XiaoIceの基本的な構造を理解
Xiaolceの解説記事はすでにありますが、自己の理解のために書きなぐっていきます。間違ってたらすみません。
元になった論文はこちら→https://arxiv.org/abs/1812.08989
XiaolceはMicrosoftが開発しているチャットボットで、五カ国展開されており、日本語版がりんなです。
Xiaolceの目的として、長期的で感情的なつながりを形成するため、人間の感情と状態を動的に認識し、ユーザの意図を理解し、長い会話を通してユーザニーズに応答することとしています。そのため、会話ターン数(CPS)というもので評価しています。これはあるセクションにおける会話の数で、XiaoIceは平均CPSが23に達しています。ちなみに、りんなのCPSは19らしいです。
実装
チャットボットには何が必要でしょうか?人間との自然な対話には、IQとEQが必要です。
IQは、知識と記憶のモデル化、画像と自然言語の理解、推論、生成、予測などで、EQは共感とソーシャルスキル(クエリの理解、ユーザのプロファイリング、感情検出、感情認識、会話中のユーザの気分)のことです。
またそれだけではなく、パーソナリティ(性格)も一貫した性格である必要があります。そのため、数百万人のユーザーの人間の会話を収集し、望ましいユーザー(若い女性ユーザー)を抽出して使用しているそうです。XiaoIceは18歳の少女をデザインしているらしい。
評価方法は先程述べた、会話ターン数(CPS)を用いて、CPSが大きければ大きいほど、会話が長く続き、ボットとの関わりが深いと言えます。また、「わかりません、どういう意味ですか?」のような平凡的な答えはCPSを下げる(進んで話しかけるユーザーはほとんどいないため)要因になるそう。
設計の方向性はCPSを長期化することで、トップレベルのプロセスが、多様な会話モード(気軽なチャット、質問への回答やチケットの予約などの対話スキル)を選択して、低レベルのプロセスが実際の処理を担当するような設計になっています。
実装詳細
3つの層により構成されているようです。順に説明していきます。
User experience layer:
ユーザーからの入力を受ける層です。音声とチャットがあり、チャットには画像解析、テキストの正規化や、音声には音声認識や合成、ノイズを識別したり、ユーザの年齢、性別や、他の人と話しているかどうかを識別するための分類器が含まれます。
Conversation engine layer:
この層は会話の中枢で、Dialogue Manager、Empathetic computing、Core Chat、対話スキルで構成されます。
Dialogue Managerは、対話状態を追跡して対話スキル、Core Chatのいずれかを選択します。
Empathetic computingは、ユーザ入力の内容や、ユーザの共感(例:感情、意図、話題に対する意見、ユーザーの背景や一般的な関心)も理解するように設計することで、いわゆるEQを発揮します。IQはCore Chatや対話スキルで示されます。
Data layer:
ユーザーの情報を保存する一連のデータベースです。
Conversation engine layerの詳細
Conversation engine layerは4つの主要コンポーネント (Dialogue Manager、Empathetic computing、Core Chat、対話スキル)により構成されます。
Dialogue Manager:
対話状態を追跡するGlobal State Tracker、話題を選択するDialogue Policyから構成。応答は、対話スキルかコアチャットのいずれかです。
Global State Tracker: 対話の状態を追跡するための作業メモリを保持。作業メモリは、各対話の開始時には空で、各対話時に後ほど説明するEmpathetic Computingの情報を保存します。内容はベクトルにエンコードされます。
Dialogue Policy: 話題を選択する。一連のトリガーを使用して実装され、トリガのいくつかは、Topic Managerなどの機械学習モデルを使用。その他はルールに基づいており、キーワードによって話題を誘発するものもある。
また、ユーザ入力がテキストのみの場合、Core Chat が起動。Topic Managerは特定のトピックやドメインに対するユーザの関心が検出された場合に、新しいトピックに切り替えるか、対話スキルから特定のスキルに切り替えるかを決定する。ユーザ入力がイメージやビデオクリップの場合は、画像認識のスキルがアクティブになります。
Topic Manager: 話題を切り替えるかどうかを各対話ターンで決定するための分類子と、新しい話題を提案するための話題推薦エンジンから構成される。話題の切り替えは会話に参加できない場合、ユーザが退屈している場合(例えば“OK”, “I see”, “go on”.など)にトリガーされる。話題の判定にはアメリカのInstagramなどから人気トピックスと関連コメントと議論を収集したデータセットを使用して学習。話題の選択には、関連性、新鮮さ、ユーザーの興味、人気、ユーザーの受け入れやすさなどを考慮。これらによりCPSを0.5上昇させた。
Empathetic computing:
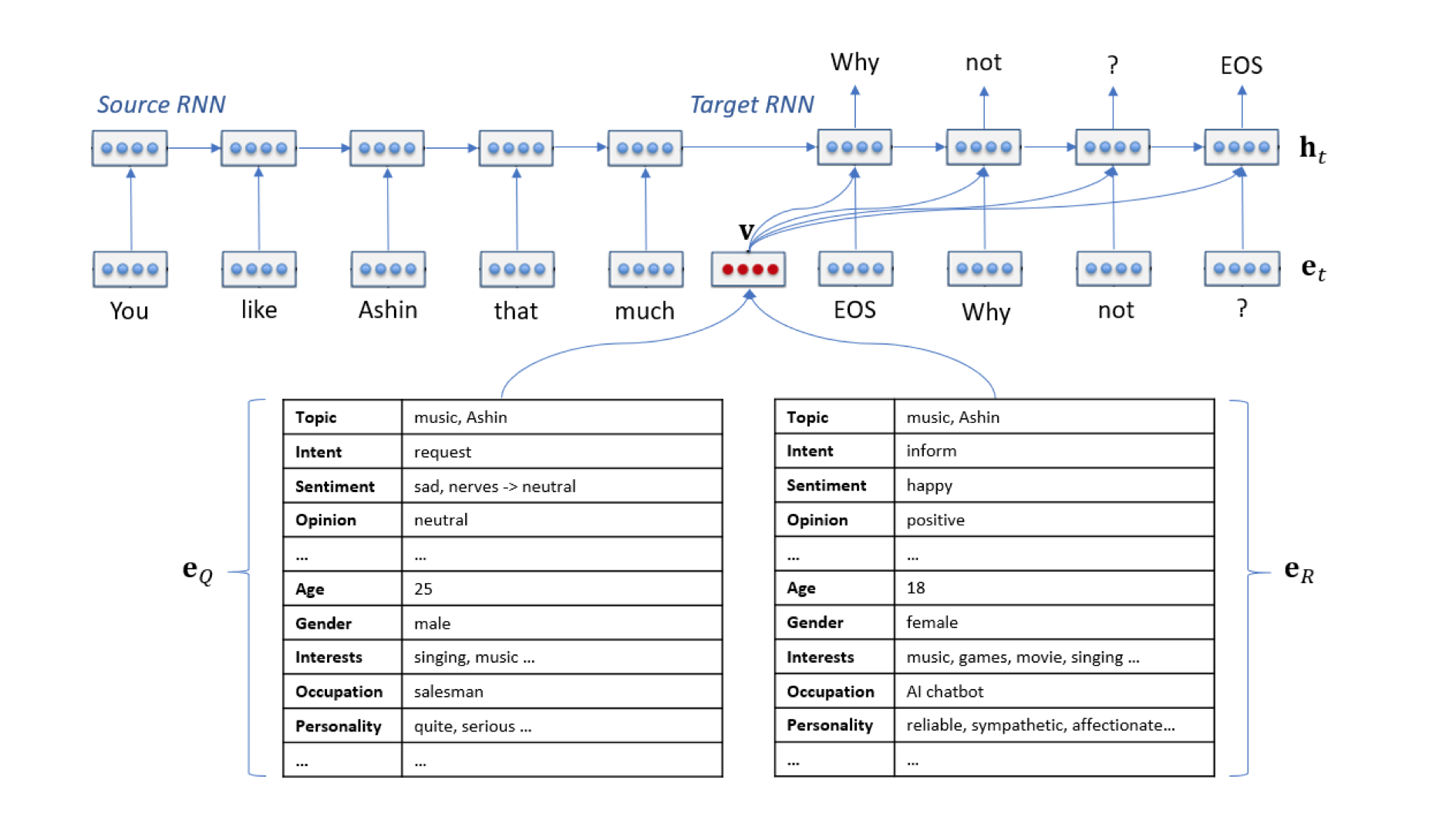
ユーザの感情や状態、どのように返答するかなどを出力します。Qはユーザーの入力。eQは会話におけるユーザの感情および状態をエンコードしたもの。Rはユーザの応答。eRは感情を指定した応答を指示情報。この(Q,eQ,R,eR)を出力して、Core Chatなどに入力させる。
これを行うため、contextual query understanding、 user understanding、 interpersonal response generationの3つのコンポーネントから構成。
contextual query understanding: Qを変換。まず、Qをラベル付けして作業メモリに保管、代名詞があれば実体名に、不完全な文の場合はコンテキスト情報を用いて完全な文として保存。
user understanding: eQを生成。eQは話題の検出、対話タイプ(挨拶、要求、通知などの11種類)、 感情(5つの感情)、トピックに対するユーザの反応(ポジネガ)、利用者のプロフィール(年齢、興味、職業、パーソナリティなど)などをエンコードしたもの。
interpersonal response generation: eRを作成。例えば、「同じ話題」で、「楽しい」感情で「ポジティブ」な「意見」を応答するなどの指示。具体的な値はeQの中から導き出される。ヒューリスティックに行われるとあったが、どのように指示を作成するのか明記されていない。
Core Chat:
Empathetic Computing と共に、テキスト入力を受け取り、出力として応答を生成することで、基本的なコミュニケーション機能を提供する機能。Core Chat は、General ChatとDomain Chatの2つの部分で構成される。General Chatは、広い範囲の話題をカバーするオープンドメインの会話。Domain Chatは、音楽、映画、有名人など特定のドメインについての対話。General ChatとDomain Chatは、データベースが異なるだけのようです。
応答生成には、XiaoIceの性格に適合するインターネットから収集した共感的な応答を含む人間の会話やニュース記事やレポートから抽出した文を、データベースから検索する検索ベースの方法と、RNN(GRU)によって応答を生成する生成ベースの方法があり、各生成された文章をランク付けして最終的な応答を決定しています。
検索ベースの方法は機械学習に基づくキーワード検索と意味検索を使って、400件までの回答候補を検索します。検索は、対話コンテキストから抽出した情報、ウェブページとウェブサイトのメタデータやユーザプロファイルに基づき検索されるようです。
生成ベースの方法では、先程のeQやeRを直接入力して生成しているようです(図)。
 (The Design and Implementation of XiaoIce, an Empathetic Social Chatbot より引用)
(The Design and Implementation of XiaoIce, an Empathetic Social Chatbot より引用)
ランク付けでは一貫性や共感性、検索一致性(BM25やTFIDFスコア)を0〜3でランク付けして、高いランクのものが応答に使用されると思われます。ランク付けでは機械学習を用いている模様。各ランクは以下の通り:
- 0: 応答が共感的でないか、クエリにあまり関連しない
- 1: 応答は受け入れ可能であり、クエリに関連。
- 2: XiaoIceの性格に適合し、ユーザを楽しくさせる共感的で人間的な反応
Editorial Response: 障害やタイムアウトで有効な応答を生成できない場合、“Hmmm, difficult to say. What do you think?”, or “let us talk about something else”.「うーん、難しいですね。どう思いますか?」や「何か他のことを話しましょう」のように応答。
対話スキル:
230個あるらしいです。特定の条件で発動します。例えば、食品の画像や天気、ユーザーがネガティブな感情の時など。複数のスキルが同時に発動する場合は、事前に定義された優先順位などで決定するそうです。なお、異なるスキルを頻繁に切り替えることは避けているそうです。代表的なTask Completion、Deep Engagement、Content Creationの3つのスキルは
Content Creation: ラジオを作れる(録音できる?)機能など
Deep Engagement: 特定のトピックや設定(数学や歴史、食べ物、旅行、有名人)、画像の食品のカロリーやタンパク質などの栄養情報を提示したりもできる。
Task Completion: アメリカの人口や、「北京の天気はどうですか」などの質問に答えたり、スマートデバイスコントロールのスキルもある。
などがあるそうです。画像認識のスキルは省略します。
まとめ
チャットの部分では生成モデルだけでなく、検索ベースの方法も用いているのがおどろきでした。細かいところはわからなかったので今後解説していきたいです。