1.はじめに
今回は、LSTMの理解を深める為に、TensorFlowでLSTMをスクラッチで書いてみます。
2.LSTMのブロック図
Forget_gate付きLSTMのブロック図は以下の様で、4つの小さなネットワーク( output_gate, input_gate, forget_gate, z )から構成されていることが分かります。
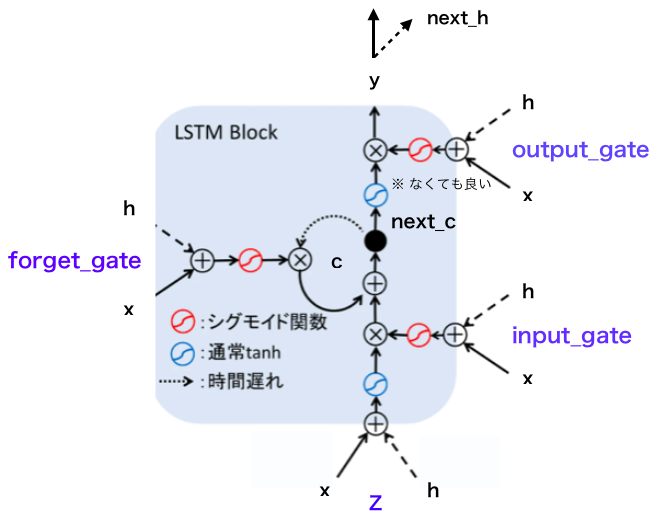
Z は、覚えておきたい入力があったら忘れないように重みWを大きくしたいのですが、Wを大きくすると覚えなくても良い情報も覚えてしまうので結局覚えておきたかった情報が上書きされてしまいます。これを**入力重み衝突(input weight conflict)**と言います。それを回避するために、input_gate は、関係なさそうな情報をブロックしてメモリセルCに書き込ませないようにします。
forget_gate は、必要に応じてメモリセルCの情報を消します。時系列データは、ある条件を満たしたら、一気に系列が変わることがあるため、その時に今まで覚えた情報をリセットする必要があるためです。
output_gate は、入力の場合と同様に、出力重み衝突を回避するために、メモリセルCの内容を全部読み込みのではなく、不要なものを消します。
3.LSTM中間層のスクラッチコード
4つあるネットワークの重み self.W とバイアス self.B の形は同じなので、まとめて宣言します。
self.W = tf.Variable(tf.zeros([input_size + hidden_size, hidden_size *4 ]))
self.B = tf.Variable(tf.zeros([hidden_size * 4 ]))
順伝播のコードです。今回は、後処理の都合上、h, c をstackしているので、まず復元します。そして、4つのネットワークの重み付き線形和をまとめて計算し、結果を4分割します。
def forward(self, prev_state, x):
# h, c を復元
h, c = tf.unstack(prev_state)
# 4つのネットワークの重み付き線形和をまとめて計算
inputs = tf.concat([x, h], axis=1)
inputs = tf.matmul(inputs, self.W) + self.B
z, i, f, o = tf.split(inputs, 4, axis=1)
3つのゲートからの信号にsigmoidを通します。
# 各ゲートの信号にsigmoidを通す
input_gate = tf.sigmoid(i)
forget_gate = tf.sigmoid(f)
output_gate = tf.sigmoid(o)
ゲート及び中間層入力を元にメモリセルを更新して、中間層出力を計算します。なお、output_gate 前のtanhは無くても問題はないので、省いています。
# メモリセルの更新、中間出力の計算
next_c = c * forget_gate + tf.nn.tanh(z) * input_gate
next_h = next_c * output_gate
# 後処理の関係で stack する
return tf.stack([next_h, next_c])
4.コード全体
それでは、このLSTMを使って、実際に予測を実行するコードを作成します。データセットは、dagitsという数字の0〜9 (8*8ピクセルの小さなもの) の画像を使います。
1つのデータを1行づつ8回スキャンした結果を元に、LSTMにその数字は何かを予測させます。
import numpy as np
import tensorflow as tf
from sklearn import datasets
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
class LSTM(object):
def __init__(self, input_size, hidden_size, output_size):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# 入力層
self.inputs = tf.placeholder(tf.float32, shape=[None, None, self.input_size], name='inputs')
self.W = tf.Variable(tf.zeros([input_size + hidden_size, hidden_size *4 ]))
self.B = tf.Variable(tf.zeros([hidden_size * 4 ]))
# 出力層
self.Wv = tf.Variable(tf.truncated_normal([hidden_size, output_size], mean=0, stddev=0.01))
self.bv = tf.Variable(tf.truncated_normal([output_size], mean=0, stddev=0.01))
self.init_hidden = tf.matmul(self.inputs[:,0,:], tf.zeros([input_size, hidden_size]))
self.init_hidden = tf.stack([self.init_hidden, self.init_hidden])
self.input_fn = self._get_batch_input(self.inputs)
def forward(self, prev_state, x):
# h, c を復元
h, c = tf.unstack(prev_state)
# 4つのネットワークの重み付き線形和をまとめて計算
inputs = tf.concat([x, h], axis=1)
inputs = tf.matmul(inputs, self.W) + self.B
z, i, f, o = tf.split(inputs, 4, axis=1)
# 各ゲートの信号にsigmoidを通す
input_gate = tf.sigmoid(i)
forget_gate = tf.sigmoid(f)
output_gate = tf.sigmoid(o)
# メモリセルの更新、中間出力の計算
next_c = c * forget_gate + tf.nn.tanh(z) * input_gate
next_h = next_c * output_gate
# 後処理の関係で stack する
return tf.stack([next_h, next_c])
def _get_batch_input(self, inputs):
return tf.transpose(tf.transpose(inputs, perm=[2, 0, 1]))
def calc_all_layers(self):
all_hidden_states = tf.scan(self.forward, self.input_fn, initializer=self.init_hidden, name='states')
return all_hidden_states[:, 0, :, :]
def calc_output(self, state):
return tf.nn.tanh(tf.matmul(state, self.Wv) + self.bv)
def calc_outputs(self):
all_states = self.calc_all_layers()
all_outputs = tf.map_fn(self.calc_output, all_states)
return all_outputs
# データセットの読み込み ( 8*8 image of a digit)
digits = datasets.load_digits()
X = digits.images
Y_= digits.target
Y=tf.keras.utils.to_categorical(Y_, 10)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
print(Y.shape)
# 予測実行
hidden_size = 50
input_size = 8
output_size = 10
y = tf.placeholder(tf.float32, shape=[None, output_size], name='inputs')
lstm = LSTM(input_size, hidden_size, output_size)
outputs = lstm.calc_outputs()
last_output = outputs[-1]
output = tf.nn.softmax(last_output)
loss = -tf.reduce_sum(y * tf.log(output))
train_step = tf.train.AdamOptimizer().minimize(loss)
correct_predictions = tf.equal(tf.argmax(y, 1), tf.argmax(output, 1))
acc = (tf.reduce_mean(tf.cast(correct_predictions, tf.float32)))
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
log_loss = []
log_acc = []
log_val_acc = []
for epoch in range(100):
start=0
end=100
for i in range(14):
X=X_train[start:end]
Y=y_train[start:end]
start=end
end=start+100
sess.run(train_step,feed_dict={lstm.inputs:X, y:Y})
log_loss.append(sess.run(loss,feed_dict={lstm.inputs:X, y:Y}))
log_acc.append(sess.run(acc,feed_dict={lstm.inputs:X_train[:500], y:y_train[:500]}))
log_val_acc.append(sess.run(acc,feed_dict={lstm.inputs:X_test, y:y_test}))
print("\r[%s] loss: %s acc: %s val acc: %s"%(epoch, log_loss[-1], log_acc[-1], log_val_acc[-1])),
# acc グラフ作成
plt.ylim(0., 1.)
plt.plot(log_acc, label='acc')
plt.plot(log_val_acc, label = 'val_acc')
plt.legend()
plt.show()
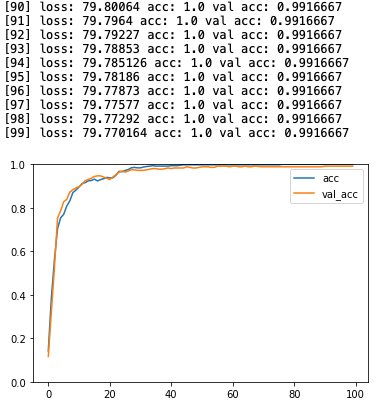
割と良い精度ですね。