pythonの基礎を備忘録として残しておく
summary
df = pd.read_csv('./data/stock_8308.tsv', sep='\t') # タブ区切りは'\t'で
* macは、'option'+'¥'
zenba = df[df['session'] == 0] # ' session'=0のデータフレーム
del zenba['session'] # 'session'項目を削除
dic = {} # 辞書の箱作成
for i in zenba.columns[1:]:
dic[i] = i + '_zenba' # 辞書の追加
zenba = zenba.rename(columns=dic) # 辞書を使って項目変更
# 辞書を利用した項目のrename
dic = {i:i+'_goba' for i in goba.columns[1:]} # 辞書を利用したrename(内包表記)
df = zenba.merge(goba, on='date') # 'zenba'と'goba'を'date'でマージ
df[df.isnull().any(axis=1)] # 欠損値をデータフレームで確認
df = df.dropna() # 欠損値を削除して表示
df['open'] = df['open_zenba'] # 対応
df['high'] = df[['high_zenba', 'high_goba']].max(axis=1) # 大きい方
df['low'] = df[['low_zenba', 'low_goba']].min(axis=1) # 小さい方
df['volume'] = df[['volume_zenba','volume_goba']].sum(axis=1) # 合計1
df['value'] = df['value_zenba'] + df['value_goba'] # 合計2
# 項目の各種置換
col = [i for i in df.columns if 'zenba' not in i and 'goba' not in i]
df = df[col]
# 'zenba','goba'を含まない項目のみにする
plt.plot(df['close']) # 'close'の折れ線グラフ
df = df[df["close"] < 50000]
df = df.reset_index(drop=True)
# グラフの最大値を50000以下に制限する
(df['close'] - df['open'] > 0).astype(int) # 大きければ1、そうでなければ0
x = df[['open', 'high', 'low', 'close', 'volume', 'value']]
y = df[['y']]
print(np.array(x.iloc[:threshold, :])) # train_x
print(np.array(y.iloc[:threshold, :]).flatten()) # train_y
# x, yのデータフレームを作り、np.arrayでデータ作成
ライブラリーのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
CSVファイルの読み込み
- タブ区切りの場合はsep='\t'で読み込む。なお、Macで''の入力は、option+'¥'
df = pd.read_csv('./data/stock_8308.tsv', sep='\t')
print(df.head())
# 出力
date session open ... close volume value
0 2007-01-04 0 323000.0 ... 325000.0 28930 9331985000
1 2007-01-04 1 NaN ... NaN 0 0
2 2007-01-05 0 324000.0 ... 321000.0 33418 10823882000
3 2007-01-05 1 321000.0 ... 321000.0 22827 7342975000
4 2007-01-09 0 320000.0 ... 329000.0 29230 9509112000``
前場(session = 0)のデータのみ表示
zenba = df[df['session'] == 0]
print(zenba.head())
# 出力
date session open ... close volume value
0 2007-01-04 0 323000.0 ... 325000.0 28930 9331985000
2 2007-01-05 0 324000.0 ... 321000.0 33418 10823882000
4 2007-01-09 0 320000.0 ... 329000.0 29230 9509112000
6 2007-01-10 0 332000.0 ... 329000.0 32163 10618725000
8 2007-01-11 0 328000.0 ... 329000.0 18594 6115344000
後場(session = 1)のデータのみ表示
goba = df[df['session'] == 1]
print(goba.head())
# 出力
date session open ... close volume value
1 2007-01-04 1 NaN ... NaN 0 0
3 2007-01-05 1 321000.0 ... 321000.0 22827 7342975000
5 2007-01-09 1 329000.0 ... 330000.0 31357 10375287000
7 2007-01-10 1 328000.0 ... 328000.0 20511 6729752000
9 2007-01-11 1 329000.0 ... 326000.0 16628 5437101000
前場、後場の項目が被らないようにリネームする。但し、'session'は削除、'date'はそのまま。
まず、前場をfor文で
del zenba['session']
print(zenba.columns)
dic = {}
for i in zenba.columns[1:]:
dic[i] = i + '_zenba'
print(dic)
zenba = zenba.rename(columns=dic)
print(zenba.head())
# 出力
Index(['date', 'open', 'high', 'low', 'close', 'volume', 'value'], dtype='object')
{'open': 'open_zenba', 'high': 'high_zenba', 'low': 'low_zenba', 'close': 'close_zenba', 'volume': 'volume_zenba', 'value': 'value_zenba'}
date open_zenba ... volume_zenba value_zenba
0 2007-01-04 323000.0 ... 28930 9331985000
2 2007-01-05 324000.0 ... 33418 10823882000
4 2007-01-09 320000.0 ... 29230 9509112000
6 2007-01-10 332000.0 ... 32163 10618725000
8 2007-01-11 328000.0 ... 18594 6115344000
後場を内包表記で
del goba['session']
print(goba.columns)
dic = {i:i+'_goba' for i in goba.columns[1:]}
print(dic)
print()
goba = goba.rename(columns=dic)
print(goba.head())
# 出力
Index(['date', 'open', 'high', 'low', 'close', 'volume', 'value'], dtype='object')
{'open': 'open_goba', 'high': 'high_goba', 'low': 'low_goba', 'close': 'close_goba', 'volume': 'volume_goba', 'value': 'value_goba'}
date open_goba ... volume_goba value_goba
1 2007-01-04 NaN ... 0 0
3 2007-01-05 321000.0 ... 22827 7342975000
5 2007-01-09 329000.0 ... 31357 10375287000
7 2007-01-10 328000.0 ... 20511 6729752000
9 2007-01-11 329000.0 ... 16628 5437101000
zenba と goba を'date'でマージする
df = zenba.merge(goba, on='date')
print(df.head())
# 出力
date open_zenba ... volume_goba value_goba
0 2007-01-04 323000.0 ... 0 0
1 2007-01-05 324000.0 ... 22827 7342975000
2 2007-01-09 320000.0 ... 31357 10375287000
3 2007-01-10 332000.0 ... 20511 6729752000
4 2007-01-11 328000.0 ... 16628 5437101000
欠損値を確認する
tmp = df[df.isnull().any(axis=1)]
print(tmp)
# 出力
date open_zenba ... volume_goba value_goba
0 2007-01-04 323000.0 ... 0 0
244 2007-12-28 200000.0 ... 0 0
245 2008-01-04 191000.0 ... 0 0
414 2008-09-08 NaN ... 13819 1433030300
486 2008-12-25 NaN ... 0 0
487 2008-12-26 NaN ... 0 0
488 2008-12-29 NaN ... 0 0
489 2008-12-30 NaN ... 0 0
490 2009-01-05 1450.0 ... 0 0
欠損値を除いて表示
df = df.dropna()
print(df.head())
# 出力
date open_zenba ... volume_goba value_goba
1 2007-01-05 324000.0 ... 22827 7342975000
2 2007-01-09 320000.0 ... 31357 10375287000
3 2007-01-10 332000.0 ... 20511 6729752000
4 2007-01-11 328000.0 ... 16628 5437101000
5 2007-01-12 329000.0 ... 49509 16530550000
以下の列を追加
open : session=0のopen
high : session=0とsession=1のhighの大きい方
low : session=0とsession=1のlowの小さい方
close : session=1のclose
volume: session=0とsession=1のvolumeの合計
value: session=0とsession=1のvalueの合計
df['open'] = df['open_zenba']
df['high'] = df[['high_zenba', 'high_goba']].max(axis=1)
df['low'] = df[['low_zenba', 'low_goba']].min(axis=1)
df['close'] = df['close_goba']
df['volume'] = df[['volume_zenba','volume_goba']].sum(axis=1)
df['value'] = df['value_zenba'] + df['value_goba'] # こちらの方が直感的かも
print(df.head())
# 出力
date open_zenba ... volume value
1 2007-01-05 324000.0 ... 56245 18166857000
2 2007-01-09 320000.0 ... 60587 19884399000
3 2007-01-10 332000.0 ... 52674 17348477000
4 2007-01-11 328000.0 ... 35222 11552445000
5 2007-01-12 329000.0 ... 77776 25854436000
zenba、goba が含まれていない項目のみ除いて表示
col = [i for i in df.columns if 'zenba' not in i and 'goba' not in i]
print(col)
df = df[col]
print(df.head())
# 出力
date open high ... close volume value
1 2007-01-05 324000.0 326000.0 ... 321000.0 56245 18166857000
2 2007-01-09 320000.0 333000.0 ... 330000.0 60587 19884399000
3 2007-01-10 332000.0 333000.0 ... 328000.0 52674 17348477000
4 2007-01-11 328000.0 331000.0 ... 326000.0 35222 11552445000
5 2007-01-12 329000.0 336000.0 ... 334000.0 77776 25854436000
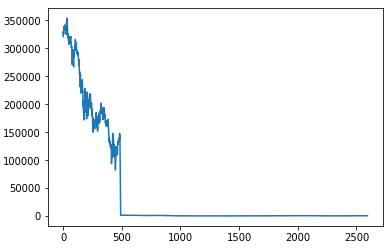
'close'項目のグラフを作成する
plt.plot(df['close'])
plt.show()
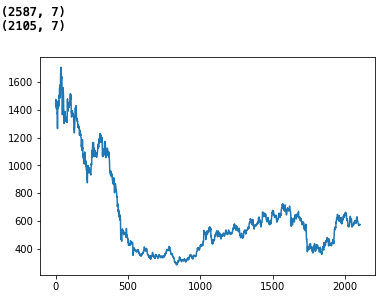
closeの値が50000未満の範囲でグラフを表示
print(df.shape)
df = df[df["close"] < 50000]
df = df.reset_index(drop=True)
print(df.shape)
plt.plot(df["close"])
plt.show()
y項目を追加し、翌日の'open'が当日の'close'より高い場合は'1'低い場合は'0'とする
print((df['close'] - df['open']).head())
print()
print((df['close'] - df['open'] > 0).astype(int).head())
y = list((df['close'] - df['open'] > 0).astype(int))
y = y[1:] + [np.nan]
df['y'] = y
print(df.tail())
# 出力
0 -6.0
1 21.0
2 12.0
3 -10.0
4 -21.0
dtype: float64
0 0
1 1
2 1
3 0
4 0
dtype: int64
date open high low close volume value y
2100 2017-07-31 568.0 574.6 566.5 568.4 15107800 8613256740 1.0
2101 2017-08-01 571.3 577.5 568.4 574.3 14936500 8552405910 0.0
2102 2017-08-02 578.4 579.6 569.1 573.8 10136000 5812332060 1.0
2103 2017-08-03 574.0 574.8 567.2 574.3 9567600 5468152880 0.0
2104 2017-08-04 573.0 574.8 570.4 572.8 8018300 4591509180 NaN
欠損値を除いて表示
print(df.shape)
df = df.dropna()
print(df.shape)
print(df.head())
# 出力
(2105, 8)
(2104, 8)
date open high low close volume value y
0 2009-01-06 1450.0 1454.0 1436.0 1444.0 3377400 4888187300 1.0
1 2009-01-07 1454.0 1482.0 1451.0 1475.0 3653000 5359326000 1.0
2 2009-01-08 1459.0 1482.0 1455.0 1471.0 3269100 4805717900 0.0
3 2009-01-09 1471.0 1486.0 1460.0 1461.0 4637100 6825123700 0.0
4 2009-01-13 1441.0 1442.0 1417.0 1420.0 3908100 5573985800 1.0
先頭9割の行と残り1割の行に分割し、さらに、y列とそれ以外の列(x列)に分割する
その際、4つデータフレームはnumpyのarray型に変換し、y列のarrayは1次元配列に変換する
print(len(df))
threshold = int(len(df) * 0.9)
print(threshold)
x = df[['open', 'high', 'low', 'close', 'volume', 'value']]
y = df[['y']]
print(np.array(x.iloc[:threshold, :])) # train_x
print()
print(np.array(y.iloc[:threshold, :]).flatten()) # train_y
print()
print(np.array(x.iloc[threshold:, :])) # test_x
print()
print(np.array(y.iloc[threshold:, :]).flatten()) # test_y
# 出力
2104
1893
[[1.45000000e+03 1.45400000e+03 1.43600000e+03 1.44400000e+03
3.37740000e+06 4.88818730e+09]
[1.45400000e+03 1.48200000e+03 1.45100000e+03 1.47500000e+03
3.65300000e+06 5.35932600e+09]
[1.45900000e+03 1.48200000e+03 1.45500000e+03 1.47100000e+03
3.26910000e+06 4.80571790e+09]
...
[4.35300000e+02 4.70000000e+02 4.24800000e+02 4.69100000e+02
3.00463000e+07 1.36255238e+10]
[4.65700000e+02 4.72500000e+02 4.59600000e+02 4.68100000e+02
2.77592000e+07 1.29561912e+10]
[4.67900000e+02 4.69800000e+02 4.60200000e+02 4.62000000e+02
1.43791000e+07 6.67774531e+09]]
[1. 1. 0. ... 1. 0. 1.]
[[4.38100000e+02 4.53000000e+02 4.36700000e+02 4.49300000e+02
2.40786000e+07 1.07343711e+10]
[4.39500000e+02 4.42000000e+02 4.29400000e+02 4.32200000e+02
1.48967000e+07 6.45213641e+09]
[4.33000000e+02 4.35800000e+02 4.28600000e+02 4.30600000e+02
1.74649000e+07 7.54749060e+09]
...
[5.71300000e+02 5.77500000e+02 5.68400000e+02 5.74300000e+02
1.49365000e+07 8.55240591e+09]
[5.78400000e+02 5.79600000e+02 5.69100000e+02 5.73800000e+02
1.01360000e+07 5.81233206e+09]
[5.74000000e+02 5.74800000e+02 5.67200000e+02 5.74300000e+02
9.56760000e+06 5.46815288e+09]]
[0. 0. 1. 0. 1. 1. 0. 0. 0. 0. 0. 1. 0. 1. 0. 1. 1. 0. 1. 1. 1. 1. 1. 0.
0. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 0. 1. 1. 0. 0. 1. 1. 0. 1. 1. 1. 1. 1.
0. 1. 0. 1. 1. 1. 1. 0. 1. 0. 1. 1. 1. 1. 0. 1. 1. 1. 0. 0. 1. 0. 1. 0.
0. 1. 0. 1. 1. 0. 0. 1. 1. 1. 1. 0. 0. 1. 0. 1. 1. 1. 1. 0. 0. 1. 1. 0.
1. 0. 0. 0. 0. 0. 1. 1. 0. 1. 1. 0. 0. 1. 1. 1. 0. 1. 1. 0. 1. 0. 1. 1.
0. 1. 0. 1. 0. 0. 0. 0. 0. 0. 1. 1. 0. 1. 1. 1. 0. 1. 1. 1. 0. 1. 1. 1.
0. 1. 0. 1. 0. 0. 1. 0. 1. 0. 0. 1. 1. 0. 0. 0. 1. 0. 0. 0. 1. 1. 1. 0.
1. 1. 1. 1. 0. 1. 1. 0. 0. 1. 0. 0. 0. 1. 0. 1. 1. 0. 1. 1. 0. 1. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 0. 1. 0.]