1.はじめに
CelebAデータセットの向こうを張って、オリジナル顔画像データセットを作ることにチャレンジしたことはありますか?
私はやったことはありますが、大規模なデータセットを作ろうとすると、めげました(笑)。
Web画像検索で画像を収集して、OpenCVで顔画像を切り出すところまでは自動化出来るので、問題ありません。
しかし、OpenCVの性能はあまり良くないためか、後で、アトランダムに混じっているゴミの様な画像や違う人の顔画像を手動で抜き出さなければならない。これが大変。
1,000枚や2,000枚くらいなら勢いでやれますが、10,000枚や20,000枚となって来ると、集中力がとても続きません(私、飽きっぽいので)。
今回は、この問題を解決したいと思います。
2.今までの方法
Qiitaにも良く載っている方法を元に、作業を自動化する形で、コードを作成してみます。
あらかじめ、タレント名を指定して置くと、順番に、画像をダウンロードし、顔画像を切り出して保存し、明らかなゴミ(2KB未満の画像)は削除するコードです。
カレントディレクトリに、haarcascades フォルダーを作成し、その中に、haarcascade_frontalface_alt.xml を入れておいて下さい。
実行してみます。
import json
import os
import urllib
import requests
import cv2
import glob
from bs4 import BeautifulSoup
from tqdm import trange, tqdm
# フォルダーの作成
def make_dir(save_dir, name):
os.makedirs(save_dir, exist_ok=True)
os.makedirs(save_dir + name, exist_ok=True)
# 検索用のクエリーを取得
def query_gen(keyword):
page = 0
while True:
params = urllib.parse.urlencode({'q': keyword,'tbm': 'isch','ijn': str(page)})
yield 'https://www.google.co.jp/search' + '?' + params
page += 1
# 画像取得
def get_img(query_gen, maximum, data_dir):
session = requests.session()
session.headers.update(
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0'})
result = []
total = 0
while True:
html = session.get(next(query_gen)).text #
soup = BeautifulSoup(html, 'lxml')
elements = soup.select('.rg_meta.notranslate')
jsons = [json.loads(e.get_text()) for e in elements]
imageURLs = [js['ou'] for js in jsons]
if not len(imageURLs):
break
elif len(imageURLs) > maximum - total:
result += imageURLs[:maximum - total]
break
else:
result += imageURLs
total += len(imageURLs)
for i in trange(len(result), desc='get_img '+name):
try:
urllib.request.urlretrieve(
result[i], data_dir + name + '/' + str(i + 1).zfill(4) + '.jpg')
except:
continue
# 顔画像の切り出し
def pic_face(in_dir, out_dir, name):
pic = os.listdir(in_dir + name + '/')
for i in trange(len(pic), desc= '+ pic_face '+name):
image_gs = cv2.imread(in_dir + name + '/' + pic[i])
cascade = cv2.CascadeClassifier("./haarcascades/haarcascade_frontalface_alt.xml")
face_list = cascade.detectMultiScale(image_gs,scaleFactor=1.1,minNeighbors=1,minSize=(1,1))
no = 1
for rect in face_list:
x, y = rect[0], rect[1]
width, height = rect[2], rect[3]
dst = image_gs[y:y + height, x:x + width]
save_path = out_dir + name + '/' + '/' +'out_(' + str(i) +')' + str(no) + '.jpg'
cv2.imwrite(save_path, dst)
no +=1
# 顔画像のスクリーニング
def screening_face(size):
file_list = glob.glob('./out/' +name+ '/*.jpg')
for file in tqdm(file_list, desc='+ screening '+ name):
f_size = os.path.getsize(file)
if f_size < size:
os.remove(file)
def main():
# 画像取得
make_dir('./data/', name)
query = query_gen(name)
get_img(query, maximum, './data/')
# 顔画像の切り出し
make_dir('./out/', name)
pic_face('./data/', './out/', name)
# 顔画像のスクリーニング
screening_face(2000) # ()内に記載されたbyte未満の顔画像は削除
if __name__ == '__main__':
target = ['新垣結衣', '綾瀬はるか', '石原さとみ', '柏木由紀']
maximum = 500 # 最大ダウンロード枚数
for i in range(len(target)):
name = target[i]
main()

リスト target に、タレントを100名設定して寝る時に開始しておけば、朝起きた時には 'out/タレント名フォルダー' に100人分の顔画像が保存されています。
但し、その顔画像は、こんな感じ。。。
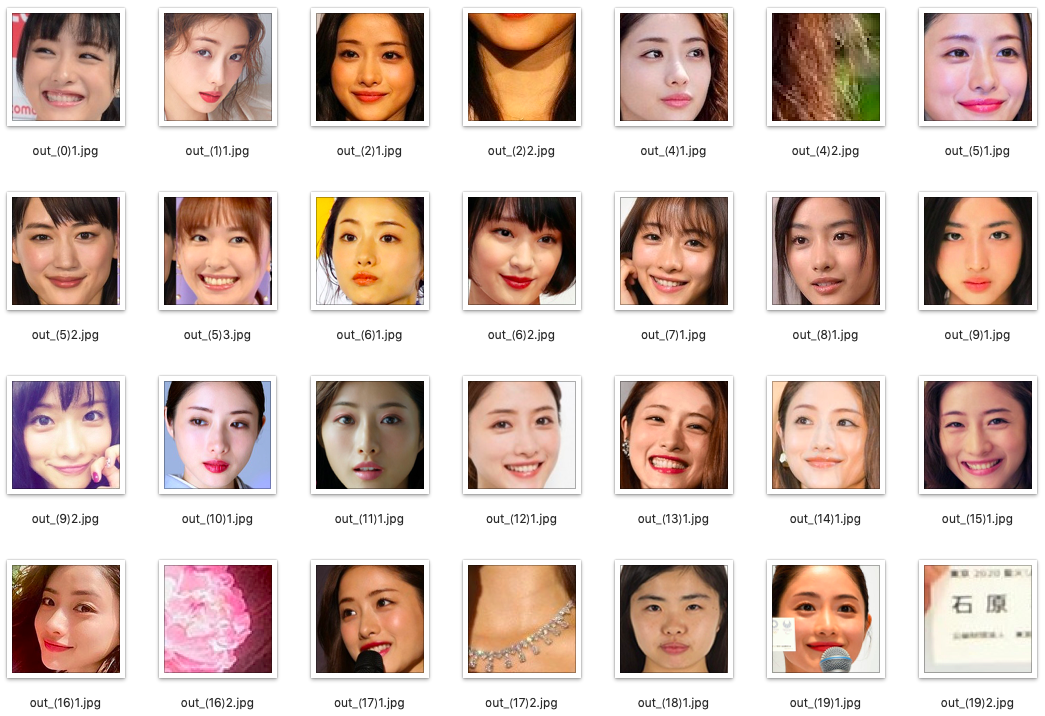
アトランダムにゴミや他の人の顔が混じっている。これを100人分削除しようとすると、もうゲンナリしてしまうわけです。
3.画像ベクトルのCOS類似度
Githubを見ていたら、Image-netを学習したCNNを使って2つの画像をベクトル化し、COS類似度を計算することで、2つの画像の類似度が計算出来ることを知りました。


今回、取得した画像の多くは、狙いとするタレントの顔画像で、そこに少量のゴミ画像が混じっている。
ある画像を対象に、その他全ての画像との類似度を1つ1つ計算し合計すれば、その画像の重要度がスコア化出来るのではないか。
狙いとする顔画像はスコアが高くなるはずだし、少量のゴミはスコアが低くなるはず。
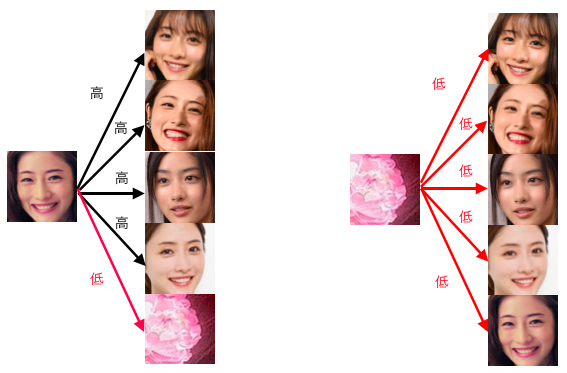
また、他の人の顔画像は相対的にスコアがやや低いことが期待出来るかもしれない。
ということで、先程のコードに機能追加を行うことにします。
4.コードの改良
まず、学習済みモデル 'resnet-18' を使って、画像をベクトル化するモジュールを作成します。
動作環境として、Pytorchのフレームワークが必要なので、別途インストールして下さい。
img_to_vec.py として、カレントディレクトリーに保存しておきます。
import torch
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
class Img2Vec():
def __init__(self, cuda=False, model='resnet-18', layer='default', layer_output_size=512):
""" Img2Vec
:param cuda: If set to True, will run forward pass on GPU
:param model: String name of requested model
:param layer: String or Int depending on model. See more docs: https://github.com/christiansafka/img2vec.git
:param layer_output_size: Int depicting the output size of the requested layer
"""
self.device = torch.device("cuda" if cuda else "cpu")
self.layer_output_size = layer_output_size
self.model_name = model
self.model, self.extraction_layer = self._get_model_and_layer(model, layer)
self.model = self.model.to(self.device)
self.model.eval()
self.scaler = transforms.Resize((224, 224)) # Scale > Resize
self.normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
self.to_tensor = transforms.ToTensor()
def get_vec(self, img, tensor=False):
""" Get vector embedding from PIL image
:param img: PIL Image
:param tensor: If True, get_vec will return a FloatTensor instead of Numpy array
:returns: Numpy ndarray
"""
image = self.normalize(self.to_tensor(self.scaler(img))).unsqueeze(0).to(self.device)
if self.model_name == 'alexnet':
my_embedding = torch.zeros(1, self.layer_output_size)
else:
my_embedding = torch.zeros(1, self.layer_output_size, 1, 1)
def copy_data(m, i, o):
my_embedding.copy_(o.data)
h = self.extraction_layer.register_forward_hook(copy_data)
h_x = self.model(image)
h.remove()
if tensor:
return my_embedding
else:
if self.model_name == 'alexnet':
return my_embedding.numpy()[0, :]
else:
return my_embedding.numpy()[0, :, 0, 0]
def _get_model_and_layer(self, model_name, layer):
""" Internal method for getting layer from model
:param model_name: model name such as 'resnet-18'
:param layer: layer as a string for resnet-18 or int for alexnet
:returns: pytorch model, selected layer
"""
if model_name == 'resnet-18':
model = models.resnet18(pretrained=True)
if layer == 'default':
layer = model._modules.get('avgpool')
self.layer_output_size = 512
else:
layer = model._modules.get(layer)
return model, layer
elif model_name == 'alexnet':
model = models.alexnet(pretrained=True)
if layer == 'default':
layer = model.classifier[-2]
self.layer_output_size = 4096
else:
layer = model.classifier[-layer]
return model, layer
else:
raise KeyError('Model %s was not found' % model_name)
そして、先程のコードに、顔画像をベクトル化し、スコアリングを行い、スコアの高い順に画像を並べるコードを追加します。
冒頭にある、from img_to_vec import Img2Vec で、画像をベクトル化するモジュールをインポートしています。
では、このコードを実行してみます。
import json
import os
import urllib
import requests
import cv2
import glob
from bs4 import BeautifulSoup
from tqdm import trange, tqdm
from PIL import Image
from sklearn.metrics.pairwise import cosine_similarity # cos類似度計算ライブラリー
from img_to_vec import Img2Vec # img_to_vec.py 読み込み
# フォルダーの作成
def make_dir(save_dir, name):
os.makedirs(save_dir, exist_ok=True)
os.makedirs(save_dir + name, exist_ok=True)
# 検索用のクエリーを取得
def query_gen(keyword):
page = 0
while True:
params = urllib.parse.urlencode({'q': keyword,'tbm': 'isch','ijn': str(page)})
yield 'https://www.google.co.jp/search' + '?' + params
page += 1
# 画像取得
def get_img(query_gen, maximum, data_dir):
session = requests.session()
session.headers.update(
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:10.0) Gecko/20100101 Firefox/10.0'})
result = []
total = 0
while True:
html = session.get(next(query_gen)).text #
soup = BeautifulSoup(html, 'lxml')
elements = soup.select('.rg_meta.notranslate')
jsons = [json.loads(e.get_text()) for e in elements]
imageURLs = [js['ou'] for js in jsons]
if not len(imageURLs):
break
elif len(imageURLs) > maximum - total:
result += imageURLs[:maximum - total]
break
else:
result += imageURLs
total += len(imageURLs)
for i in trange(len(result), desc='get_img '+name):
try:
urllib.request.urlretrieve(
result[i], data_dir + name + '/' + str(i + 1).zfill(4) + '.jpg')
except:
continue
# 顔画像の切り出し
def pic_face(in_dir, out_dir, name):
pic = os.listdir(in_dir + name + '/')
for i in trange(len(pic), desc= '+ pic_face '+name):
image_gs = cv2.imread(in_dir + name + '/' + pic[i])
cascade = cv2.CascadeClassifier("./haarcascades/haarcascade_frontalface_alt.xml")
face_list = cascade.detectMultiScale(image_gs,scaleFactor=1.1,minNeighbors=1,minSize=(1,1))
no = 1
for rect in face_list:
x, y = rect[0], rect[1]
width, height = rect[2], rect[3]
dst = image_gs[y:y + height, x:x + width]
save_path = out_dir + name + '/' + '/' +'out_(' + str(i) +')' + str(no) + '.jpg'
cv2.imwrite(save_path, dst)
no +=1
# 顔画像のスクリーニング
def screening_face(size):
file_list = glob.glob('./out/' +name+ '/*.jpg')
for file in tqdm(file_list, desc='+ screening '+ name):
f_size = os.path.getsize(file)
if f_size < size:
os.remove(file)
######## 顔画像のソート ######## (追加)
def sort_face(in_dir, out_dir, name):
img2vec = Img2Vec()
# 顔画像のベクトル化
pics = {}
for file in tqdm(os.listdir(in_dir+name), desc='+ img2vec '+name):
filename = os.fsdecode(file)
img = Image.open(os.path.join(in_dir+name, filename))
vec = img2vec.get_vec(img)
pics[filename] = vec
# 顔画像のスコアリング(全ての他の画像とのcos類似度を計算し合計する)
sims ={}
for key1 in tqdm(list(pics.keys()), desc='+ scoring '+name):
score = 0
for key2 in list(pics.keys()):
if key1 == key2:
continue
point = cosine_similarity(pics[key1].reshape((1, -1)), pics[key2].reshape((1, -1)))[0][0]
score += point
sims[key1] = score
# スコアリングに従って画像をソート
d_view = [(v, k) for k, v in sims.items()]
d_view.sort(reverse=True)
count = 0
for v, k in tqdm(d_view, desc='+ sort '+name):
image = Image.open(in_dir+name+'/'+k)
image.save(out_dir+name+'/'+'{0:04d}'.format(count)+'.png')
count +=1
def main():
# 画像取得
make_dir('./data/', name)
query = query_gen(name)
get_img(query, maximum, './data/')
# 顔画像の切り出し
make_dir('./out/', name)
pic_face('./data/', './out/', name)
# 顔画像のスクリーニング
screening_face(2000)
######## 顔画像のソート ######## (追加)
make_dir('./vec/', name)
sort_face('./out/', './vec/', name)
if __name__ == '__main__':
target = ['新垣結衣', '綾瀬はるか', '石原さとみ', '柏木由紀']
maximum = 500 # 最大ダウンロード枚数
for i in range(len(target)):
name = target[i]
main()

さて、結果どうなったかと言うと、

スコアの高い順に画像が並び、ゴミ画像は終わりの方にまとまっていました。これなら、ザッと見て何処かで線を引き、スコアの低い画像はバッサリと削除すれば、大方片付きそうです。
但し、他の人の顔まで精度良く見分けているかというと、まだまだの様なので、ここは自分でチェックする必要はあります。
まだ完全自動というわけには行きませんが、これなら、100人分のチェックを勢いでやってみても良いかな。。。。
<参考リンク>
[https://github.com/MexsonFernandes/Img2VecCosSim-Django-Pytorch]
*画像をベクトル化するモジュール作成において、Img2VecCosSim-Django-Pytorch/main/views.py を参考にさせて頂きました。