1.はじめに
名著、**「ゼロから作るDeep Learning2」**を読んでいます。GRU については、この本では付録で紹介していますが、実際に動かす場面は出てきません。せっかくなので今回は、6章でやった様に、BetterRnnlmクラスを使って GRU に PTBデータセットの単語の並び順を学習させ、パープレキシティで学習度合いを測定してみたいと思います。
*実は、common/time_layers.py に GRU と TimeGRU のコードは一応ありますが、分かりやすさを優先した実装のため、BetterRnnlmクラスではそのまま使えません。また、バイアス項も考慮されていません。
2.GRUの実装
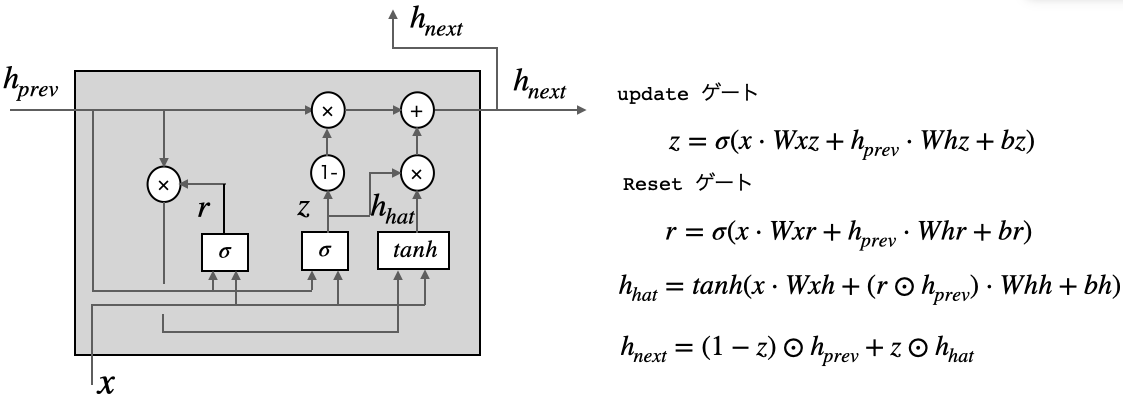
これは、GRUの計算グラフです。LSTMにあった記憶セルはなく、時間方向の伝播は隠れ状態のhだけです。ゲートは、resetゲート と updateゲート の2つです。
resetゲートは、過去の隠れ状態をどれだけ無視するかを決定します。もし、r がゼロであれば、$h_{hat}$は入力のみから決定され、過去の隠れ状態は無視されます。
updateゲートは、LSTM の forgetゲートと inputゲートの2つを兼ねています。forgetゲートとして機能するのは、 $(1-z)\odot h_{t-1}$の部分です。この計算によって、過去の隠れ状態から忘れるべき情報を消去します。
そして、inputゲートとして機能するのは、$z\odot h_{hat}$の部分です。この計算によって、新しく追加する情報について重み付けが行われます。
それでは、実装する前に、重みとバイアスを整理しておきます。
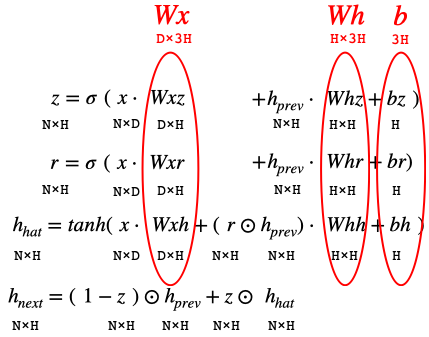
Wxz, Wxr, Wxh をまとめて Wx (D×3H)、Whz, Whr, Whh をまとめて Wh (H×3H)、bz, br, bh をまとめて b (3H)とします。
from common.np import * # import numpy as np (or import cupy as np)
from common.layers import *
from common.functions import softmax, sigmoid
class GRU:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] ###
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
H = Wh.shape[0]
Wxz, Wxr, Wxh = Wx[:, :H], Wx[:, H:2 * H], Wx[:, 2 * H:]
Whz, Whr, Whh = Wh[:, :H], Wh[:, H:2 * H], Wh[:, 2 * H:]
bz, br, bh = b[:H], b[H:2 * H], b[2 * H:]
z = sigmoid(np.dot(x, Wxz) + np.dot(h_prev, Whz) + bz)
r = sigmoid(np.dot(x, Wxr) + np.dot(h_prev, Whr) + br)
h_hat = np.tanh(np.dot(x, Wxh) + np.dot(r*h_prev, Whh) + bh)
h_next = (1-z) * h_prev + z * h_hat
self.cache = (x, h_prev, z, r, h_hat)
return h_next
BetterRnnlmクラスでそのまま扱えるように、パラメータを self.params, 勾配を self.grad という形で取り扱います。個別の値は、H幅で分割すれば良いわけです。
さて、少しややこしい逆伝播です。まず、self.params を分解して各値を取得し、それ以外の状態を cache から復元する部分です。
def backward(self, dh_next):
Wx, Wh, b = self.params
H = Wh.shape[0]
Wxz, Wxr, Wxh = Wx[:, :H], Wx[:, H:2 * H], Wx[:, 2 * H:]
Whz, Whr, Whh = Wh[:, :H], Wh[:, H:2 * H], Wh[:, 2 * H:]
x, h_prev, z, r, h_hat = self.cache
ここから逆伝播を4つの部分に分けて実装して行きます。まず、Tanhと2つのsigmoidと関係のない部分です。
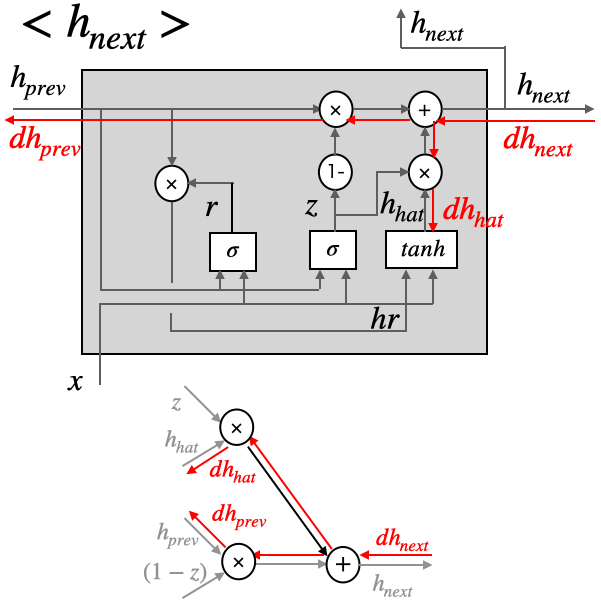
dh_hat =dh_next * z
dh_prev = dh_next * (1-z)
+と×だけの組み合わせなので、シンプルです。続いて、tanh廻りです。
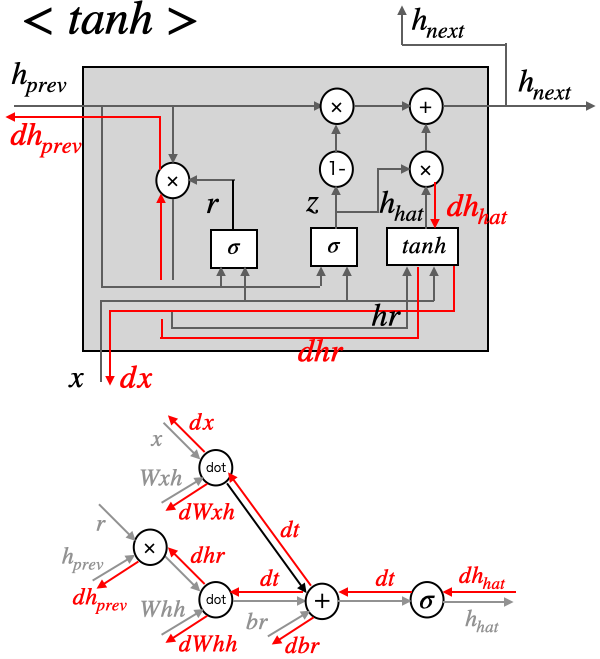
# tanh
dt = dh_hat * (1 - h_hat ** 2)
dbh = np.sum(dt, axis=0)
dWhh = np.dot((r * h_prev).T, dt)
dhr = np.dot(dt, Whh.T)
dWxh = np.dot(x.T, dt)
dx = np.dot(dt, Wxh.T)
dh_prev += r * dhr
dh_prev は、先程計算しているので、ここからは dh_prev += でその結果に加算してゆきます。次に、updateゲートのz廻りです。

# update gate(z)
dz = dh_next * h_hat - dh_next * h_prev
dt = dz * z * (1-z)
dbz = np.sum(dt, axis=0)
dWhz = np.dot(h_prev.T, dt)
dh_prev += np.dot(dt, Whz.T)
dWxz = np.dot(x.T, dt)
dx += np.dot(dt, Wxz.T)
dx は、既にtanhで計算しているので、ここからは dx += で、その結果に加算して行きます。続いて、Resetゲートのr廻りです。
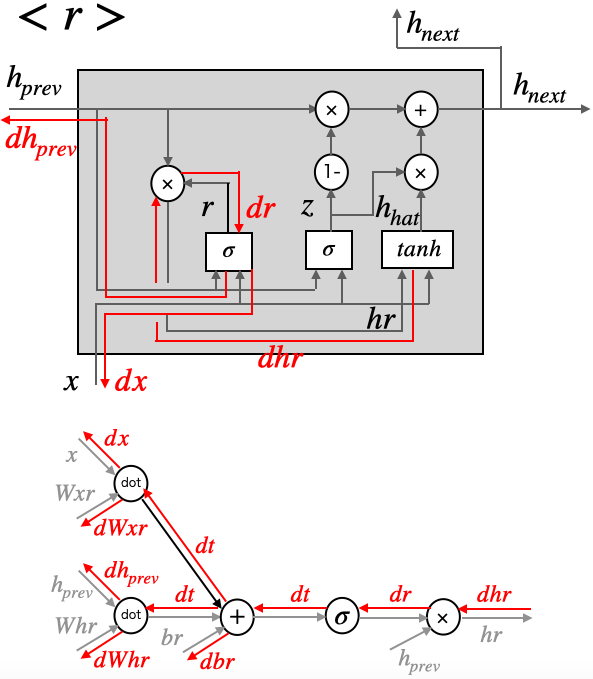
# rest gate(r)
dr = dhr * h_prev
dt = dr * r * (1-r)
dbr = np.sum(dt, axis=0)
dWhr = np.dot(h_prev.T, dt)
dh_prev += np.dot(dt, Whr.T)
dWxr = np.dot(x.T, dt)
dx += np.dot(dt, Wxr.T)
これで各勾配の計算は完了しましたので、gradsにまとめます。
self.dWx = np.hstack((dWxz, dWxr, dWxh))
self.dWh = np.hstack((dWhz, dWhr, dWhh))
self.db = np.hstack((dbz, dbr, dbh))
self.grads[0][...] = self.dWx
self.grads[1][...] = self.dWh
self.grads[2][...] = self.db
return dx, dh_prev
ここまでで、GRUの実装は完了です。
3.TimeGRUの実装
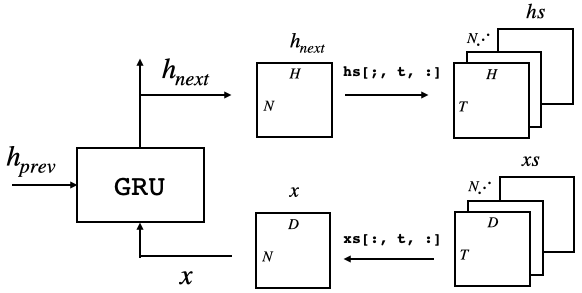
TimeGRU の順伝播は、1時刻毎に、3次元データ xs を切り出して GRU へ入力し、GRU からの出力を再び3次元データ hs にまとめるものです。
class TimeGRU:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.dh = None, None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
H = Wh.shape[0]
N, T, D = xs.shape
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
for t in range(T):
layer = GRU(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
出力を保管する箱 hs (N, T, H)を用意します。また、必要に応じてゼロ行列 self.h (N, H) を用意します。そして、データ xs から1時刻分を切り出して GRU へ入力し、GRUからの出力 self.h を hs に格納して行きます。この時同時に、layerを時刻T分アペンドします(これはbackwardで使います)。
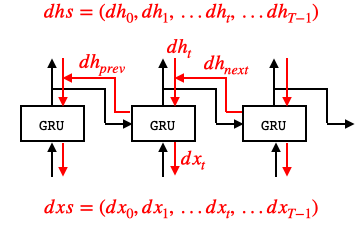
さて、TimeGRUの逆伝播です。逆伝播時は、GRUレイヤに $dh_t+dh_{next}$ が入力されます。
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None
逆伝播の出力を保管する箱 dxs (N, T, D)を用意します。また、勾配を一時保管するリスト grads を用意します。
dhsからの1時刻分の切り出し+ひとつ未来からの勾配dhを入力として、forwardでアペンドしたGRUレイヤを逆順で呼び出してbackwardを掛けます。そして、backwardの結果 dx を dxs へ格納して行きます。
dx, dh = layer.backward(dhs[:, t, :] + dh)の式で、右辺のdhはいわゆる$dh_{next}$、左辺のdhはいわゆる$dh_{prev}$です。
そして、各レイヤでの重みの勾配を加算して行き、最終結果を self.grads にまとめます。
さて、ここまでで、GRU及びTimeGRUの実装が完了しましたので、ch09というフォルダーを作成し、time_layers_gru.pyというファイル名で保存します。
4.better_rnnlmの修正
次に、ネットワークモデルを生成する、better_rnnlm.py を修正します。
import sys
sys.path.append('..')
from common.time_layers import TimeEmbedding, TimeAffine, TimeSoftmaxWithLoss, TimeDropout # 読み込むレイヤを指定
from time_layers_gru import * # GRUだけは、ここから読み込む
from common.np import * # import numpy as np
from common.base_model import BaseModel
class BetterRnnlm(BaseModel):
def __init__(self, vocab_size=10000, wordvec_size=650,
hidden_size=650, dropout_ratio=0.5):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
gru_Wx1 = (rn(D, 3 * H) / np.sqrt(D)).astype('f')
gru_Wh1 = (rn(H, 3 * H) / np.sqrt(H)).astype('f')
gru_b1 = np.zeros(3 * H).astype('f')
gru_Wx2 = (rn(H, 3 * H) / np.sqrt(H)).astype('f')
gru_Wh2 = (rn(H, 3 * H) / np.sqrt(H)).astype('f')
gru_b2 = np.zeros(3 * H).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeDropout(dropout_ratio),
TimeGRU(gru_Wx1, gru_Wh1, gru_b1, stateful=True),
TimeDropout(dropout_ratio),
TimeGRU(gru_Wx2, gru_Wh2, gru_b2, stateful=True),
TimeDropout(dropout_ratio),
TimeAffine(embed_W.T, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.gru_layers = [self.layers[2], self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs, train_flg=False):
for layer in self.drop_layers:
layer.train_flg = train_flg
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts, train_flg=True):
score = self.predict(xs, train_flg)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
for layer in self.gru_layers:
layer.reset_state()
冒頭で、common/time_layers.py からインポートするのは指定したレイヤだけにして、GRUは 先程カレントディレクトリに保存した time_layers_gru.py からインポートする様に変更しています。
あとは、コードのLSTMの部分をGRUに変更します。重みが4つから3つに減りますので、例えば gru_Wx1 = (rn(D, 3 * H) / np.sqrt(D)).astype('f')の中の (D, 3 * H) 様に、重みの数に関係する部分の修正忘れがないようにします。
このコードをch09フォルダに、better_rnnlm_gru.py という名前で保存します。
5.学習用コード
6章の学習用コードを元に、冒頭の from better_rnnlm import BetterRnnlm を from better_rnnlm_gru import BetterRnnlm に変更し、train_better_rnnlm.py というファイル名でch09フォルダに保存します。
ハイパーパラメータ lr = 20 のままで実行したら、初期段階で perplixity のバラツキが大きかったので、 lr = 10 に変更してから再度実行しました。
import sys
sys.path.append('..')
from common import config
# GPUで実行する場合は下記のコメントアウトを消去(要cupy)
# ==============================================
config.GPU = True
# ==============================================
from common.optimizer import SGD
from common.trainer import RnnlmTrainer
from common.util import eval_perplexity, to_gpu
from dataset import ptb
from better_rnnlm_gru import BetterRnnlm # 変更
# ハイパーパラメータの設定
batch_size = 20
wordvec_size = 650
hidden_size = 650
time_size = 35
lr = 10
max_epoch = 40
max_grad = 0.25
dropout = 0.5
# 学習データの読み込み
corpus, word_to_id, id_to_word = ptb.load_data('train')
corpus_val, _, _ = ptb.load_data('val')
corpus_test, _, _ = ptb.load_data('test')
if config.GPU:
corpus = to_gpu(corpus)
corpus_val = to_gpu(corpus_val)
corpus_test = to_gpu(corpus_test)
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
best_ppl = float('inf')
for epoch in range(max_epoch):
trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size,
time_size=time_size, max_grad=max_grad)
model.reset_state()
ppl = eval_perplexity(model, corpus_val)
print('valid perplexity: ', ppl)
if best_ppl > ppl:
best_ppl = ppl
model.save_params()
else:
lr /= 4.0
optimizer.lr = lr
model.reset_state()
print('-' * 50)
# テストデータでの評価
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('test perplexity: ', ppl_test)
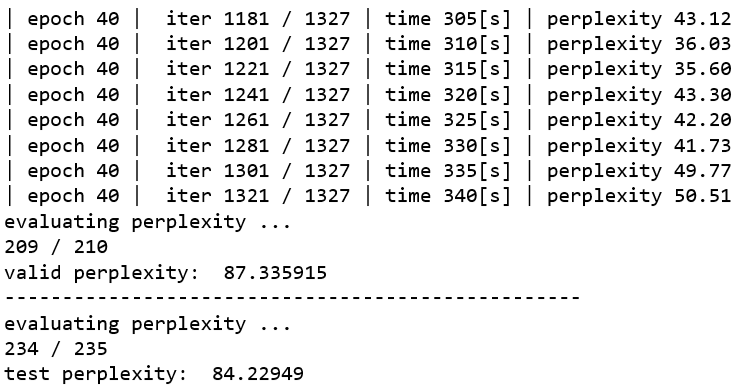
6章のLSTMモデルの test perplexity は70台後半でしたが、GRUモデルでは80台前半に留まるようです。今回のデータセットの様に、90万語を超える長いコーパスの場合は、メモリセルを持ったLSTMモデルの方が有利な様です。