こんにちは。組込、ゲーム、Webアプリ、iOSアプリ、サイネージ制御システムなんかを色々作ってるソフトウェアエンジニアです。
2年半前ぐらいに汎用的なスクリプト言語として、シェルだけで実現が厳しいことはPythonで書くべきだと思い、苦しみながらPythonを覚えようとしていました。
たまにしか使わないので、ifやforループの書き方を毎回忘れてしまうレベルでした。
しかし、1年半前ぐらいに機械学習・データサイエンスの本でJupyter NotebookというREPLがあるということを知り、ものは試しに使ってみようということで使ってみたら、機械学習・データサイエンスに限らず、日常の試行錯誤が必要な作業全般に便利なものだということがわかり、広めたくてこの記事を書いています。
Jupyter Notebookというと、データ解析のイメージが強いかと思います。
ですが、パケットをちょっと送ってみたり、複雑なこともできる電卓として使ったり、各種ファイルフォーマットの変換をしたり、ややこしいファイルコピーをしたりと、リアルタイム性が必要でなく、1回しかやらないかもしれないけれども2回目以降もあるかもしれない、みたいな雑多なことをするのに非常に適しています。
ステップ実行のような感じで、文単位で試して結果が想定通りか間違っているかを確認してスクリプトを書いていけるので、素早く確実性が高いコードが書けます。
また、動的型言語でプログラムを書いていると補完があまり効かない状態でコードを書くことになりがちという欠点があるのですが、Jupyter Notebookの場合、実体化されたインスタンスを直接調査しながらメソッドやフィールドの補完ができるので、静的型言語並に補完が効いてリファレンスを苦労して読む時間が大分減らせます。
今回は、
- 解析に使ってみたケース
- 電卓として使ってみたケース
- バイナリデータを作ってパケットを出すのに使ってみたケース
- フォーマット変換をしてみたケース
の4ジャンルを説明してみようと思います。
解析に使ってみたケース
ソフトウェアを作っていると、デバッガでは追えない規模の動作解析だったり、既存ツールでは出来ない調査をしなければいけない場面って結構ありますよね。
TCPやUDPで制御できるはずのデバイスが、たまに制御できていないから調査してくれとお願いされたり、センサデータがどういう値を返してくるのか、仕様書とにらめっこせずにカジュアルに確認したかったり、特定のフォントで表示できる文字と出来ない文字があるから、システムで使える文字の範囲を決めてくれとお願いされたり。
基本的には、ログを解析するとか、メタデータを読み出してなんとかすることになるのですが、Jupyterを使うとアドホックに確認しながら進めるのが心地よいです。
Wiresharkでキャプチャしたパケットの解析
TCP/UDPで制御しているデバイスがどうもたまに制御できていないことがある、という問題の調査依頼を受け、原因が制御ソフトウェア側にあるのか、ネットワークにあるのか、デバイス側にあるのか原因究明しなければいけないことがありました。とりあえず、通信を見ればなんとかなるだろうと思い、ポートミラーリングができるスイッチングハブを用意してもらって、Wiresharkのコマンドラインツールであるtsharkで一日数GBレベルのパケットを収集してもらいました。
得られたキャプチャファイル、.pcapファイルを以下のようなコードでPandas DataFrameに変換します。
def makeDfFromPcap(filename):
p = dpkt.pcapng.Reader(open(filename, 'rb'))
dDict = {'t':[], 'src':[], 'dst':[], 'type':[], 'srcport':[], 'dstport':[], 'length':[]}
count = 0
for ti,buf in p:
try:
eth = dpkt.ethernet.Ethernet(buf)
except dpkt.NeedData:
pass
if type(eth.data) == dpkt.ip.IP:
ip = eth.data
src = ip.src
dst = ip.dst
src_a = socket.inet_ntoa(src)
dst_a = socket.inet_ntoa(dst)
t = 'IP'
srcPort = 0
dstPort = 0
if type(ip.data) == dpkt.udp.UDP:
srcPort = ip.data.sport
dstPort = ip.data.dport
t = 'UDP'
elif type(ip.data) == dpkt.tcp.TCP:
srcPort = ip.data.sport
dstPort = ip.data.dport
t = 'TCP'
dDict['t'].append(ti)
dDict['src'].append(src_a)
dDict['dst'].append(dst_a)
dDict['type'].append(t)
dDict['srcport'].append(srcPort)
dDict['dstport'].append(dstPort)
dDict['length'].append(ip.len)
count += 1
if count % 10000 == 0:
print(count)
df = pd.DataFrame(dDict, columns=['t','src','dst','type','srcport','dstport','length'])
return df
df = makeDfFromPcap('cap_00001_20191216.pcap')
df

あとはDataFrameでGroup Byして集計することで、送信元IPアドレスと送信先IPアドレスでどの程度の通信が発生しているかを確認することが出来ます。
pd.DataFrame(df.groupby(['src','dst'])['length'].sum().sort_values(ascending=False) * 8 / (df.t.max() - df.t.min()))
# 使用帯域 (単位: bps)

pd.DataFrame(df.groupby(['src','dst']).size().sort_values(ascending=False) / (df.t.max() - df.t.min()))
# 単位時間あたりパケット数 (単位: tps)

この場合は、どうやら 10.100.45.26 と 10.100.45.39 の通信が頻発しているようなので、念のためメインのハブからカスケード接続する 10.100.45.26 と 10.100.45.39 だけを繋ぐハブを用意してもらって、問題が発生しなくなるかどうか推移を見ました。
もちろん、この程度のパケットの集計なら出来るツールは沢山あると思うのですが、Pandasの知識さえあれば特別なツールの使い方を覚えなくていいというのがとても大きいメリットでした。
TeraTermから取得したIoTデバイスのセンサデータの可視化
デバイスのセンサデータが大体どんな値を返してくるのか、肌感覚として持っておいてから本格的な実装に移りたいケースは多いと思います。
IoTデバイスに付いている3軸の地磁気センサの値がデバイスの回転とどのように紐付いていて、方位を取り出したい際にはどういうデータ処理をすればいいのか、短時間で調べる必要がありました。
幸い、地磁気センサのサンプルコードがあって、センサデータをシリアル経由でダンプしてくれるものだったので、TeraTermでテキストログを保存し、可視化してみることにしました

こんな感じのログデータなので、
def parse_mag_str(line):
try:
splitted = line[5:].replace(' ', '').split(',')
return [float(n) for n in splitted]
except:
return None
などという適当なパース関数を作ってみます。

挙動も大丈夫そうなので、
mags = [parse_mag_str(l) for l in log[2:]][0:-1]
としてfloat 3次元の配列にしておきます。
あとはipyvolumeのようなインタラクティブな3D可視化ライブラリにデータを入れてしまえば、マウス操作で簡単に3Dグラフとなったデータを
確認できます。
import ipyvolume as ipv
start = 250
end = 8000
t = np.array(range(start,end))
x = np.array([m[0] for m in mags[start:end]])
y = np.array([m[1] for m in mags[start:end]])
z = np.array([m[2] for m in mags[start:end]])
x_n = np.array([m[0] for m in mags[start+10:end+10]])
y_n = np.array([m[1] for m in mags[start+10:end+10]])
z_n = np.array([m[2] for m in mags[start+10:end+10]])
u = x_n - x
v = y_n - y
w = z_n - z
ipv.figure()
quiver = ipv.quiver(x, y, z, u, v, w, size=3, size_selected=20)
ipv.show()

この場合は、方位を取得するにはxy平面座標値をいい具合にatan2すればよいということが分かりました。データの時系列もコーンの向きでわかるため、符号もちゃんと合わせることができます。
ipyで始まるパッケージは、Jupyterの可視化性やインタラクティブ性を高めてくれるものが多く、役に立ちます。インタラクティブマップ上にデータを表示できるipyleaflet、ボタンなどを付けてUIを作ることが出来るipywidgetsなどがあります。
解析まとめ
ログを網羅的に確認したり、データ処理の出力結果を可視化・音声化等したりしなければわからないケースは、今まで処理ツールを書くのがとにかく面倒そうだなということで(本当に必要なときだけopenFrameworksを使って書いていました)、あまりしないでなんとなくの検証で誤魔化してきていたのですが、Jupyter Notebookの本領であるデータ解析・可視化の分野では殆どのことがスムーズに出来て、頭も神経も使わずに問題解決を一歩進めることができ、また、試行錯誤の結果が勝手にノートブックとして残るので、後から別のデータで再検証しなければならないときにかかる手間が非常に少ないため、ログを取ったり、メタデータを取り出して調査するのが好きになってしまいました。なんとなく雰囲気でコードを書いているだけで、今まで嫌々やっていた手作業での検証に対して、圧倒的な確度と量で上回る調査レポートを作ることができ、達成感があります。
電卓として使ってみたケース
UIデザインを実装していて、デザイン図面を元に、画面サイズに合わせて何回も同じ掛け算や足し算をした経験はありませんか。また、画像処理をしていて、ちょっとした行列計算(逆行列や対角化など)をしたくなること、回転行列を自分のお好みの回転順で作りたいこと、ちょっと複雑な逆行列を代数的に求めたくなることなどありませんか。
簡単な行列計算
数値計算
色覚異常者の色覚を再現する必要があり、RGB色空間をLMS色空間に変換(線形変換なのです)したのち、LMS色空間で行列演算をし、またRGB空間に戻したときに、
結果としてどのような線形変換をRGB色空間で行えばいいのかを求める必要がありました。式でいえば以下のようになります。
\begin{eqnarray}
\mathbf{c^{'}}_\mathrm{RGB} & = & \mathbf{M}_\mathrm{LMStoRGB} \cdot \mathbf{M}_\mathrm{protanopia} \cdot \mathbf{M}_\mathrm{RGBtoLMS} \cdot \mathbf{c}_\mathrm{RGB} \\
& = & ( \mathbf{M}^{-1}_\mathrm{RGBtoLMS} \cdot \mathbf{M}_\mathrm{protanopia} \cdot \mathbf{M}_\mathrm{RGBtoLMS}) \cdot \mathbf{c}_\mathrm{RGB}
\end{eqnarray}
右辺のカッコで括った行列部分だけ計算してやればいいので、ほぼそのままNumpyに入れて、以下のコードで完成です。
import numpy as np
rgb2lms = np.array([0.31399022, 0.63951294,
0.04649755, 0.15537241, 0.75789446, 0.08670142, 0.01775239,
0.10944209, 0.87256922]).reshape((3,3))
lms2rgb = np.linalg.inv(rgb2lms)

rgb2lms, lms2rgbがちゃんと出来ているか(NumpyはColumn Majorなのか、Row Majorなのか、その辺もわかっていなかったのでJupyter上で確認しながら進めました)確認しながら、
結果の行列は以下で計算出来ました。
protanopia = np.array([0.0, 1.05118294,-0.05116099, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0]).reshape((3,3))
lms2rgb.dot(protanopia).dot(rgb2lms)

代数的計算
3次元空間の回転行列は、ゲームを作っていたり、3DCGで座標を扱っていたり、スマートフォンのモーションセンサーを触っていたりすると良く使うことがあるかと思います。X,Y,Z軸をどういう順番で回転させるかによって、6パターンの回転行列があります。今まではWikipediaでいちいち調べて、選んだものが間違っていてうまくいかない、というような無駄を続けてきました。しかし、ベクトルがどのようにローカル座標系からグローバル座標系に変換されるのかをしっかり把握しながら左から一つずつ掛けていくのが実は一番確実で早く動きます。そんな訳で、回転行列も自分で計算してしまいます。ちょうどPythonには代数的な計算をしてくれるSympyというライブラリがあります。
from sympy import *
# x軸方向の回転
theta = Symbol('theta')
Rx = Matrix([[1, 0, 0], [0, cos(theta), -sin(theta)], [0, sin(theta), cos(theta)]])
# y軸方向の回転
yaw = Symbol('yaw')
Ry = Matrix([[cos(yaw), 0, sin(yaw)], [0, 1, 0], [-sin(yaw), 0, cos(yaw)]])
# z軸方向の回転
phi = Symbol('phi')
Rz = Matrix([[cos(phi), -sin(phi), 0], [sin(phi), cos(phi), 0], [0, 0, 1]])
R = Ry * Rx * Rz
R

結果もTeXでレンダリングされた綺麗な形で出てくるので確認がしやすいですし、自分で回転行列を構築しているので、何かおかしくても順番を変えたり回転行列を一つ減らしてみたりということが簡単にできます。
ややこしい逆行列の計算
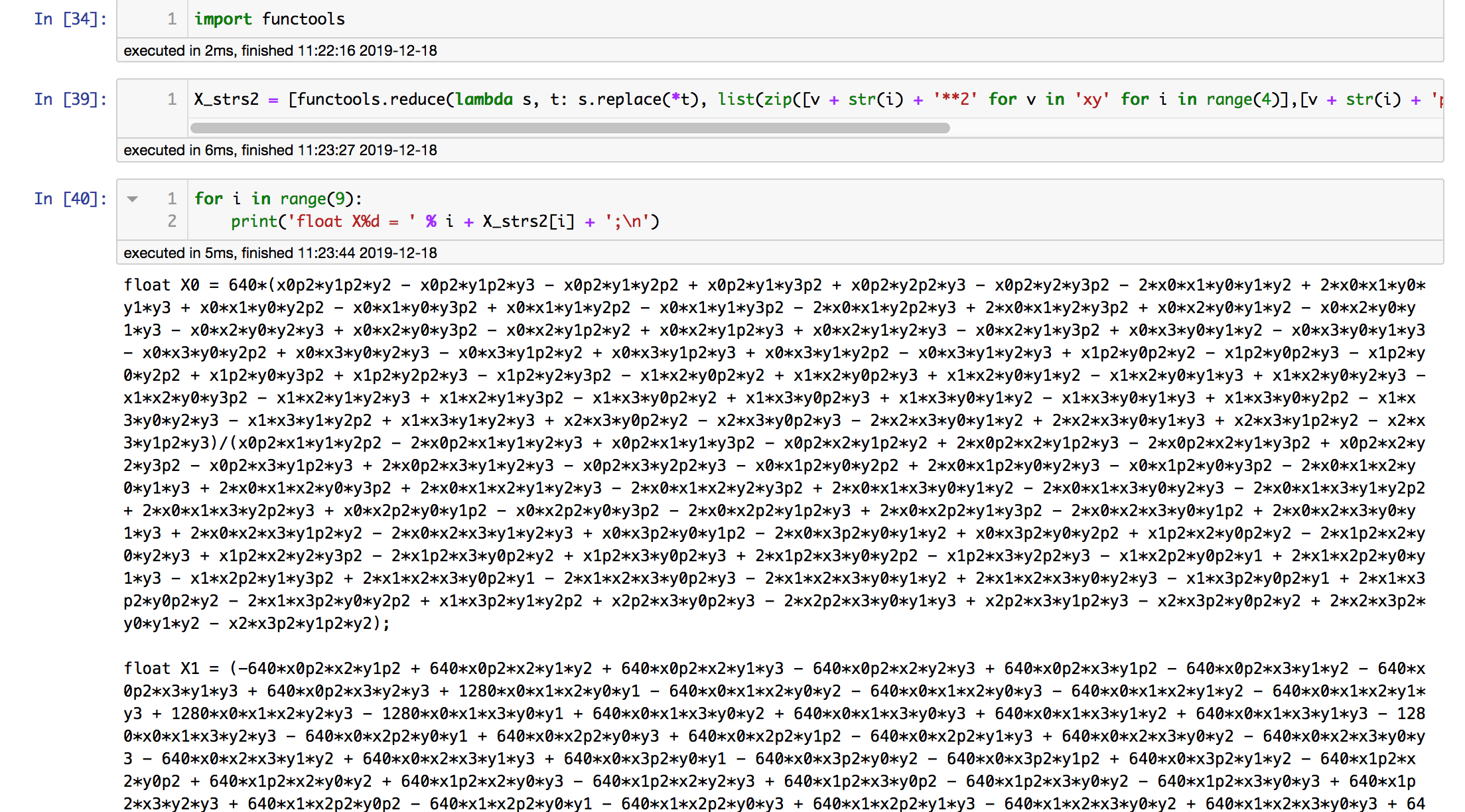
IoTデバイス上で、何のライブラリもない状態から画像を射影変換して表示できないか、という依頼を受けました。導出過程は本題ではないので省略します(ちょっと形式が違いますが本質的にはホモグラフィ - Shogo Computing Laboratoryと同じ計算をしているはずです)が、結果としては、以下の9行9列の行列の逆行列を解いてベクトルを掛けると3行3列の射影変換行列の各要素を9次元ベクトルにしたもの X が求まります。
from sympy import *
# x0 = Symbol('x0') というような代入をx0 - x3, y0 - y3に対して行う
for i in range(4):
for c in "xy":
globals().update({c + str(i): Symbol(c + str(i))})
u0 = 640
v0 = 0
u1 = 640
v1 = 480
u2 = 0
v2 = 480
u3 = 0
v3 = 0
A = Matrix([
[ x0, y0, 1, 0, 0, 0, -x0*u0, -y0*u0, 0 ],
[ 0, 0, 0, x0, y0, 1, -x0*v0, -y0*v0, 0 ],
[ x1, y1, 1, 0, 0, 0, -x1*u1, -y1*u1, 0 ],
[ 0, 0, 0, x1, y1, 1, -x1*v1, -y1*v1, 0 ],
[ x2, y2, 1, 0, 0, 0, -x2*u2, -y2*u2, 0 ],
[ 0, 0, 0, x2, y2, 1, -x2*v2, -y2*v2, 0 ],
[ x3, y3, 1, 0, 0, 0, -x3*u3, -y3*u3, 0 ],
[ 0, 0, 0, x3, y3, 1, -x3*v3, -y3*v3, 0 ],
[ 0, 0, 0, 0, 0, 0, 0, 0, 1 ],
])
A

B = Matrix([u0, v0, u1, v1, u2, v2, u3, v3, 1])
B

X = A.inv() * B

5秒程度で計算できたようです。
ただし、このXの各要素は項数がかなり多いらしく表示させようとするとTeXのコンパイルにものすごく時間がかかってしまうようなので、文字列として取り出してみます。
X_strs = [str(simplify(X[i])) for i in range(9)]

simplifyに時間がかかっているのか、2分近く時間がかかりました。
このままCのコードに変換してしまいたいので、x0**2という冪乗の項をx0p2などにリネームしてしまいます。
list(zip([v + str(i) + '**2' for v in 'xy' for i in range(4)],[v + str(i) + 'p2' for v in 'xy' for i in range(4)]))

こんな対応のリネームでいけそうなので、一気にreduceを使って置換します。
X_strs2 = [functools.reduce(lambda s, t: s.replace(*t), list(zip([v + str(j) + '**2' for v in 'xy' for j in range(4)],[v + str(j) + 'p2' for v in 'xy' for j in range(4)])), X_strs[i]) for i in range(9)]
最終的にこれをCのコードに変換するのは、以下のようなコードで行います。
for v in 'xy':
for i in range(4):
print('float %s%dp2 = %s%d * %s%d;\n' % (v, i, v, i, v, i))
for i in range(9):
print('float X%d = ' % i + X_strs2[i] + ';\n')

これで任意のパラメータでの射影変換機能が何のライブラリにも依存しない形で組込みデバイス向けに出来ました。どこか一箇所変換漏れがあったのですが、そこを修正したところ理屈通りに動きました。
似たような感じでこの射影変換行列の逆行列も求めました。

数式をほぼそのまま書いていけば完成してしまうので楽ちんですね。
単純な電卓
違う画面サイズでデザインされたUI要素のサイズを計算するのに使ったりもします。本当に大したことはしていないですが、見やすく、修正しやすいところが嬉しいです。

バイナリデータを作ってパケットを出すのに使ってみたケース
UDPパケットを出してデバイス制御の実験
サイネージの制御システムを作っていて、ある電源制御装置がUDPのバイナリパケットで動作するはずということで、仕様書通りにパケットを作ってUDPで送るというところまで試してみました。
まずパケットを作ります。
switches = [True, False, True, True, False]
model_id = 3 # LA-5R
unit_id = 0b00001111 ^ 0
def make_send_bytes(model_id, unit_id, switches):
return bytes([0xf0 | unit_id, switches[4] << 4 | switches[3] << 3 | switches[2] << 2 | switches[1] << 1 | switches[0]])
send_bytes = make_send_bytes(model_id, unit_id, switches)
[format(send_bytes[i], '02x') for i in [0, 1]]

パケットは作れているようなので、実際に送ってみます。
switches = [random.random() < 0.5 for i in range(0, 5)]
send_bytes = make_send_bytes(model_id, unit_id, switches)
[format(send_bytes[i], '02x') for i in [0, 1]]
s.sendto(send_bytes, (HOST, PORT))
スクリーンショットなどは用意できないのですが、パケットを送ると動くのが確認できました。
次に5ch全パターン、32パターンのスイッチON/OFFの制御が出来ているか確認します。
sl = 0.08
l = 0.08 / sl
for j in range(0, int(l)):
for i in range(0, 32):
switches = [c == '1' for c in format(i, '05b')]
send_bytes = make_send_bytes(model_id, unit_id, switches)
[format(send_bytes[i], '02x') for i in [0, 1]]
s.sendto(send_bytes, (HOST, PORT))
time.sleep(sl)

書いている結果だけ見るとほとんどCで書いているのと同じなのですが、ビット演算に慣れてない状態で、パケットが正しく作れているかそうでないか、実際に送って試して動くかの試行錯誤のループが速いのは実装効率にとても響くということがわかりました。
また、同時にTCP接続での制御も検証したのですが、ノートブックに目次をつけると、謎のコメントアウトだらけのような状態にならないので、TCPとUDPの間で流用できる部分、できない部分を整理でき、後で見返してコードを活用しやすい状態を作れます。
フォーマット変換をしてみたケース
これが最も典型的なケースかも知れません。ソフトウェアエンジニアをしていると、素菜データを貰って最終形にするために、簡単なスクリプトを書いて各種フォーマット変換を解決したくなるケースって多々ありますよね。そういうときも、Jupyter Notebookの「見ながら試行錯誤できる」という点が強くて、非常に役立ちます。
AfterEffectsから書き出したJSONを変換して、UnityのImmediateで実行可能な、オブジェクト作成コードを作る
ゲーム開発中に、AfterEffectsで3Dレイヤー機能を使って配置された画像をUnityに移植したいということがありました。もちろん、一レイヤーずつ数値を見ながらUnityのQuadオブジェクトを作っていけば実現できるのですが、50レイヤーぐらいあるのにそんな単純作業はやりたくない。ということで、まず、AfterEffectsのレイヤーの各情報をESTKを使ってJSONで書き出して、その後、Jupyter Notebookで処理しました。
まず、どんな値が入っているか確認して、
import json
import codecs
from operator import itemgetter
with codecs.open('transforms.json', 'r', encoding='shift-jis') as f:
root = json.load(f)
root

一つのレイヤーを取り出して、
layer = root['9']
layer
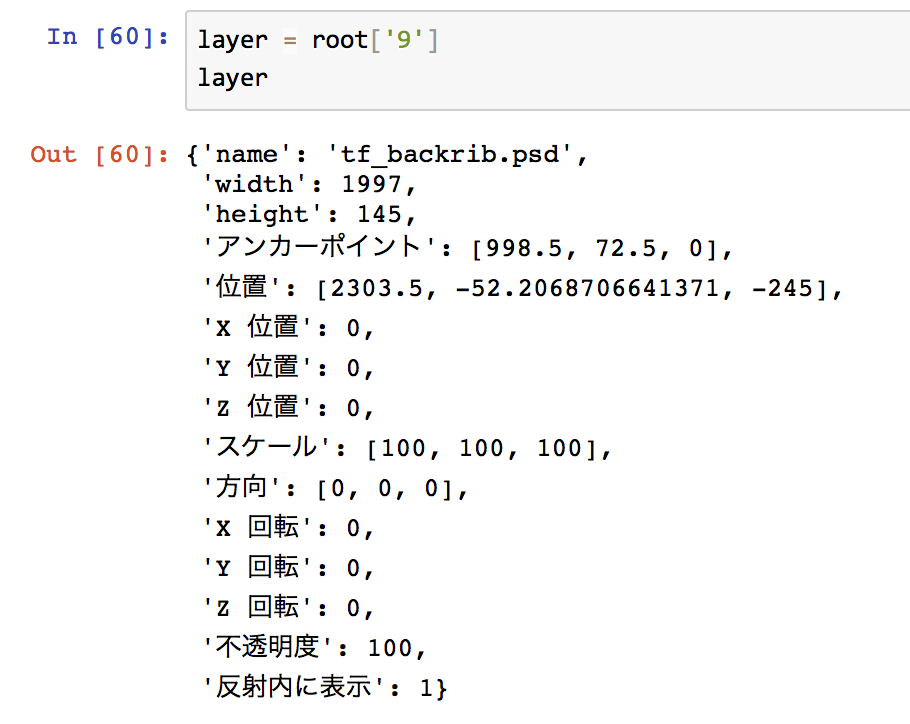
位置、アンカーポイント、幅、高さ、スケールなどをX, Yの各項目についてまとめてやり、
list(zip(layer['位置'],layer['アンカーポイント'],[layer['width'], layer['height']], [layer['スケール'][0], layer['スケール'][1]]))

アンカーポイント基準になっている位置指定や拡大縮小を中心基準にしてやります。
[ps[0] - ps[1] * ps[3] + ps[2] * ps[3] / 2 for ps in zip(
layer['位置'],
layer['アンカーポイント'],
[layer['width'], layer['height'], 0],
[layer['スケール'][0] / 100, layer['スケール'][1] / 100, 1])]

これで1レイヤーについての処理法がわかったので、全レイヤーに適用してみます。reverseしているのはAfterEffectsとUnityで重なり順が逆のためです。
t_list = [([ps[0] - ps[1] * ps[3] + ps[2] * ps[3] / 2 for ps in zip(layer['位置'],layer['アンカーポイント'],[layer['width'], layer['height'], 0], [layer['スケール'][0], layer['スケール'][1], 1])],
[layer['width'] * layer['スケール'][0] / 100, layer['height'] * layer['スケール'][1] / 100], layer['name']) for layer in root.values()]
t_list.reverse()
t_list

これで全レイヤーについて、座標、幅、高さがわかったので、Unity EditorのImmediateペインに打ち込んでシーン上にオブジェクトを作るためのC#のコードを生成してしまいます。
cs_str = '''{GameObject q = GameObject.CreatePrimitive(PrimitiveType.Quad);
q.name = "%s";
q.transform.position = new Vector3(%ff, %ff, %ff);
q.transform.localScale = new Vector3(%ff, %ff, 1.0f);
var m = (q.GetComponent<Renderer>().material = UnityEditor.AssetDatabase.LoadAssetAtPath<Material>("Assets/Textures/Background/_Materials/%s.mat"));
if (m != null) m.renderQueue = %d;
}'''
sss = '\n'.join([cs_str % (t[2].replace('.psd', ''),
t[0][0] / 1000, -t[0][1] / 1000, t[0][2] / 1000,
t[1][0] / 1000, t[1][1] / 1000, t[2].replace('.psd', ''),
3000 + i + start) for i, t in
enumerate(sorted(t_list, key=lambda t: int(t[0][2]), reverse=True)[start:start + lll])])
print(sss)

実際に、Immediateペインにコードを打ち込むとAfterEffectsのシーンが再現されました。50回入力するのと同じぐらい時間がかかったような気もしますが、デザイナーさんがAfterEffectsのシーンを弄っても機械的に対応できるので、2回目からは大分楽な気がします。残念ながらデザイナーさんは「こんな複雑で操作しにくいAEファイルはもう弄りたくない」と言っていましたが。
HTMLパーツの生成
たまにHTMLのコーディングもするのですが、ブログの記事一覧のような、ほとんど繰り返しでタイトル文字列などが何度も出てくるようなところを手書きしなければいけなくなったりします。CMSを入れろ、静的Webサイトジェネレータでも使えという話があるのですが、大抵それよりも公開を優先しなければならないことが多く、繰り返し部分が全体のわずかだったりすると、やっぱりBracketsなどのHTMLエディタで直接書いた方が速いような気がしています(HTML/CSSの経験値が少ないのも大きな原因ですが)。そんなときでも、同じ文字列を複数箇所に気をつけてコピーするのは退屈だし面倒だし神経使うからサボりたいと思うのがプログラマーの心情。ということで、一回Bracketsで書いてみてうまく表示されたら、テンプレートを作って置換してしまいます。
news_template=''' <article class="news-box">
<div class="news-photo-box"><img src="assets/image/news/###image_name###"></div>
<div class="news-date">###date_str###</div>
<div class="news-title">###title_str###</div>
<button class="news-more" alt="MORE"></button>
<div class="news-description news-description-hidden">
<button class="close-button"></button>
<button class="news-prev-button"></button>
<button class="news-next-button"></button>
<div class="news-description-inner">
<div class="news-description-pdt-box">
<div class="news-description-photo-box"><img src="assets/image/news/###image_name###"></div>
<div class="news-description-dt-box">
<div class="news-description-date">###date_str###</div>
<div class="news-description-title">###title_str###</div>
</div>
</div>
<div class="news-description-body">
###body_str###
</div>
</div>
</div>
</article>
'''
def make_news(date_str, title_str, body_str, image_name='default.png'):
return news_template \
.replace('###date_str###', date_str) \
.replace('###title_str###', title_str) \
.replace('###body_str###', body_str) \
.replace('###image_name###', image_name)

これで、必要な項目を入れるだけでHTMLが間違いなく作れるようになりました。学習コスト0で出来るということはとても素晴らしいです。また、今後ニュースの追加を依頼されたときに、このノートブックを開くことで全て思い出せるだろうというのも、明確にドキュメント化していない割には未来に負債を残さないという意味で良い点かなと思います。
その他
それ以外にも、
- お客さんが用意したCSVフォーマットのメタデータをWebクライアント用のJSONフォーマットにpandasとjsonで一瞬で変換
- DVDに収まりきらない納品用写真データディレクトリを、任意のスパンで切って合計ファイルサイズを見ながら適度にDVD用に分ける
- GPSデータを読み込んでKMLに変換
- CSVデータを読み込んで地図画像に出力
- 不具合メールの項目を作業用Excelファイルに変換してコメントなどつけやすく
- PGMからBMPに変換 (BMPのバージョンが色々あって適切なImageMagickのオプションを調査しきれなかったため、ヘッダーだけ他のBMPから移植してデータはPGMからガッチャンコ)
- Unity用のアニメーション連番タイル画像を作る際、テクスチャ容量節約のために、連番画像でかぶっているものはmd5ハッシュで確認して排除する
- ビッグデータをHoudiniで読み込みやすいようにCSVファイルを結合
- 6タイプの動画に同一の音源を3種の音声コーデックで結合し、計18個の動画ファイルを何度も作り直す
などなど、読み込んで変換するというものはコマンド一発で済むものではないかぎりほとんどJupyter Notebookでやってしまっています。
伝統的なコマンドラインツールを使えばできることも多いと思いますが、ツールの使い方を調べたり、ツール間のデータの受け渡しを考えたりするのがめんどくさくて、また、記録がほぼ確実に残ってやり直しになっても困らないので、シェルの代わりにJupyter Notebookを使う日々が続いています。
みなさんも騙されたと思ってJupyter Notebookを使ってみてください。プロジェクト単位で非定形な仕事が多い人はとても向いていると思います。