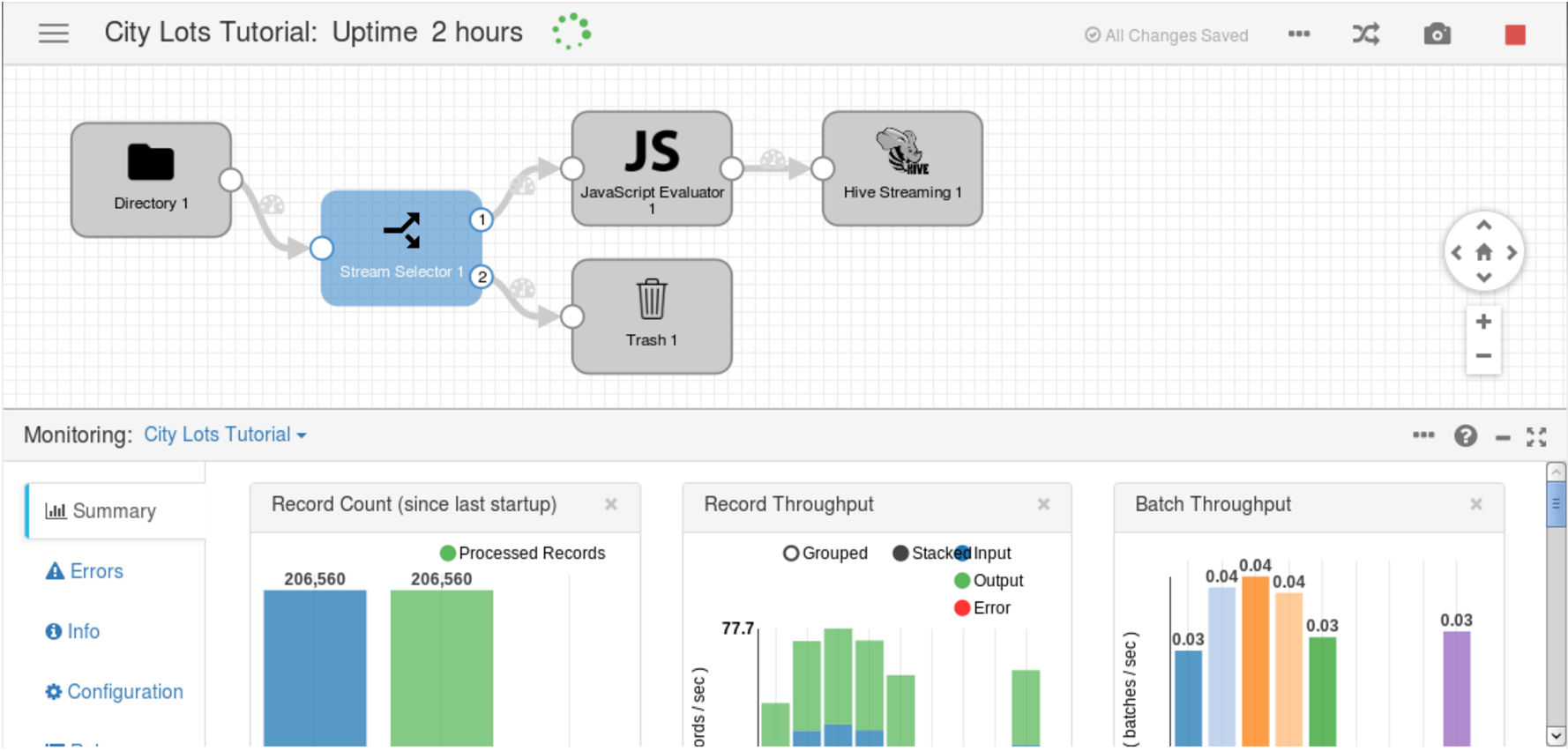
膨大なJSONオブジェクトをApache Hiveに移動させる例。
とりあえず今回はここまで。次回はチュートリアルに乗っているパイプラインを実際に作ってみたいと思います。