1.はじめに
今回は、GANについて簡単にまとめます。
2.GANについて
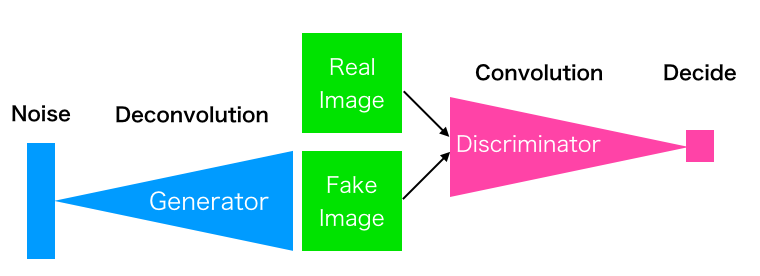
GANは、生成器(Generator)及び識別器(Discriminator)という2つの競合するモデルからなります。Generatorはノイズzを入力とし、新しいデータG(z)を生成・出力します。Discriminatorは与えられたデータが学習データか、Generatorが生成したものかを識別します。
両方のモデルを交互に学習させることで、Generatorは限りなく学習データに近い分布のデータを生成し、Discriminatorはその様なデータに対しての識別制度を高めようとするわけです。この様なネットワークは、生成ネットワークが敵対者との競争下におかれるゲーム理論的状況に基づいています。
学習が進み、Generator および Discriminator それぞれが理想的な性能を有するようになった場合、Generator の生成する データ分布𝑝𝑔と訓練データの分布𝑝𝑑𝑎𝑡𝑎が一致するため、𝐷(𝒙)=0.5となります。
3.GANのロス関数

GANのロス関数は、上記の様です。GANの学習に置いて、Discriminatorは学習データx, 生成データG(z)それぞれに対して学習データ及び生成データであると正しく判定する確率を最大化しようとします。Generatorは、Discriminatorが生成データを学習データと誤判定する確率を最大化(生成データを偽物と判定する確率を最小化)しようとします。
4.DCGANの特徴
GAN(Deep Convolutional Generative Adversarial Network)のポイントを簡単にまとめておきます。
1)Batch Normalization を使う
2)Discriminator では pooling ではなく stride=2の畳み込みを使う
3)Generator では deconvolution を使う
4)FC層を無くして Global Average Poolingを使う
5)Discriminator では **Leaky ReLU (α=0.2)**を使う
6)Generator では基本的 にReLU を使い、出力層のみ Tanh を使う