概要
- AWS Lambdaでリンクチェッカーを作った
- urlのリンクリストのcsvファイルをインプットにしてリンクチェック結果をDynamoDBに出力します
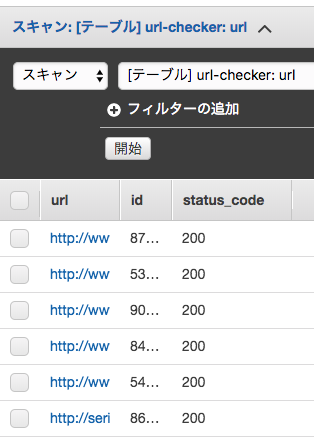
ざっくりとした技術説明
- rubyでS3にidとurlキーを持つjsonを出力
- S3へのput出力をトリガーとしてlambda関数を実行してリンク切れを有無をstats_codeとして取得
- 取得した結果をDnamoDBへ出力
手順
S3のバケットを作成する
バケットを作成する。ここでは__url-checker__という名前で作りました。以下のスクリプトでは、バケット名はurl_checkerを前提にしていますので、適宜書き換えてください。
- url-checkerバケットを作成
- __url__というフォルダを作成
DynamoDBを作成する
__url-checker__という名前でDynamoDBを作る。プライマリキーは__url__です。

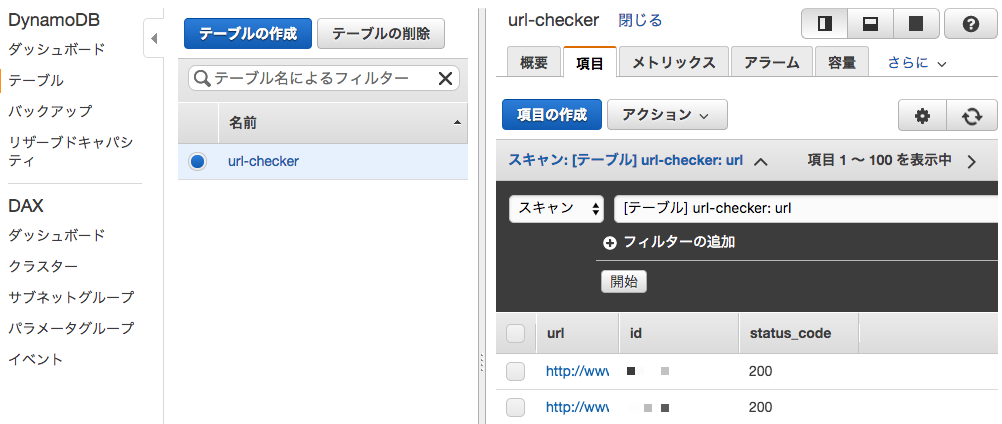
書き込みはデフォルトの5です。エラーが起きるようでしたら書き込み数値を適当に上げてください。(料金に注意!!!!!)
Lambdaファンクションを作成する
- Lambdaファンクションを作成する。ファンクション名はなんでもいいです。
- S3ファイル(jsonファイル)からidとurlを読み込んで、リンクをチェックし、DyanmoDBへ保存しています。
- トリガーはS3のurl-checkerバケットのurlフォルダのputを指定してください。
- DynamoDBへのアクセスを許可してください。
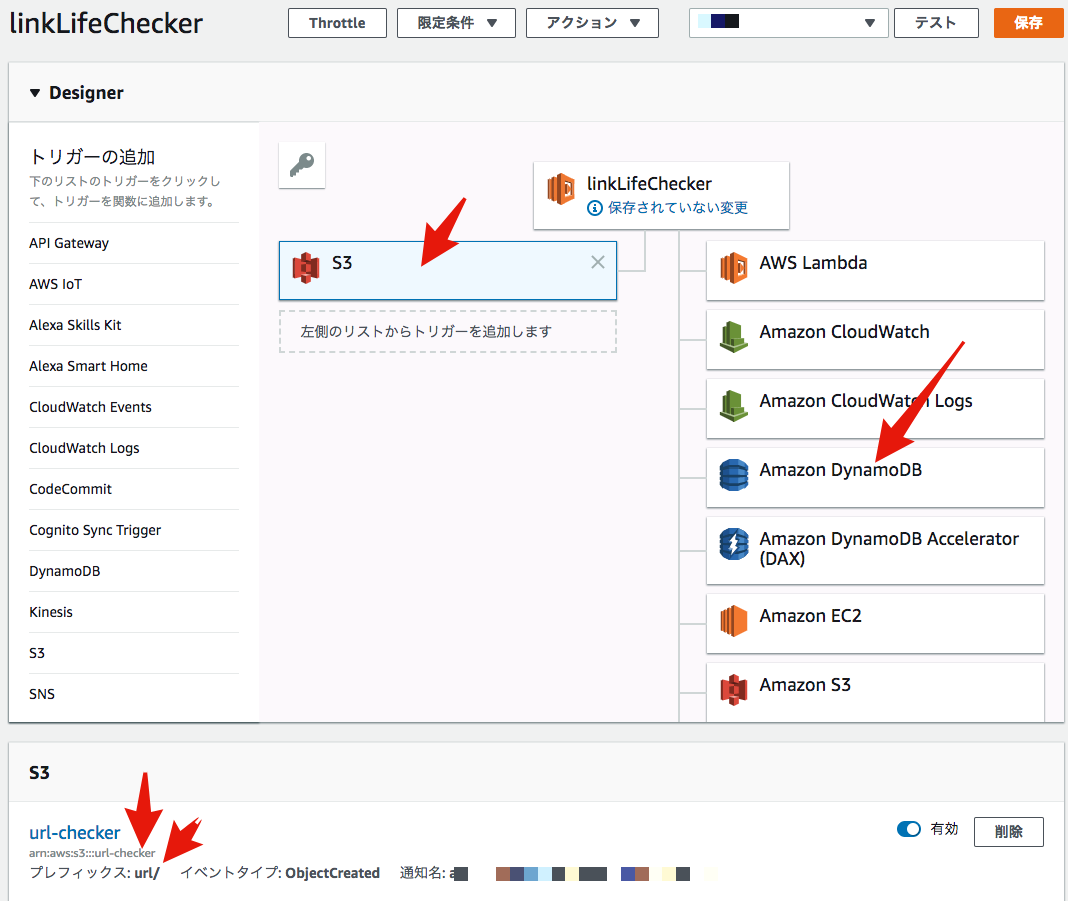
タイムアウトしないように。lambdaのタイムアウトは5分に伸ばした。
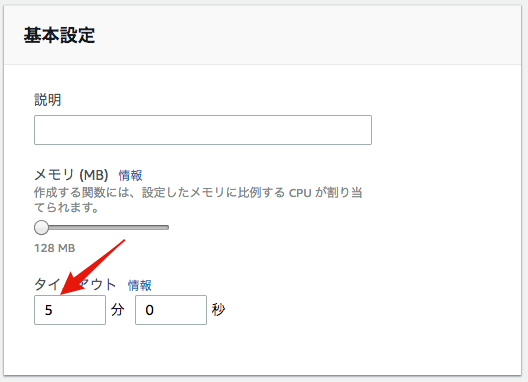
- 関数は以下の通りです。
lambda_function.py
import urllib.request
import json
import boto3
import random
from time import sleep
error_code = 0 # エラーの場合は0を返す
dynamodb_table = 'url-checker' # 事前に作成したdynamodbのテーブル名
max_wait_sec = 120
def lambda_handler(event, context):
wait_sec = random.randint(1, max_wait_sec)
sleep(wait_sec) # 同一URLへの同時アクセスする可能性を減らすため念のためアクセス時間をずらす
site = get_s3_json(event)
site["status_code"] = get_status_code(site['url']) # status codeをチェックして結果をjsonで返す
print(site)
put_dynamo_table(site) # 結果をdynamoDBへ保存する
return site
def put_dynamo_table(item):
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(dynamodb_table)
table.put_item(Item=item)
def get_s3_object(event):
s3 = boto3.client('s3')
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
return s3.get_object(Bucket=bucket, Key=key)['Body'].read()
def get_s3_json(event):
s3_object = get_s3_object(event)
return json.loads(s3_object)
def get_urllib_response(url):
req = urllib.request.Request(url)
return urllib.request.urlopen(req)
def get_status_code(url):
status_code = 0
try:
with get_urllib_response(url) as res:
print(res.status)
status_code = res.status
except urllib.error.HTTPError as err:
print(err.code)
status_code = err.code
except urllib.error.URLError as err:
print (err.reason)
status_code = error_code
return status_code
S3にトリガー(jsonファイル)をアップロードする
今回作成したlambda関数は、S3へのputをトリガーにしています。
トリガーを発火させるため、インプットCSVファイルからidとurlを読み込んで、jsonファイルとしてS3へ書き出すためのスクリプトをrubyで作成しました。
なお、AWSのアクセスキーとAWSのシークレットアクセスキーは各自のモノを書き込んで使ってください。
aws-sdk-s3は事前にインストールしておいてください。
status code取得のためのメソッド箇所はPython の HTTP クライアントは urllib.request で十分を使いました。
execute_que.rb
require 'aws-sdk-s3'
require 'csv'
INPUT_PATH = ARGV[0] || 'test2.csv'
BUCKET = 'url-checker'
FOLDER = 'url'
AWS_ACCESS_KEY_ID = 'アクセスキー'
AWS_SECRET_ACCESS_KEY = 'シークレットアクセスキー'
def start(path: '', limit_url_duplication: true, limit_num: nil)
s3_client = create_s3_client
lists = get_lists(path)
if limit_url_duplication && uniq_url?(lists)
p 'URL is duplicated. Use uniq URLs in csv.'
exit
end
lists.each_with_index do |row, index|
filename = "#{row[:id]}.json"
key = "#{FOLDER}/#{filename}"
body = {id: row[:id].to_i, url: row[:url]}
s3_client.put_object(
bucket: BUCKET,
key: key,
body: body.to_json
)
break if index == limit_num
end
end
def create_s3_client
return Aws::S3::Client.new(access_key_id: AWS_ACCESS_KEY_ID, secret_access_key: AWS_SECRET_ACCESS_KEY)
end
def get_lists(path)
lists = []
CSV.foreach(path, headers: true) do |row|
headers = row.headers
lists << headers.each_with_object({}) do |c, h|
h[c.to_sym] = row.field(c)
end
end
return lists
end
def uniq_url?(lists)
urls = lists.map {|list| list[:url]}
!(lists.count == urls.uniq.count)
end
# csv作成ミスによる、同一URLへの複数回アクセスを防止するためlimit_url_duplicationの初期値はtrueです。
start(path: INPUT_PATH, limit_url_duplication: true)
リンクチェックを実行する!
- インプットファイルを下記のように用意します。同一URLヘの同時アクセスを避けるため、urlは必ず固有にしてください。
input.csv
id,url
1,https://www.AAAA.co.jp
2,https://www.BBBB.co.jp
- 下記のコマンドを実行します。
> ruby execute_que.rb input.csv
S3のurl-checker/urlフォルダ内にjsonファイルが作成されます。
DynamoDBのurl-checkerテーブルにチェック結果が格納されます。
以上です!
所感
Lambdaすごい便利。楽しい。1000台動いている姿をみると全能感に浸れる。