1.はじめに
text-to-speech (TTS)という文章から自然な音声を生成する分野があります。この分野には、以前から、2つの方法がありましたが、それぞれ問題点を抱えていました。
1つは、**「波形接続」**という1人の話者による短い音節のセットから必要なものを結合して合成する方法ですが、この方法は、声を変えたり、抑揚や感情を加えることが難しいという問題がありました。
もう1つは、**「パラメトリック」**という話す内容や特徴(声、抑揚など)を入力によって操作できる方法ですが、これは音声品質に問題がありました。
WaveNetは、これらを解決する方法で、音楽にも応用ができるものです。
2.Dilated Convolution
音声信号は、通常サンプリング周波数が16kHzで、1秒間に16,000サンプルもの時系列データがあるため、自己回帰モデルで扱うのは極めて難しいです。そこで、WaveNetはdilated convolutionという仕組みを使って受容野が広くなるようにCNNを構築し、この問題を解決しています。

Dilated convolution は層が深くなるにつれて畳み込むノードを指数関数的に離すことによって受容野(時系列過去データをどの程度参考にするか)を広げた状態で畳み込みをする演算です。また、オンラインでの使用を考慮して、未来のデータを畳み込まないように時系列をシフトさせています。
3.アーキテクチャ
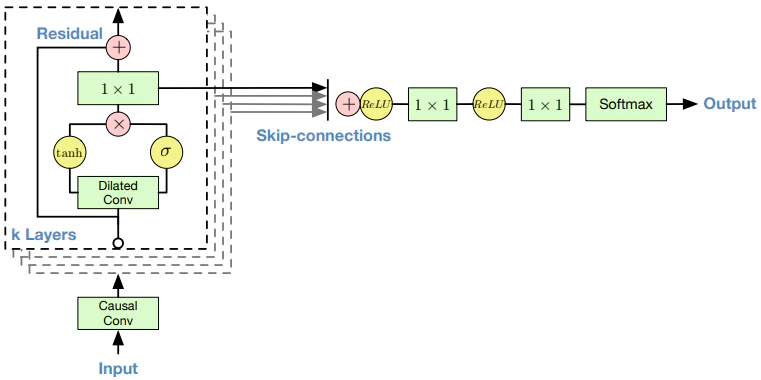
これがWaveNetのアーキテクチャです。残差ブロックとスキップコネクションを採用しています。
活性化関数は、**GTU(gated tanh unit)**を採用しています。GTUは音声信号に対しては、よく使われるReLUよりも良く機能するとされています。
通常の音声信号は16bitの整数値(0-65535)で保存されていますが、WaveNetでは計算負荷を減らすためsoftmaxで256クラスのカテゴリ変数に変換し、生成する音声がどのクラスに属するかという分類問題として生成音声の予測を行っています。
WaveNetの確率分布は、過去の時系列データに加えて、付加情報hも条件として持っています。hにはテキスト(内容)や話者の情報(声)を含めることができ、これによってWaveNetは”付加情報 : h” の情報を指定した”出力波形 : x”の確率分布を計算することができます。
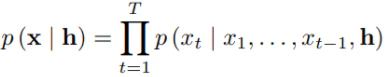
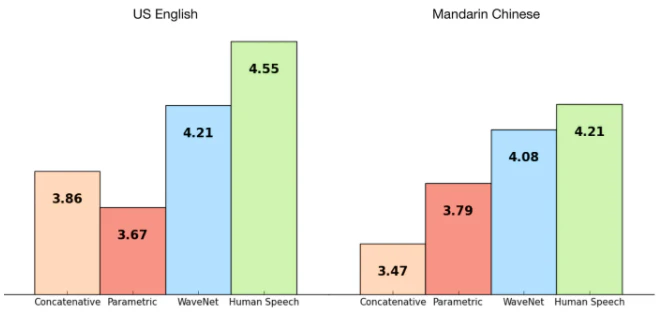
4.評価
TTSには、MOS(Mean Opinion Scores)という, 人間の話し方とのギャップを計測する客観的な評価方法があり、その評価結果は、従来の方法に比べて人の話し方とのギャップを50%以上縮めることに成功しています。