1.はじめに
東北大学の山本大輔教授によれば、人には結婚相手を選ぶ時に本能として持っている基準があるそうです。その基準は、男性は女性を顔で選び、女性は男性を身長で選ぶ(背の低い女性は自分よりぐんと背の高い男性を選び、背の高い女性は自分より少し背の高い男性を選ぶ)ということです。
顔が整っているのは成長過程で大きな病気もせず充分な栄養が取れていて健康である証拠。身長が高いのは体が大きくて生存競争に勝てる証拠。なので、その基準で結婚相手を選ぶと最も子孫を多く残せるということらしいです。
なるほど、もし女性も男性を顔で選ぶとすると男はイケメンばかりになってしまいますが、そうならないのは、その基準が影響しているのかもしれませんね。
2.綾瀬はるかメガネとは?
この様に、男性は本能的に女性の顔に拘ります。もし、本能的に綾瀬はるかの顔が好きであるとすれば、誰の顔を見ても綾瀬はるかに見えるメガネがあれば、とても嬉しいのではないしょうか。
例えば、結婚歴30年の夫婦がいて、夫は綾瀬はるかの顔が好きだとしましょう。綾瀬はるかメガネを掛ければ、倦怠期で普段は会話がほとんどない二人の夕食も、会話が弾んで楽しくなるのではないでしょうか。
あっ、通勤の時に、綾瀬はるかメガネを掛けてはいけませんよ。ホームに溢れている人や混雑した車内の人の顔が全員綾瀬はるかだとしたら、いくら好きでも流石にちょっと不気味だと思いますので。
ということで、前々回「PCAによる次元削減」、前回「PCAによると画像の識別」に続き、今回はPCAネタの第3弾として、PCAを使って誰の顔を見ても綾瀬はるかに見えるメガネを考えてみます。
3.綾瀬はるかメガネのアイディア
まず、画像の主成分分析(PCA)についておさらいをすると、沢山の画像データから、主成分(固有ベクトル)を取り出します。
この時、画像データが64*64ピクセルだとすると、主成分は全部で 64*64=4,096次元あるわけですが、最初の40次元の主成分で全体の8割の情報量を持つという様な感じで、情報量は前の方に偏っています。
そのため、必要な情報量を確保したら残りの次元は、バッサリ切り落とすということで次元削減が出来るわけです。

主成分(固有ベクトル)が確定すれば、後は簡単。綾瀬はるかのオリジナル画像を主成分を使って変換(tranceform)すると、綾瀬はるかの特徴が取り出せます。
そして、綾瀬はるかの特徴を主成分を使って逆変換(inverse_tranceform)すると、元の画像にほぼ復元出来るわけです。
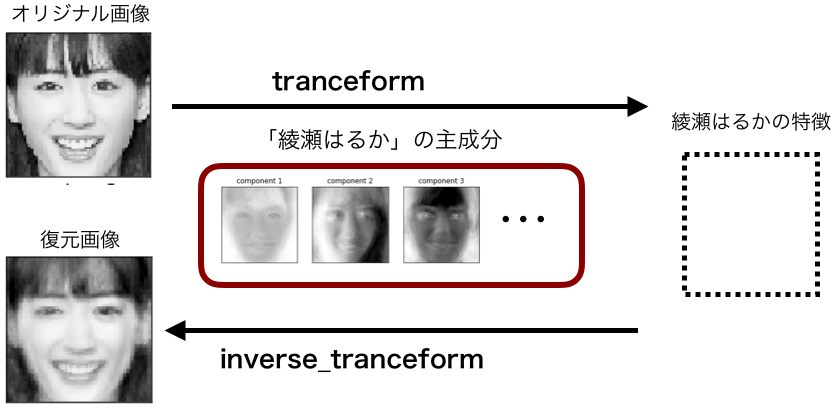
ここで、オリジナル画像を綾瀬はるか以外の人に入れ替えたら、どうなるでしょうか? 主成分が上手く作用して、綾瀬はるかの特徴をなんとかして取り出そうとするのではないか、そうすれば復元した人は、綾瀬はるかっぽくなるのではないか、というのがアイディアです。
ええ。とても安直なアイディアです。でも、一度やってみるのも面白そうですよね。
3.データの準備
綾瀬はるかさんの顔画像185枚と、テスト画像128枚を用意して読み込みます。その後、カラーからモノクロに変換して、64*64ピクセルに揃えたものをデータとします。
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from sklearn.decomposition import PCA
from PIL import Image
import glob
# 初期設定
folder = ['ayase', 'sample']
image_size = 64
# データ画像の読み込み
x = []
y = []
for index, name in enumerate(folder):
dir = './data/' + name
files = glob.glob(dir+'/*.png')
for file in files:
image = Image.open(file)
image = image.convert('L') # カラーを白黒に
image = image.resize((image_size, image_size)) # image_seize * image_size に縮小
data = np.asarray(image)
x.append(data)
y.append(index)
X = np.array(x)
y = np.array(y) # ayase:0, sample:1
X = X.reshape(X.shape[0], image_size * image_size)
X = X / 255.0
# 画像表示関数
def disp_data(X):
rows, cols = 3, 10 #3行10列
fig, aX_invs = plt.subplots(ncols=cols, nrows=rows, figsize=(18, 6))
for i in range(30):
r = i // cols
c = i % cols
aX_invs[r, c].imshow(X[i].reshape(image_size,image_size),vmin=0.0,vmax=1.0, cmap = cm.Greys_r)
aX_invs[r, c].set_title('data %d' % (i+1))
aX_invs[r, c].get_xaxis().set_visible(False)
aX_invs[r, c].get_yaxis().set_visible(False)
plt.show()
X_ayase = X[y==0] # 綾瀬はるか 画像の指定
print('X_ayase.shape =', X_ayase.shape)
disp_data(X_ayase)
X_sample = X[y==1] # sample 画像の指定
print('X_sample.shape =', X_sample.shape)
disp_data(X_sample)


綾瀬はるか、サンプル画像とも、最初から30個のデータを表示しています。
データの形はそれぞれ、X_ayase.shape=(185,4096), X_sample.shape=(128, 4096)です。
for index, name in enumerate(folder): によって、'ayase'フォルダーから読み込んだ画像には y=0、'sample'フォルダーから読み込んだ画像には y=1というインデックスを付けています。
こうすることで、X[y==0]で綾瀬はるかの画像、X[y==1]でsampleの画像を指定することが出来ます。
4.綾瀬はるかの主成分
綾瀬はるかメガネのキモである、主成分を画像にして見てみましょう。
# 第1〜第50成分の画像の表示
N = 50
pca = PCA(n_components=N)
pca.fit(X_ayase)
rows, cols = 5, 10 #5行10列
fig, aX_invs = plt.subplots(ncols=cols, nrows=rows, figsize=(18, 9))
for i in range(N):
r = i // cols
c = i % cols
aX_invs[r, c].imshow(pca.components_[i].reshape(image_size,image_size),vmin=-0.05,vmax=0.05, cmap = cm.Greys_r)
aX_invs[r, c].set_title('component %d' % (i+1))
aX_invs[r, c].get_xaxis().set_visible(False)
aX_invs[r, c].get_yaxis().set_visible(False)
plt.show()

第1〜第50成分までを表示しています。冒頭は基本的な部分を表現する部分があり、その後は詳細な表情が続きます。
ここで、ポイントとなるのは、綾瀬はるかメガネは、どこまでの主成分を採用したら良いのかということです。
冒頭の主成分だけしか使わないと、基本的な部分だけを見るので、綾瀬はるか以外の画像でも、そう違和感なく変換出来ますが、ボヤッとした感じになってしまいます。
では、どんどん使う主成分を増やして行くと、詳細部分を見るわけで、シャープな感じのメガネになりますが、今度は綾瀬はるかの特徴との違いが際立ってしまいます。
元々、綾瀬はるかではない画像から、詳細な綾瀬はるか情報を取り出そうとしても、無理があるわけです。
それではどの当たりでバランスさせるか。これは、実際にやってみるのが良さそうです。
5.採用主成分数と全体情報のカバー率の関係
実際にやってみる前に、主成分を増やした時に、全体の情報をどれだけカバーするのかをパレート図で見てみましょう。
N = 100
pca = PCA(n_components = N)
X_pca = pca.fit_transform(X_ayase)
print('n_components =', N)
print('explained_variance_ratio = ', pca.explained_variance_ratio_.sum())
eigen_vals = pca.explained_variance_ratio_
tot = sum(eigen_vals)
var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)]
cum_var_exp = np.cumsum(var_exp)
plt.figure(figsize=(12, 8), dpi = 50)
plt.tick_params(labelsize = 20)
plt.bar(range(1, 101), var_exp, alpha=0.5, align='center',
label='individual explained variance')
plt.step(range(1, 101), cum_var_exp, where='mid',
label='cumulative explained variance')
plt.ylabel('Explained variance ratio', fontsize = 20)
plt.xlabel('Principal component index', fontsize = 20)
plt.legend(loc='best', fontsize = 20)
plt.tight_layout()
plt.show()
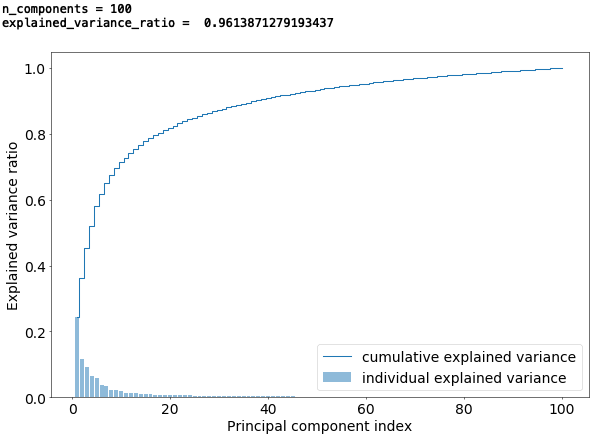
第1〜第100主成分(n_components=100)で、全体の情報量の96.13%(explained_variance_ratio=0.9613)をカバーしています。
パレート図を見ると、ザックリと、第20主成分までで8割くらい、第10主成分までで7割くらいをカバーする感じでしょうか。
6.採用主成分の最適化
採用する主成分で、どれだけ綾瀬はるからしさをシャープに変換出来るのかを、少数のサンプルで実際に試してみます。
print('X_sample', end='')
fig, aX_invs = plt.subplots(nrows=1, ncols=6, figsize=(14,4))
for i in range(6):
aX_invs[i].imshow(X_sample[i].reshape(image_size, image_size),vmin=0.0,vmax=1.0, cmap = cm.Greys_r)
aX_invs[i].set_title('data %d' % (i+1))
aX_invs[i].get_xaxis().set_visible(False)
aX_invs[i].get_yaxis().set_visible(False)
plt.show()
test = [5, 15, 30, 100, 185]
for Num in test:
pca = PCA(n_components=Num)
X_pca = pca.fit_transform(X_ayase)
print('n_components = ', Num)
print('explained_variance_ratio = ', pca.explained_variance_ratio_.sum(), end='')
X_trans = pca.transform(X_sample)
X_inv = pca.inverse_transform(X_trans)
fig, aX_invs = plt.subplots(nrows=1, ncols=6, figsize=(14,4))
for i in range(6):
aX_invs[i].imshow(X_inv[i,:].reshape(image_size, image_size),vmin=0.0,vmax=1.0, cmap = cm.Greys_r)
aX_invs[i].set_title('data %d' % (i+1))
aX_invs[i].get_xaxis().set_visible(False)
aX_invs[i].get_yaxis().set_visible(False)
plt.show()


第5主成分(n_components = 5)までだと、綾瀬はるかに見えますが、皆んな同じ顔をしています。
第30主成分(n_components = 30)までだと、少し綾瀬はるか以外の要素が入って来ていることが分かります。
第100成分(n_components = 100)までだと、ほとんどサンプルと同じような感じになって来ます。
そうすると、第15成分(n_components = 15)までくらいが、丁度良いバランスではないでしょうか。この時、全体の情報量のカバー率(explained_variance_ratio)は**約74%**です。
7.綾瀬はるかメガネの性能
先ほどの結果を元に、採用する主成分は第15成分(n_components = 15)として、色々なサンプル画像を綾瀬はるかメガネで見た結果を見てみましょう。
def Glasses(shift):
pca = PCA(n_components=15)
X_pca = pca.fit_transform(X_ayase)
X_trans = pca.transform(X_sample)
X_inv = pca.inverse_transform(X_trans)
fig, aX_invs = plt.subplots(nrows=2, ncols=6, figsize=(14,4.5))
for i in range(6):
aX_invs[0, i].imshow(X_sample[i+shift].reshape(image_size, image_size),vmin=0.0,vmax=1.0, cmap = cm.Greys_r)
aX_invs[0, i].set_title('data %d' % (i+shift+1))
aX_invs[0, i].get_xaxis().set_visible(False)
aX_invs[0, i].get_yaxis().set_visible(False)
aX_invs[1, i].imshow(X_inv[i+shift].reshape(image_size, image_size),vmin=0.0,vmax=1.0, cmap = cm.Greys_r)
aX_invs[1, i].set_title('↓')
aX_invs[1, i].get_xaxis().set_visible(False)
aX_invs[1, i].get_yaxis().set_visible(False)
plt.show()
for i in range(0, 126, 6):
Glasses(i)

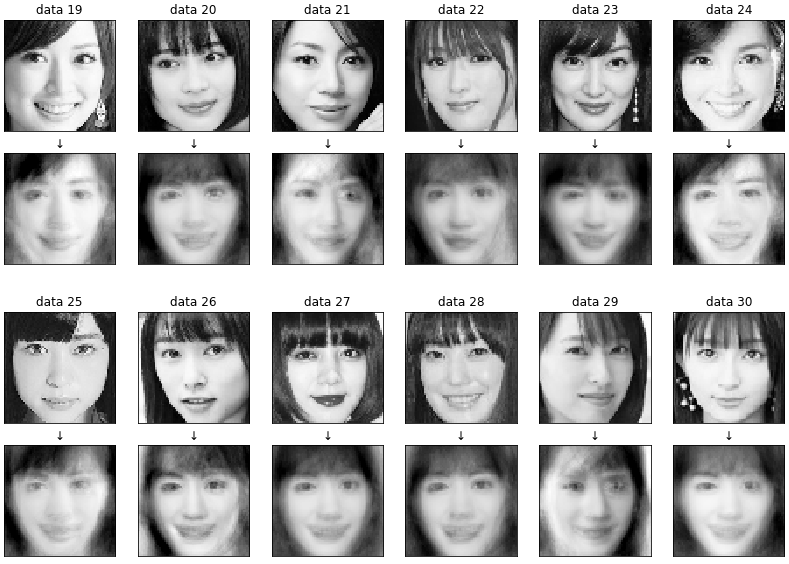
表示は途中で省略します。
なんとなく綾瀬はるかの雰囲気はあるものの、かなりボヤッとした感じになるので、実用化は難しそうですね(当たり前か)。