背景
自分が携わっているプロダクトの評判を機械的に分析できないかと思い、自アカウントでAWS Comprehendを使った自動分析の仕組みを作ってみました。
分析に関しては他にも多数の方法があると思いますが、自分の興味があるものを使ってみたかったので、とりあえず色々使って実装を目指しました。
環境
実行環境
| 項目 | 環境 |
|---|---|
| マシン | Amazon EC2 (t2.medium) |
| OS | AmazonLinux2 (4.14.47-63.37.amzn2.x86_64) |
| 言語 | Python 3.7.0b3 |
利用したサービス・ソフトウェア
| 項目 | 環境 |
|---|---|
| ツイート検索 | Twitter API |
| 翻訳 | GCP Translate API |
| 分析 | AWS Comprehend |
| データ保存 | MariaDB |
| 可視化 | Superset |
[NOTE] なぜ翻訳?
分析対象となるツイートのほとんどは日本語になるのですが、Comprehendが日本語には未対応なのです…。(ちなみにAWS Translateも。)
なので、分析の精度はComprehendもさることながら、GCPのTranslate APIに大きく依存しています。
(正直、全部うまく動いてもただの参考値にしかならないでしょう…。)
処理フロー
ざっとこんな感じのフローで実装を目指します。
- ツイート取得 … Twitter APIを使って、分析対象のツイートを取得。
- ツイート英訳 … Translate APIを使って、取得したツイートを英訳。
- 感情分析 … AWS Comprehendを使って、英訳したツイートを分析。
- 可視化 … Supsersetを使って、分析結果を可視化。
よし、やってみましょう。
実装
1. ツイート取得
以下のページを参考に、実装させていただきました。
http://testpy.hatenablog.com/entry/2017/11/05/012906
Search APIのパラメータは以下を指定することにしました。
| 項目 | 値 |
|---|---|
| q | filterなど定義できるザ・検索パラメータ。今回は単純な文字列のみを指定しますが、後から変えられるように設計情報としてDBに持たせます。 |
| count | 取得件数。MAX100件なので、これも設計情報としつつ、とりあえず100。(英訳・分析APIのオンデマンド料金がはっきりするまでびびって5件にしていた…。) |
| lang | 言語。最初は指定していなかったのですが、英単語系のキーワードだと国外の関係ないツイートがひっかかってしまうので、明示的に'ja'を指定。 |
表中に書いた通り、この検討を始めたところから色々外部定義したくなったので、まじめにデータベース設計をしてみました。
ツールはA5:SQL Mk-2を使用。保存するだけなので、めんどくさいリレーションは無しです。
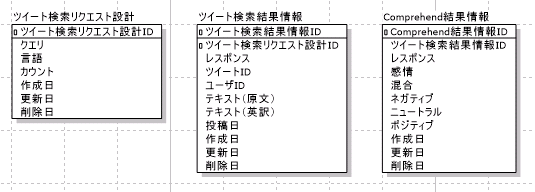
この後、Supsersetの都合でVIEWも作ったんだけど、VIEWの書き方がわからない気配があったので、べた書き。
CREATE VIEW
v_tweet_comprehend_view
(
tweet_search_result_info_id,
tweet_search_req_sekkei_id,
response,
tweet_id,
user_id,
origin_text,
en_text,
created_at,
comp_response,
sentiment,
mixed,
negative,
neutral,
positive
)
AS
SELECT
T.tweet_search_result_info_id,
T.tweet_search_req_sekkei_id,
T.response,
T.tweet_id,
T.user_id,
T.origin_text,
T.en_text,
T.created_at,
C.response,
C.sentiment,
C.mixed,
C.negative,
C.neutral,
C.positive
FROM
t_tweet_search_result_info AS T
LEFT JOIN
t_comprehend_result_info AS C
ON
T.tweet_search_result_info_id=C.tweet_search_result_info_id
;
タプル形式で変なところにカンマが必要とか、fetchしないとrowcountとれないとか、早速python相手に苦戦しました。
(お目汚しになるので、ソースは基本割愛でいきます。)
2. ツイート英訳
初・GCP利用!
クレカ登録してアカウントを開設しました。チュートリアルを見ながら難なく疎通完了。
https://cloud.google.com/translate/docs/getting-started?csw=1
Credentialsのexport方法がAWSほど親切じゃありませんでした。
OSでexportはスマートじゃなさ過ぎたのでコード内でexportすることにしています。
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "/data/scripts/python/gcp_2c7504f8d560.json"
ちなみに、この記事を書くまでに28,094文字を英訳させた結果、いくらかかったかと言うと…

無料枠、万歳!!
※無料枠じゃなかったとしても61.41円しかかかっていないです。
3. 感情分析
ここまでの実装から、python部分は特に困ることなく疎通完了。
Tokyoリージョンには無いのでVirginiaを使いました。
ComprehendのAPIも色々ありますが、今回はSentimentを分析してもらいます。
https://docs.aws.amazon.com/comprehend/latest/dg/API_DetectSentiment.html
レスポンスはこんな感じです。
{
"ResponseMetadata": {
"HTTPHeaders": {
"connection": "keep-alive",
"content-length": "164",
"content-type": "application/x-amz-json-1.1",
"date": "Sun, 01 Jul 2018 07:49:24 GMT",
"x-amzn-requestid": "45ad76ba-7d03-11e8-8111-abc13f7a6a3f"
},
"HTTPStatusCode": 200,
"RequestId": "45ad76ba-7d03-11e8-8111-abc13f7a6a3f",
"RetryAttempts": 0
},
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.006736680865287781,
"Negative": 0.010852526873350143,
"Neutral": 0.30181267857551575,
"Positive": 0.6805981397628784
}
}
この例で食わせたのは"It is sunny."という文章でした。
確かにPositiveだけど、晴れが嫌いな人も1%はいるぞ、っていう結果だと思えばいいのだろうかw
解析結果を見るとわかりますが、このSentiment、全部で4種類あるのですがmixedだけ意味がよく分からない。
"複雑だったので、解析できませんでした度"なのか、ちゃんと解析できたうえで"この文章の複雑な感情度"なのか、どっちだろうか…。
なお、こちらも料金は良心的で今のところ$0です。
が、無料枠で利用しているっぽい?ちょっと油断したら危険かもしれません。
1~3.のフィージビリティ
ここまで考えたところで、どの程度の結果が得られるのか、手でやってみました。
1. ツイート取得
とある人のツイートをサンプルで利用します。
携帯の壁紙を自キャラにしてからというもの、ふと携帯を開いた瞬間に可愛くてびっくりするわ
うん、よくある話です。わかります。
2. ツイート英訳
Something called mobile wallpaper as your character, suddenly surprised at the moment you opened the cell phone
お、それっぽい!?
…あれ、"可愛くて"って情報欠落してね…??
3. 感情分析
不安しかないですが、どうなるか見てみましょう。
{
"ResponseMetadata": {
"HTTPHeaders": {
"connection": "keep-alive",
"content-length": "160",
"content-type": "application/x-amz-json-1.1",
"date": "Sun, 01 Jul 2018 08:10:55 GMT",
"x-amzn-requestid": "475b202f-7d06-11e8-9eb4-25d6c7a48f6b"
},
"HTTPStatusCode": 200,
"RequestId": "475b202f-7d06-11e8-9eb4-25d6c7a48f6b",
"RetryAttempts": 0
},
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.005975686013698578,
"Negative": 0.1334427446126938,
"Neutral": 0.7641383409500122,
"Positive": 0.0964432880282402
}
}
え、Neutralですか…。
思った通り、自動英訳の過程でかなり問題が仕込まれている…。
これでは先に進めないので、ちゃんとした日本語ならどうなのか、もう一回やってみました。
・清書版ツイート
私の携帯電話の壁紙を私のキャラクター画像に変更してから、私は携帯電話を見るたびにその可愛さに驚きます。
さて、では気を取り直してこちらを翻訳にかけると、
After changing the wallpaper of my cell phone to my character image, I am surprised by the loveliness every time I see the cell phone.
あ、いいんじゃないの!
さあ、分析してみましょう!!
{
"ResponseMetadata": {
"HTTPHeaders": {
"connection": "keep-alive",
"content-length": "166",
"content-type": "application/x-amz-json-1.1",
"date": "Sun, 01 Jul 2018 08:18:40 GMT",
"x-amzn-requestid": "5ca06aeb-7d07-11e8-8571-ff2a299154cc"
},
"HTTPStatusCode": 200,
"RequestId": "5ca06aeb-7d07-11e8-8571-ff2a299154cc",
"RetryAttempts": 0
},
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.0005288332467898726,
"Negative": 0.0012016192777082324,
"Neutral": 0.005725542549043894,
"Positive": 0.9925440549850464
}
}
圧倒的POSITIVE!!!!
成功だ!
インプットがちゃんとしていればどちらも精度が高いですね。
というわけで、
この参考にしたツイートの日本語が悪かっただけ、という前提のもと、
フィージビリティが あることにして あることが分かったので、次のステップに向かっていきます。
4. 可視化
これが一番面倒だったかもしれない。
最初は昔インストールしていたpentahoの試用版でやろうとしたんだけど動作が遅いし、UIがよくわからん。
ので、改めて最近の流行をググったところ、SupersetというOSSがあるそうではないですか。
こちらのページを参考に、インストールしてみました。
https://qiita.com/ikotan69/items/10dd7a1cb8a396557ca9
※もちろんQuick Sightも検討したのですが、料金体系が怖かったのでActivateしませんでした。
このSupeset、pentahoと比べてUIが非常にわかりやすく、簡単にセットアップできました。
セットアップ中はSQL Alchemy URLでlocalhostを指定できないところで困ったぐらい。
このSupersetっていうやつ、かなり可能性を感じる…!
いつか業務で利用する日がくるかもしれないなあ。
結果
出来上がったSupsersetのDushboardがこちら!
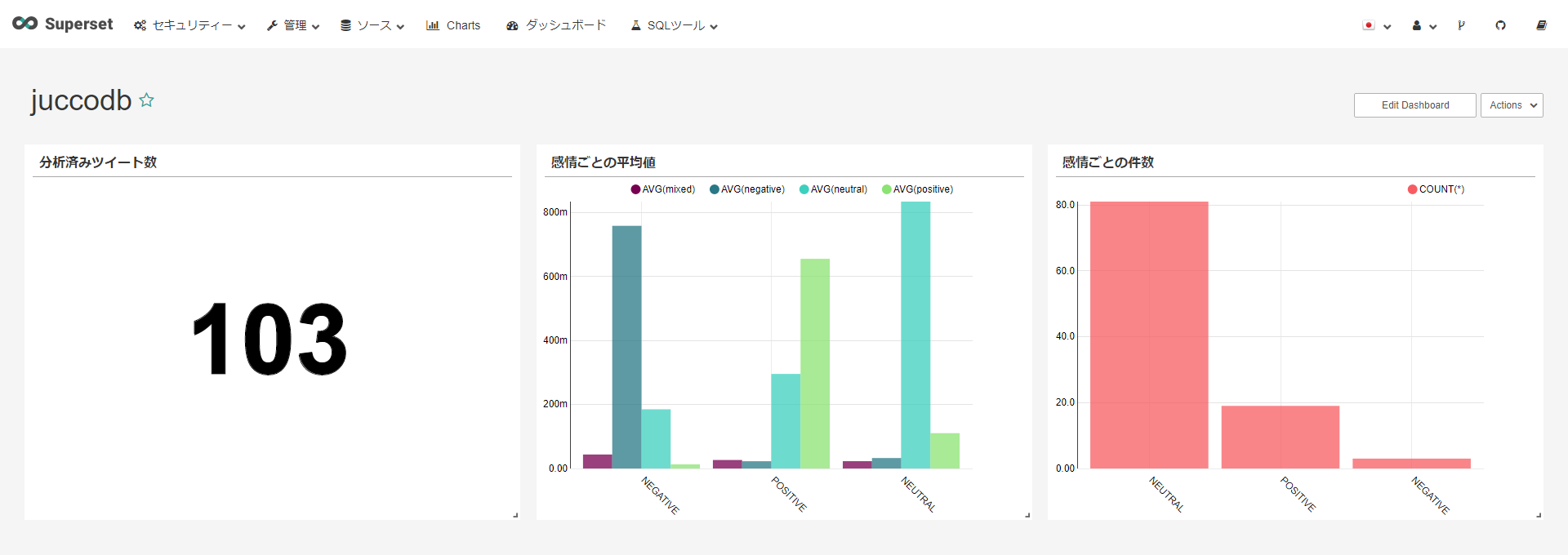
1~3のAPI発行はcronで10分毎に、Supsersetは5分毎に自動で画面をリフレッシュします。
今回はキーワードに指定した文字列を含むツイート数が少ない傾向なので、初期の100件を取り込んでからは大して分析量が伸びていません。
お財布的には安心なので、この傾向は維持していただきたい…。
感想
一番苦労したのはほぼ初めて使うpythonの実装でした。
今までずっとshell芸人だったので、他の言語も読めるようには…と思ったのがきっかけで今回使ってみました。
絶対もっと楽にきれいに書けるはず、という箇所がめちゃんこあるので、もう少し練習しないと。
可視化ツールについては、昔からcsvをグラフ化するjavascriptとかsplunkとかを試していた気がしますが、
このSupersetという子はかなりできる子な気がします。
インストールっていうかdockerから立ち上げるだけで利用可能だし、グラフの作成も簡単で早い。
テーブル間のJOINができたらもっといいと思うんだけど、ちゃんと調べればそのぐらいの機能はちゃんとありそう。
こちらについても、今後もう少し勉強してみたいところです。
今後やりたいこと
・集計対象外ツイート(ブラックリスト)の実装
公式まわりのアカウントがRTするせいでNeautralやPositiveが必要以上にカウントされている。
TwitterのUser ID単位でブラックリスト化すればよさげだけど、手で運用するのは嫌。
あー、もしかしてSearch APIのResponse内に公式アカウントかどうかフラグあるかも?
それで除外できたら嬉しい。
・過去分のツイートもさかのぼって取り込み
Search APIでtermを指定できたはず。初回キーワードだけ、期間を遡って取得する仕組みが必要。
・複数の異なるツイート検索・取得を実行
今回は1条件だけだったけど、設計テーブルに複数件の検索条件を登録しておけば全部舐めるようにはした。
コードのほうよりは、それをSupersetで自動で取り込めるようにしたい。
・時系列ごとのツイート数の伸びグラフ
これはすぐにできそうな気がするけど、なんかうまく表示できない。ちゃんとマニュアル読まないとダメか。