1.はじめに
機械学習で良く使われる前処理を備忘録として、jupyter_notebook形式でまとめてみます。データセットは、kaggleの home_loanを使います。
2.表示設定の変更
jupyter notebbokの画面表示は妙に幅が狭いし、沢山の列や行を表示すると途中が・・・で省略されてしまいます。そこで、必要に応じて最初に表示設定を変更しておくと便利です。
# 画面表示幅の拡大
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
# 最大表示列数・行数を変更
import pandas as pd
pd.options.display.max_columns = 50 # 最大列表示設定(デフォルト20)
pd.options.display.max_rows = 100 # 最大行表示設定(デフォルト60)
3.学習データの読み込み
今回は、学習データとテストデータを分けて読み込んで処理します。まずは、学習データの読み込みです。
train = pd.read_csv('./train.csv')
train.head()

次に、特徴量とターゲットに分離します。
# 特徴量とターゲットに分割
X_train = train.iloc[ : , :-1] # 全ての行、最終列を除く列
y_train = train.iloc[ : , -1] # 全ての行、最終列
X_train = X_train.drop('Loan_ID', axis=1) # Loan_ID列を削除
y_train = y_train.map( {'Y':1, 'N':0} ) # Yを1, Nを0に置き換え
X_train.head()

特徴量をその都度簡単にチェックする為に、関数check(df)を定義しておきます。
# 特徴量チェック
def check(df):
col_list = df.columns.values # 列名を取得
row = []
for col in col_list:
tmp = ( col, # 列名
df[col].dtypes, # データタイプ
df[col].isnull().sum(), # null数
df[col].count(), # データ数 (欠損値除く)
df[col].nunique(), # ユニーク値の数 (欠損値除く)
df[col].unique() ) # ユニーク値
row.append(tmp) # tmpを順次rowに保存
df = pd.DataFrame(row) # rowをデータフレームの形式に変換
df.columns = ['feature', 'dtypes', 'nan', 'count', 'num_unique', 'unique'] # データフレームの列名指定
return df
check(X_train)
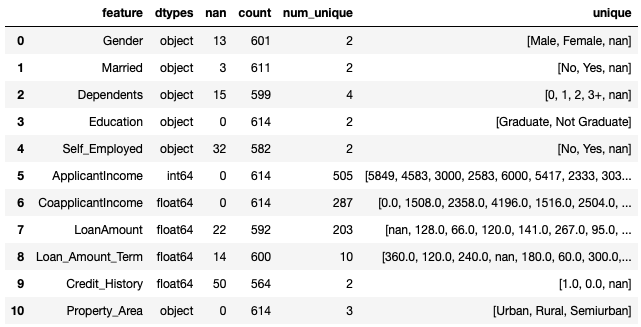
featureは特徴量名、dtypesはデータの型、nanは欠損値の数、countはデータ数(欠損値を除く)、num_uniqueはユニーク値の数(欠損値を除く)、uniqueはユニーク値です。
4.カテゴリー変数の処理
基本的に、object がカテゴリー変数ですが、数値でもカテゴリー変数にするやり方があります。Credit_History は、数値(float64)ですが、ユニーク値の数は2なので今回はカテゴリー変数にしてみましょう。
Credit_History のデータ型をobjectに変更します。
# Credit_History をObjectに変換
X_train['Credit_History'] = X_train['Credit_History'].astype(object)
object型の特徴量とターゲットとの関係を見てみましょう。まず、object の欠損値を'nan'に置き換えます。
# Objectの欠損値を'nan'に置き換え
c_list = X_train.dtypes[X_train.dtypes=='object'].index.tolist() # Objectの列名リスト取得
X_train[c_list] = X_train[c_list].fillna('nan')
sns.barplot を使って、object型の各特徴量とLoan_Statusとの関係をグラフ化します。グラフは平均値が高さで、信頼区間がエラーバーで表示されます。
# object 型特徴量とターゲットとの関係
import matplotlib.pyplot as plt
import seaborn as sns
fig = plt.figure(figsize=(14,6))
for j , i in enumerate([0, 1, 2, 3, 4, 9, 10]):
ax = fig.add_subplot(2, 4 , j+1)
sns.barplot(x=X_train.iloc[:,i], y=y_train, data=X_train, palette='Set3' )
plt.tight_layout()
plt.show()
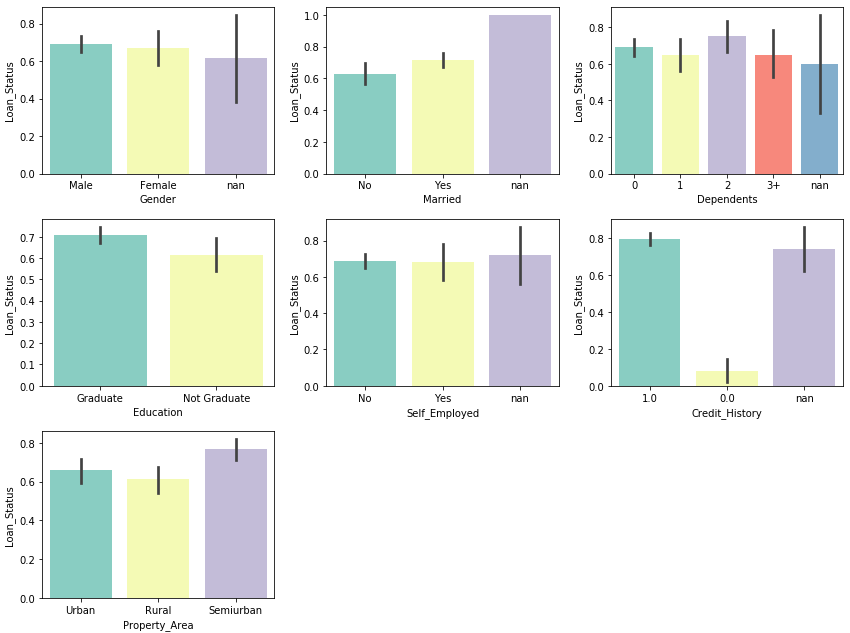
Credit_History がLoan_Statusに最も影響を与えている様です。
カテゴリー変数の場合、ワンホットエンコーディングする場合が多くあります。それは、特徴量の要素を分解することで、予測に有効に効く特徴量の要素のみを選ぶことが出来るためです。ここでも、objectをワンホットエンコーディングします。
# カテゴリ変数のワンホットエンコーディング
X_train1 = pd.get_dummies(X_train)
check(X_train1)
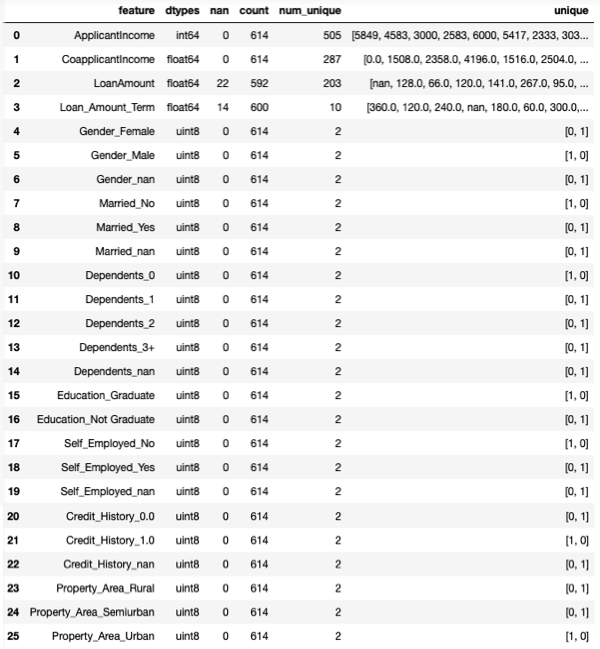
特徴量は全部で26個になりました。
5.数値変数の処理
数値変数の場合、欠損値の補完は、平均(mean)、メジアン(median)、最頻値(most_frequent)、一定値(constant)などがありますが、ここでは平均(mean)を使います。
# 数値の欠損値補完
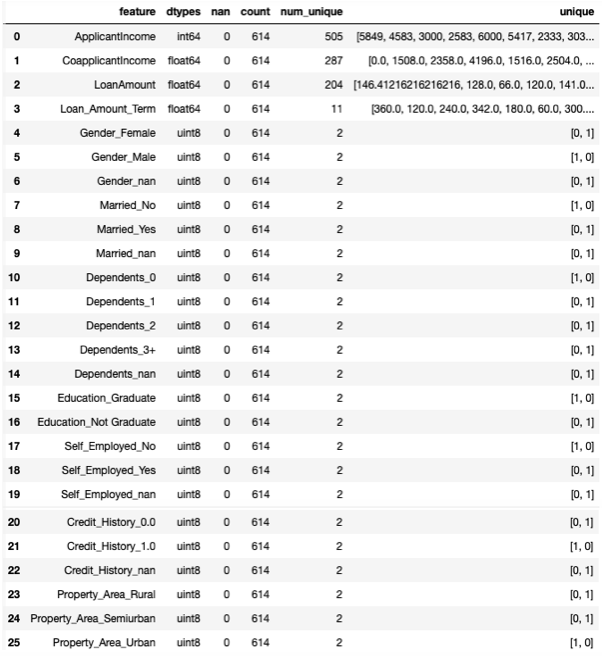
X_train2 = X_train1.fillna(X_train1.mean())
check(X_train2)
それでは、sns.FacetGridを使って、各数値変数にLoan_Statusが0の時と1の時のヒストグラムを描かせてみます。
X_tmp = X_train2.join(y_train)
for i in [0, 1, 2, 3]:
facet = sns.FacetGrid(X_tmp, hue='Loan_Status', aspect=2)
facet.map(sns.kdeplot, X_tmp.columns.values[i], shade= True)
facet.set(xlim=(0, X_tmp.iloc[:, i].max()))
facet.add_legend()
plt.show()
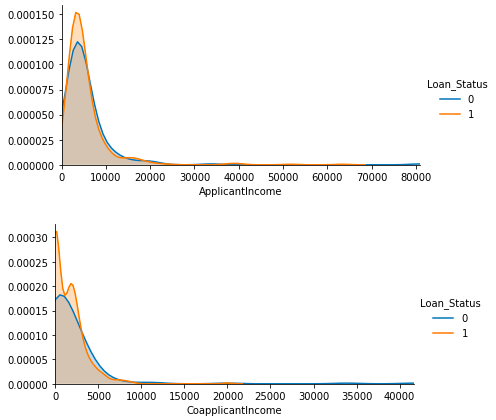
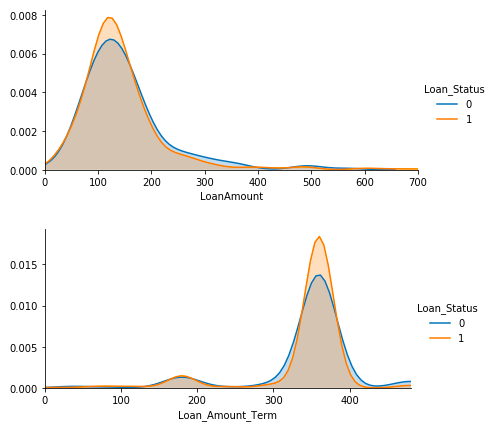
4つの特徴量は、いずれも、Loan_Status1が明らかに優位になる領域があります。
8.特徴量の重要度
ランダムフォレストのジニ係数を使って、26個ある特徴量の優先順位付けをしてみます。
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# ランダムフォレストで fit
clf = RandomForestClassifier(n_estimators=100, random_state=0)
clf.fit(X_train2, y_train)
# 特徴量の重要度表示
labels = X_train2.columns.values # 特徴量のラベル取得
importances = clf.feature_importances_ # 特徴量の数値取得
index = np.argsort(importances) # 昇順インデックス取得
plt.figure(figsize=(8, 5))
plt.barh(range(X_train2.shape[1]), importances[index])
plt.yticks(range(X_train2.shape[1]), labels[index])
plt.title('feature importances')
plt.show()
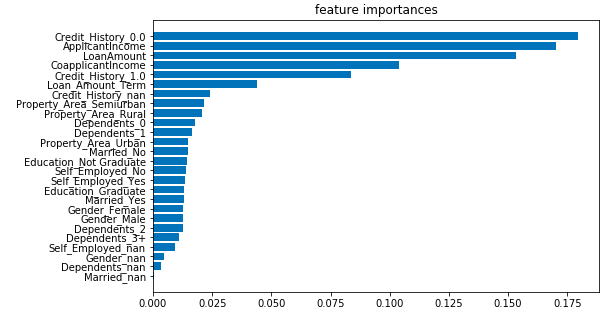
ベスト3は、Credit_History_0.0, ApplicantIncome, LoanAmount です。
9.特徴量の絞り込み
RFE (Recursive Feature Elimination)によって、特徴量の削減を行います。そのアルゴリズムは、すべての特徴量から開始してモデルを作り、そのモデルで最も重要度が低い特徴量を削除します。そしてまたモデルを作り、最も重要度が低い特徴量を削除するという過程を事前に定めた数の特徴量になるまで繰り返します。
from sklearn.feature_selection import RFE
clf = RandomForestClassifier(n_estimators=100, random_state=0)
selector = RFE(estimator=clf,
n_features_to_select=10, # 特徴量の絞り込み数
step=.05) # 1ステップ毎に切り捨てる特徴量のパーセンテージ
selector.fit(X_train2, y_train)
# 26次元を10次元に圧縮
select = selector.transform(X_train2)
X_train3 = pd.DataFrame(select,
columns=X_train2.columns[selector.support_])
check(X_train3)
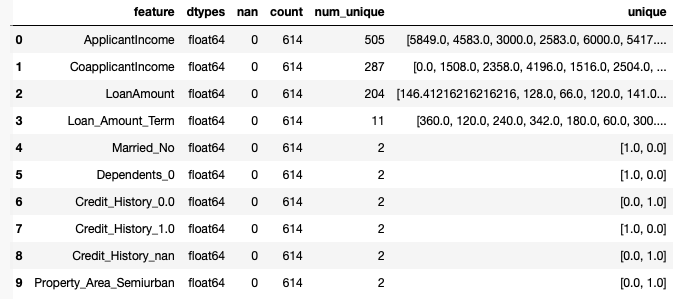
これが最終的に得られた、学習データです。
10.テストデータの読み込みと処理
次に、テストデータを読み込みます。
# テストデータ読み込み
test = pd.read_csv('./test.csv')
X_test = test.drop('Loan_ID', axis=1) # Loan_ID列を削除
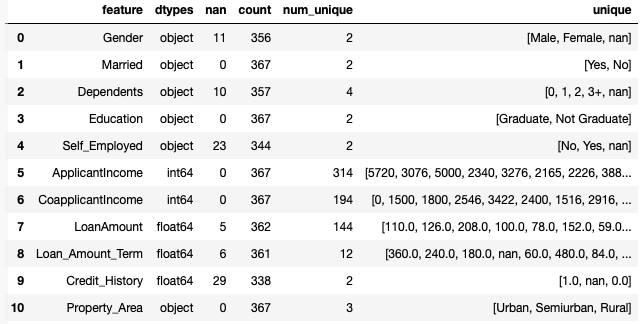
check(X_test)
先程と同様に、Credit_History をobjectに変換してから、欠損値を含めてワンホットエンコーディングします。
ここでは、pd.get_dummies()メソッドに、dummy_na = Trueというオプションを加えることで、一発で欠損値を含めてワンホットエンコーディングしています。
# Credit_History をObjectに変換
X_test['Credit_History'] = X_test['Credit_History'].astype(object)
# カテゴリ変数の欠損値補完とワンホットエンコーディング
X_test1 = pd.get_dummies(X_test,
dummy_na = True) # 欠損値も含める
check(X_test1)
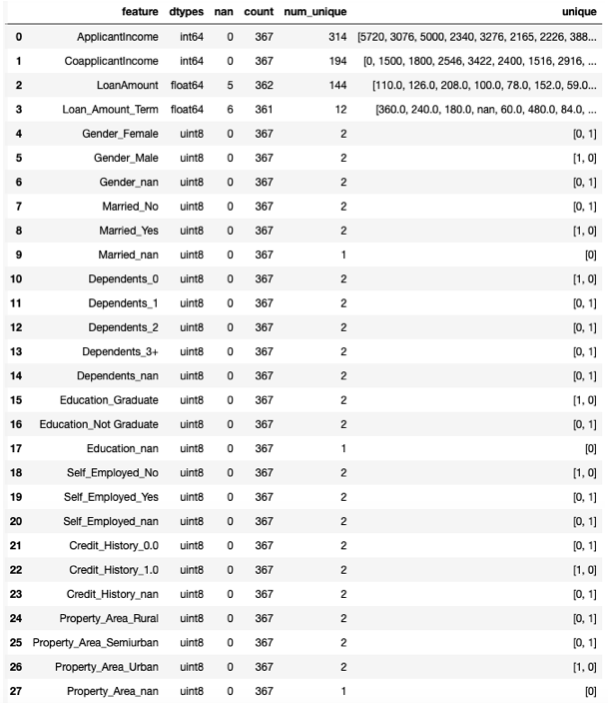
おや、学習データと比べると特徴量が2つ増えましたね。
これは、dummy_na=True オプションを使うと、欠損値がない場合でも、データが全て0の ○○○_nanを作るためです。
ここでは、9.Married_nan, 17.Education_nan, 27.Property_Area_nan がそれに該当します。
それでは、学習データとテストデータの特徴量の差を見てみましょう。
# 特徴量の名称を集合で読み込む
cols_train = set(X_train1.columns.values)
cols_test = set(X_test1.columns.values)
# trainにありtestにない特徴量
diff1 = cols_train - cols_test
print('trainのみ', diff1)
# testにありtrainにない特徴量
diff2 = cols_test - cols_train
print('testのみ', diff2)

testのみ、Education_nan, Property_Area_nan が多いという結果になりました。Married_nan はどうしたのかと言うと、学習データには Married_nan がユニーク値[0,1]でちゃんと存在するためです。
基本的には、testになくtrainにある特徴量は復活させ、testにありtrainにない特徴量は削除します。ここでは、testにありtrainにない特徴量のみ削除します。
X_test1 = X_test1.drop(['Education_nan', 'Property_Area_nan'], axis=1)
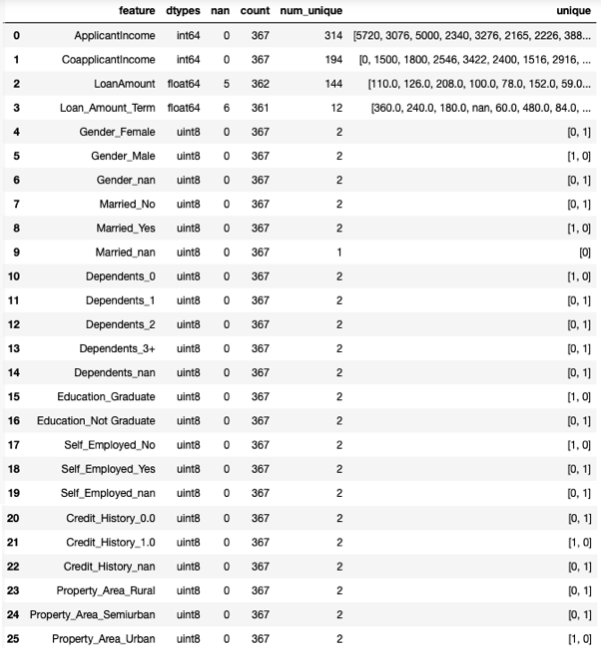
check(X_test1)
それでは、学習データの平均値を使って、数値変数の欠損値補完をします。
# 数値の欠損値補完
X_test2 = X_test1.fillna(X_train1.mean())
そして、学習データと同様に、最終的に10個に特徴量を絞り込みます。その前に、学習データとテストデータの特徴量の並び順を担保しておきます。
# X_test2の特徴量をX_train2と同じ並び順にする
X_test1 = X_test1.reindex(X_train1.columns.values,axis=1)
最後に、学習データで行った、RFEの絞り込み結果 selector.support_ を使って、テストデータも絞り込みを行います。
X_test3 = X_test2.loc[ : , X_test2.columns[selector.support_]]
check(X_test3)
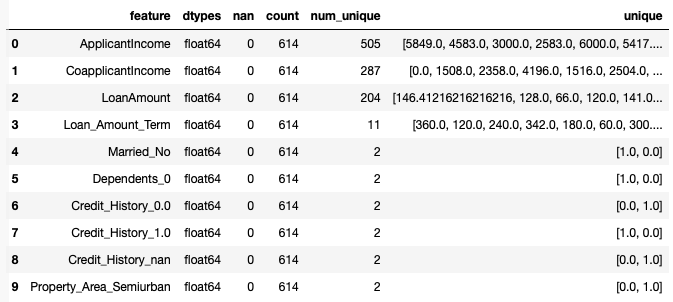
最終的なテストデータです。これで、データ前処理が完了しました。