1.はじめに
今回は、CNNモデルのGoogLeNetとResnetについて、まとめてみます。
2.GoogLeNet
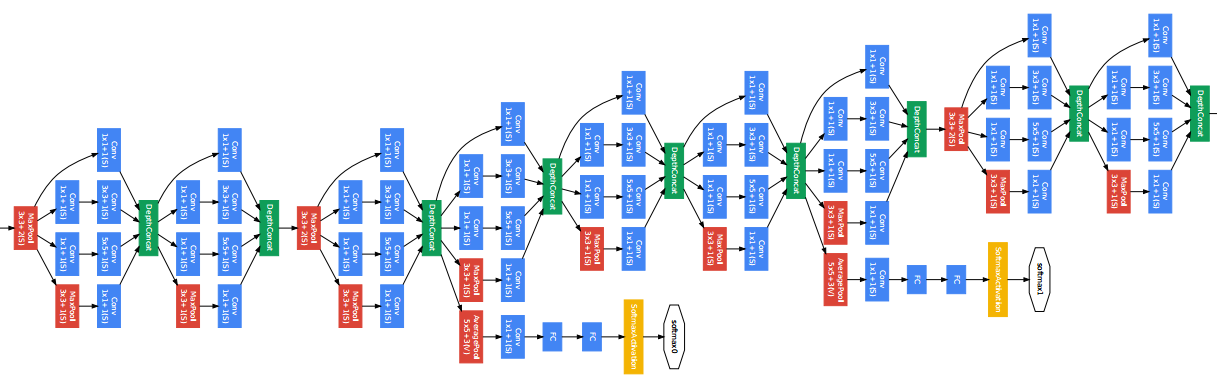
GoodLeNetは、2014年のILSVRCで優勝したモデルで、複雑に見えるモデルですが、初めて「モジュール」を1つ設計して、それを連結させて行く手法が導入されました。これ以降モジュールで考えると言うことが多くなりました。
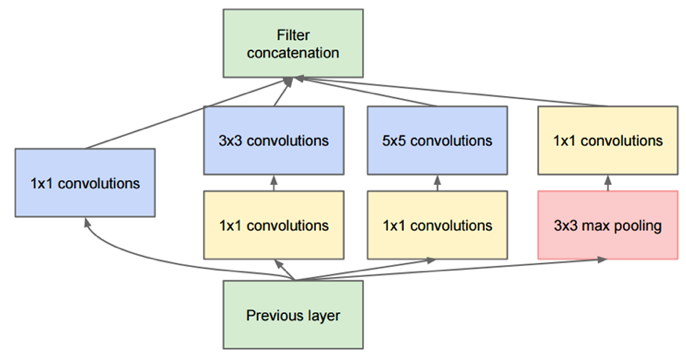
これが使われている Inception モジュールです。特徴は、1×1の畳み込みを積極的に使って、色々な変換を施してそれを全部連結することです。この1×1の畳み込みは次元削減と同等な効果を持っています。
小さな畳込みフィルタのグループで近似することで、 モデルの表現力とパラメータ数のトレードオフを改善していると言えます。
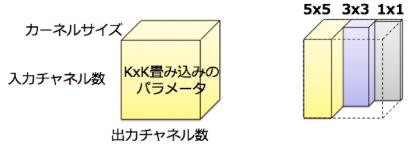
パラメータの削減は上図のように直感的に理解することができます。畳み込み層のパラメータ数はbias項を除くと入力チャネル数×出力チャネル数×カーネルサイズ(e.g. 5x5=25)で表現されます.
通常の畳み込みであれば,左のようにパラメータは全て何かしらの値を持っているためdenseです。一方,Inceptionでは異なるサイズの畳み込みを独立して行っているため,非0のパラメータ数が大きく減ることになります。
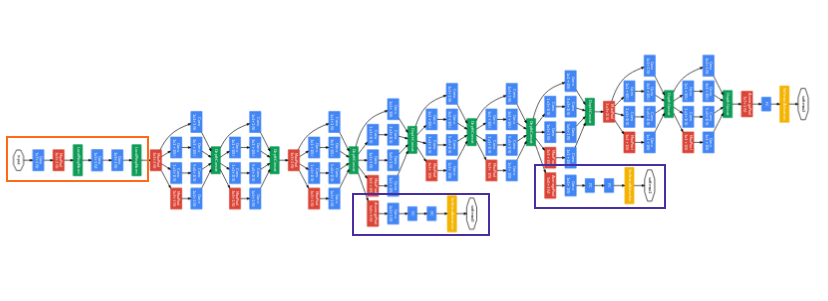
GoogLeNetの学習では,ネットワークの途中から分岐させたサブネットワークにおいてもクラス分類を行い,auxiliary lossを追加することが行われている.これにより,ネットワークの中間層に直接誤差を伝搬させることで,勾配消失を防ぐとともにネットワークの正則化を実現しています。
また、アンサンブル学習と同様の効果が得られるため、汎化性能の向上が期待できます。また、AuxililaryLossを導入しない場合でもBatchNormalizationを加えることにより、同様に学習がうまく進むことがあります。
3.ResNet
ディープラーニングは基本的に多層にするほど良いと考えられていましたが、50層を超えるとような大きなネットワークは勾配喪失の問題からパフォーマンスが低下してしまうことが知られていました。ResNetは、これを解決し超多層のネットワークも学習可能となりました。現在あるCNNは、ほぼこのResNetベースのモデルです。
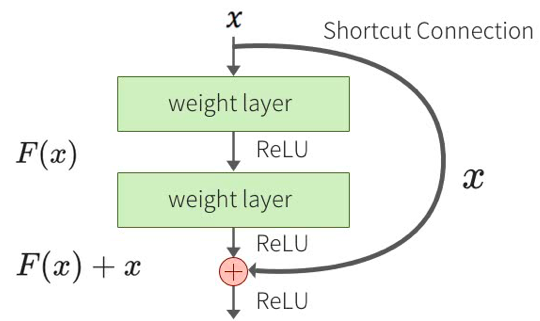
ResNet では層をまたがる結合として Identity mapping を用います。そうすることでスキップコネクションの内 側の層は ブロックの入出力の残差を学習することになります。
ResNetが上手く行くのは、ブロックへの入力にこれ以上の変換が必要ない場合は重みが 0 となり小さな変換が求められる場合は対応する小さな変動をより見つけやすくなること、バイパスすることによって入力層に近い層にも誤差が伝わり勾配消失が起き難いこと、色々なバイパスの組み合わせが存在することになりアンサンブル効果があること、などによります。
このように、多くの利点を持ちながら、やっていることは入力をショートカットして足すだけなので、計算コストはほとんど増えずに、実装も容易であることが特徴です。