1.はじめに
Python機械学習プログラミング[第2版] という本を買って勉強を始めました。効果的な学習を進める為には、勉強した内容をアウトプットするのが効果的ということで、今後勉強した内容を備忘録の形でここに残して行きたいと思います。
なお、本ではコードを一部 jupyter notebook形式で記載しているようですが、ここでは.py形式でも実行できるような形式で記載したいと思います。
ということで、今回は第2章のパーセプトロンから。
2.パーセプトロンのトレーニング
まず、パーセプトロンのトレーニングということで、テキストに載っているコードはこんな形
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# クラス Perceptron
class Perceptron(object):
# コンストラクタ
# 引数の指定がない場合は、デフォルトの eta=0.01, n_iter=50, trandom_state=1 を採用
def __init__(self, eta=0.01, n_iter=50, random_state=1):
self.eta = eta # 学習率
self.n_iter = n_iter # 学習回数
self.random_state = random_state # 乱数発生のキー数字
def fit(self, X, y):
# self.w_ の初期化
# self.w_ に、self.random_state=1、正規分布、平均0、標準偏差0.01、出力数3 のランダム配列を代入
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
# 推移を記録するリストを初期化
self.errors_ = []
# 学習ループ
for _ in range(self.n_iter):
errors = 0
# 目標値と予測の差を元に、重みをアップデート
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi)) # アップデートは学習率×差
self.w_[1:] += update * xi # 重み w_の2,3番目をアップデート
self.w_[0] += update # 重み w_の1番目をアップデート
errors += int(update != 0.0) # updateが0でなければerrorsを+1
self.errors_.append(errors) # 1Epoch毎にerrorsを記録
return self
# 総入力の計算
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
# 予測結果を返す
def predict(self, X):
# 総入力が0以上なら1、そうでなければ-1を返す
return np.where(self.net_input(X) >= 0.0, 1, -1)
# iris データセットの読み込みと加工
df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/iris/iris.data', header=None)
print(df.tail()) # データセットの最終5行を表示
y = df.iloc[0:100, 4].values # yに最初100行の4列目の値をセット
y = np.where(y == 'Iris-setosa', -1, 1) # yが'Iris-setosa'なら-1、そうでなければ1
X = df.iloc[0:100, [0, 2]].values # Xに最初100行の0列目と2列目の値をセット
# 散布図の表示
plt.scatter(X[:50, 0], X[:50, 1], # 最初50行のX[0]とX[1]をプロット
color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], # 次の50行のX[0]とX]1]をプロット
color='blue', marker='x', label='versicolor')
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.show()
# 学習とerrorsのグラフ表示
ppn = Perceptron(eta=0.1, n_iter=10) # クラスPerceptronをインスタンス化
ppn.fit(X, y) # 学習(fitメソッドを実行)
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o') # errors_ をグラフ化
plt.xlabel('Epochs')
plt.ylabel('Number of updates')
plt.show()
実行結果は、こうなります。
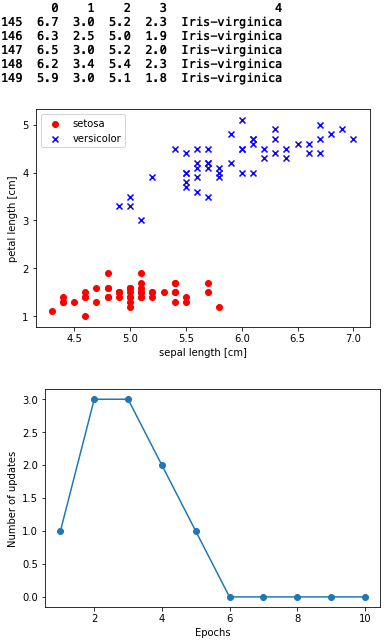
データフレームは、150行、4つの特徴量と1つの種類から成っています。
4つある特徴量の内、実際に使っているのは、0列目と2列目の2つ。
散布図をみると、setosa と versicolor の2つの要素は、混在することはなく、分類は割と簡単そうですね。
errorsのグラフをみると、6Epochsで Number of uppdates=0 となり収束しています。
ここで、学習毎にアップデートされる重みはどんな推移なのか知りたくなりました。
その為に、コードを改造します。
まず、def fit(self, X, y):の部分に、重みの推移を記録する部分を追加します。
def fit(self, X, y):
# self.w_ の初期化
# self.w_ に、self.random_state=1、正規分布、平均0、標準偏差0.01、出力数3 の配列を代入
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1 + X.shape[1])
# 推移を記録するリストを初期化
self.errors_ = []
self.w0_ = [] # 追加
self.w1_ = [] # 追加
self.w2_ = [] # 追加
# 学習ループ
for _ in range(self.n_iter):
errors = 0
# 目標値と予測の差を元に、重みをアップデート
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi)) # アップデートは学習率×差
self.w_[1:] += update * xi # 重み w_の2,3番目をアップデート
self.w_[0] += update # 重み w_の1番目をアップデート
errors += int(update != 0.0) # updateが0でなければerrorsを+1
self.w0_.append(self.w_[0]) # 追加
self.w1_.append(self.w_[1]) # 追加
self.w2_.append(self.w_[2]) # 追加
self.errors_.append(errors) # 1Epoch毎にerrorsを記録
return self
そして、コードの最後に、重みのアップデートの推移をグラフ化する部分を追加し、コードを実行して見ます(表示するのは、収束グラフと重みの推移グラフのみです)。
# 重みの推移グラフ表示(追加)
plt.plot(range(1, len(ppn.w0_)+1), ppn.w0_, label='w0_')
plt.plot(range(1, len(ppn.w1_)+1), ppn.w1_, label='w1_')
plt.plot(range(1, len(ppn.w2_)+1), ppn.w2_, label='w2_')
plt.xlabel('iter')
plt.ylabel('value')
plt.legend()
plt.show()
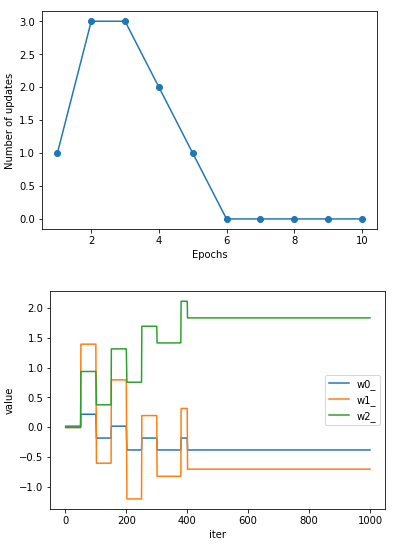
重みの推移グラフを見てみましょう。縦軸が重みの値(value)、横軸が学習回数(iter)で、学習回数100 iterで1 Epochsです。
なんか、ほとんど 50 iter毎にしか重みがアップデートされていないようです。
なぜか?今さらながら、dfを見てみると、
print(df)
# 出力
0 1 2 3 4
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
10 5.4 3.7 1.5 0.2 Iris-setosa
11 4.8 3.4 1.6 0.2 Iris-setosa
12 4.8 3.0 1.4 0.1 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
14 5.8 4.0 1.2 0.2 Iris-setosa
15 5.7 4.4 1.5 0.4 Iris-setosa
16 5.4 3.9 1.3 0.4 Iris-setosa
17 5.1 3.5 1.4 0.3 Iris-setosa
18 5.7 3.8 1.7 0.3 Iris-setosa
19 5.1 3.8 1.5 0.3 Iris-setosa
20 5.4 3.4 1.7 0.2 Iris-setosa
21 5.1 3.7 1.5 0.4 Iris-setosa
22 4.6 3.6 1.0 0.2 Iris-setosa
23 5.1 3.3 1.7 0.5 Iris-setosa
24 4.8 3.4 1.9 0.2 Iris-setosa
25 5.0 3.0 1.6 0.2 Iris-setosa
26 5.0 3.4 1.6 0.4 Iris-setosa
27 5.2 3.5 1.5 0.2 Iris-setosa
28 5.2 3.4 1.4 0.2 Iris-setosa
29 4.7 3.2 1.6 0.2 Iris-setosa
.. ... ... ... ... ...
120 6.9 3.2 5.7 2.3 Iris-virginica
121 5.6 2.8 4.9 2.0 Iris-virginica
122 7.7 2.8 6.7 2.0 Iris-virginica
123 6.3 2.7 4.9 1.8 Iris-virginica
124 6.7 3.3 5.7 2.1 Iris-virginica
125 7.2 3.2 6.0 1.8 Iris-virginica
126 6.2 2.8 4.8 1.8 Iris-virginica
127 6.1 3.0 4.9 1.8 Iris-virginica
128 6.4 2.8 5.6 2.1 Iris-virginica
129 7.2 3.0 5.8 1.6 Iris-virginica
130 7.4 2.8 6.1 1.9 Iris-virginica
131 7.9 3.8 6.4 2.0 Iris-virginica
132 6.4 2.8 5.6 2.2 Iris-virginica
133 6.3 2.8 5.1 1.5 Iris-virginica
134 6.1 2.6 5.6 1.4 Iris-virginica
135 7.7 3.0 6.1 2.3 Iris-virginica
136 6.3 3.4 5.6 2.4 Iris-virginica
137 6.4 3.1 5.5 1.8 Iris-virginica
138 6.0 3.0 4.8 1.8 Iris-virginica
139 6.9 3.1 5.4 2.1 Iris-virginica
140 6.7 3.1 5.6 2.4 Iris-virginica
141 6.9 3.1 5.1 2.3 Iris-virginica
142 5.8 2.7 5.1 1.9 Iris-virginica
143 6.8 3.2 5.9 2.3 Iris-virginica
144 6.7 3.3 5.7 2.5 Iris-virginica
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
[150 rows x 5 columns]
そうでした! 150個あるデータは、最初の50個はIris-setona、次の50個はIris-versicolor、最後の50個がIris-virginica、と同じ種類のデータが固まっているので、このデータをそのまま学習に使うとほとんど50個置きにしかアップデートがされないようです。
そうであれば、データをシャッフルすると、収束が早くなるかもしれません。
その為に、データセットの読み込みと加工の部分にシャッフル機能を追加します。
# iris データセットの読み込みと加工
df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/iris/iris.data', header=None)
print(df.tail()) # データセットの最終5行を表示
# ------------------------------------------ 追加 ↓
df = df.iloc[0:100, :] # 最初の100行のみを抽出
df = df.sample(frac = 1, random_state = 10) # 全体をranndom_state=10でシャッフルする
print(df) # シャッフルしたデータセットを表示
# ------------------------------------------ 追加 ↑
y = df.iloc[0:100, 4].values # yに最初100行の4列目の値をセット
y = np.where(y == 'Iris-setosa', -1, 1) # yが'Iris-setosa'なら-1、そうでなければ1
X = df.iloc[0:100, [0, 2]].values # Xに最初100行の0列目と2列目の値をセット
pandasのデータフレームをシャッフルするには、sample()がおすすめです。()の引数で元データからどうランダムに抽出するかの方法を指定できます。fracで割合(1で100%)、nで個数、random_stateでシード指定など。なお、fracとnはどちらか片方しか指定できません。
あと、これに伴い散布図の表示(最初の50行をsetosa、次の50行をversicolorとしている)のところを改造します。
# 散布図の表示
# -------------------------------------------- 改造 ↓
setosa_x, setosa_y, versicolor_x, versicolor_y = [], [], [], []
for i in range(len(X)):
if y[i] == -1:
setosa_x.append(X[i, 0])
setosa_y.append(X[i, 1])
else:
versicolor_x.append(X[i, 0])
versicolor_y.append(X[i, 1])
plt.scatter(setosa_x, setosa_y,
color='red', marker='o', label='setosa')
plt.scatter(versicolor_x, versicolor_y,
color='blue', marker='x', label='versicolor')
# -------------------------------------------- 改造 ↑
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.show()
さあ、これでコードを実行してみます(表示するのは、収束と重みの推移グラフのみです)
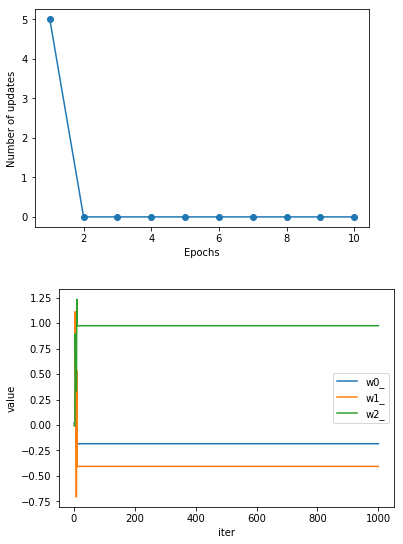
凄い!シャッフルの効果絶大です。2Epochsで収束しました。
3.パーセプトロン決定領域の可視化
最初、本を読んでも分かり難かったので、まず課題を単純化して、本のコードを参考に自分なりにコードを色々試してみました。その結果、やっと腹に落ちたので、その内容を書いてみます。
(課題)
・グリッドは、x軸[0 1 2 3 4 5]、y軸[0 1 2 3 4 5]とし、領域判定するマス目は6×6=36個だけとする。
・予測関数は、y >= 1/2*x +1 が成り立つ時1、成り立たない時-1とする。
・36個のマス目毎に予測関数を使って1か-1かを判定する。
・判定結果を元に、領域の塗り分けを行う。
import numpy as np
import matplotlib.pyplot as plt
# 予測関数 ( xi, yiの予測結果を1次元の配列で返す)
def pred(xi, yi):
xi_ = xi.ravel() # xiを1次元配列に変換
yi_ = yi.ravel() # yiを1次元配列に変換
z = [] # 予測結果を収めるリスト
for x, y in zip(xi_, yi_):
if y >= 1/2 * x + 1:
z.append(1) # Trueならzに 1を格納
else:
z.append(-1) # Falseならzに -1を格納
return np.array(z) # 1次元の配列にして返す
# グリッドの作成
x = np.arange(0, 6, 1) # [0 1 2 3 4 5]
y = np.arange(0, 6, 1) # [0 1 2 3 4 5]
xi, yi = np.meshgrid(x, y) # グリッドのx座標がxiに、y座標がyiに入る
print(xi)
print()
print(yi)
print()
# 各グリッドの予測
z = pred(xi, yi) # 予測関数を呼び出して、予測結果をzに納める
print(z)
print()
zi = z.reshape(xi.shape) # 配列の形をxiと同じ形に変換
print(zi)
# 領域の塗り分け
plt.contourf(xi, yi, zi, alpha=0.3, colors=['red','blue'])
plt.show()
このコードを実行すると、まず np.meshgrid() の結果が出ます。

これはグリッドのx座標のみの値(xi)。全部で6×6=36個あります。

そして、これはy座標のみの値(yi)。これも全部で6×6=36個あります。
そうなんです、np.meshgrid()は、X軸とY軸のデータからグリッドの座標を生成するだけ。そして、その座標はx座標とy座標に分けて生成するんですね。
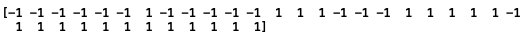
そして、これが各グリッドが1なのか-1なのか予測した結果。判定結果は、36個ありますが、xiやyiと形が違いますね。

なので、xiと同じ形(6×6)にリシェイプして、こんな形にします。
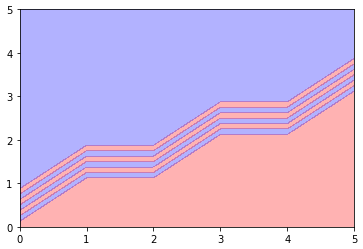
そして、これが領域をペイントした結果です。グリッドがものすごく荒いので、2つの領域の境界線が変ですが、
グリッドの作成の時に、もっと生成するピッチを細かくしてやれば問題ありません。
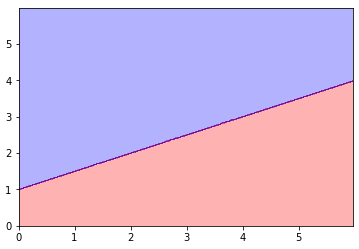
x = np.arange(0, 6, 1) → np.arange(0, 6, 0.02) とかすると(yの方も同様)ちゃんとした形になります。

まとめると、この3つの配列をセットにして、plt.contourf()を使うと、領域の塗り分けができるわけです。
最初は、2つの種類を分類する線を引いてから、塗り分けるのかと思っていたのですが、違います。
設定したグリッド1つ1つを予測し、予測結果によってグリッド1つ1つを塗り分け、結果として2つの種類を分類する線の様なものが引かれた様に見えるということです。
さて、本に載っているコードを動かしてみましょう。
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))]) # len(np.unique(y)) = 2
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 # x軸の最小、最大を設定
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 # y軸の最小、最大を設定
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), # xx1にx座標を取得
np.arange(x2_min, x2_max, resolution)) # xx2にy座標を取得
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) #ravel()で1次元に変換して、予測
Z = Z.reshape(xx1.shape) # Z(1次元)をxx1と同じシェイプに変換
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap) # x座標、y座標、それに対応した予測値で領域を塗り分け
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)): # np.unique(y)=[-1, 1]
plt.scatter(x=X[y == cl, 0], # y == clの場合のX[0]全部
y=X[y == cl, 1], # y == clの場合のX[1]全部
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=cl,
edgecolor='black')
plot_decision_regions(X, y, classifier=ppn)
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.show()
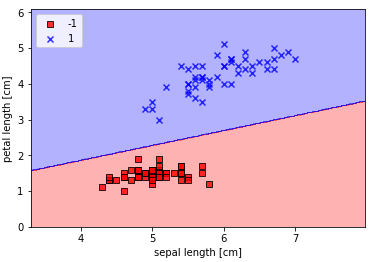
ということで、領域の塗り分けグラフができます。ちょっと変数名の付け方に文句があるのですが、y軸の座標を納めている配列なのに、xx2とかやめて貰えませんかね。初学者を迷わせます(笑)。
ところで、主題とは違うのですが、実は私別のところに興味が。。。。
# plot class samples
for idx, cl in enumerate(np.unique(y)): # np.unique(y)=[-1, 1]
plt.scatter(x=X[y == cl, 0], # y == clの場合のX[0]全部
y=X[y == cl, 1], # y == clの場合のX[1]全部
alpha=0.8,
c=colors[idx],
marker=markers[idx],
label=cl,
edgecolor='black')
これって、前半で私が改造した内容そのものを、実にエレガントに処理しているではありませんか!
x = X[y == cl, 0] とやると、xはy == clが成り立つX[0]全部になるんですね。そして、colorとかmarkerとかの種類を事前に設定しておくと、plt.scatter()の式が1つで複数の散布図が描けてしまうわけです。
素晴らしい!!!
えっ? そんなの当たり前だって? こりゃまた、失礼しました〜!
では、また。