本記事の概要
本記事では、2クラス分類のプログラムについて記載している。
全体については、以下の記事を参照。
CNN画像解析:一般的な写真画像とドキュメント画像を分類するプログラムを作成
本ブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開している。
開発環境
-
Google Colaboratory
モデルの作成・実行はGoogle Colab上で行った。
Pythonのバージョンは3.10.12 -
Windows 11
Flaskによるアプリ作成・実行はWindowsローカルPC上で行った。
Pythonのバージョンは3.11.5
アプリの概要
風景や人物と言った一般的な写真画像と、画面スクリーンショットや文書等を撮影したドキュメント画像を区別する、CNN画像認識技術を用いた2クラス分類のプログラムを作成する。
詳細な説明は以下の記事を参照。
CNN画像解析:一般的な写真画像とドキュメント画像を分類するプログラムを作成

学習に用いたデータセット
すべてkaggleからダウンロードした。
Visual China
エッフェル塔や万里の長城、ピラミッドなどの風景写真画像が用意されている。それらの景勝地を背景とした人物写真も含まれている。また、各景勝地ごとに約1000枚以上あり、学習の材料として十分な量を確保できた。
Screenshots Dataset
FacebookやTwitter、WhatsAppなどSNS別にスクリーンショット画像が用意されている。画像枚数はSNS種類ごとに10~80枚程度。ただし、文章だけでなく画像+文章という形態が多く、今回の学習用でドキュメント画像として利用するためには文章をメインとした画像が必要で、手作業で学習に使える画像を分類したので、学習に使える画像は130枚となった。
Java code screenshots
Javaのコーディングのスクリーンショット画像が用意されている。600枚以上あり、学習の材料として十分な量を確保できた。
当初、前項のSNSスクリーンショットを材料に学習を行っていたが、背景色のばらつきがあったり、枚数を多くして検証したりする際に対応できなかったため、枚数の多いデータセットを探した。
上記データセットのライセンスは、いずれも1 CC BY-NC-SA 4.0(表示—非営利—継承)。
作成したプログラム①CNNによる学習モデル
一般画像を「0」、ドキュメント画像を「1」とする、2クラス分類(二値分類)を行う。
VGGモデルを用いた転移学習を行い、最終的に二値分類の結果を得るため、0~1の間で答えを返すSigmoid関数の層を結合した。
例えば、これらの画像を読み込んだ場合、結果は0~1の範囲で与えられるため、おおむね0.5以下ならば「クラス:0」の一般画像、0.5より大きければ「クラス:1」のドキュメント画像と判定する。

↑↑↑ 結果:0.01とすると、0に近いので「一般画像」
↑↑↑ 結果:0.95とすると、1に近いので「ドキュメント画像」
損失関数と最適化関数は以下のとおり。
| 設定項目 | 設定値 |
|---|---|
| 損失関数 | binary_crossentropy |
| 最適化関数 | SGD |
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
import pandas as pd
# ファイルパス
path_gen = os.listdir('./dataset/0_gen_pic/') #一般画像
path_doc = os.listdir('./dataset/2_doc_pic/') #ドキュメント画像
img_gen = []
img_doc = []
np.random.seed(0)
path_tmp = np.array(path_gen)
rand_index = np.random.permutation(np.arange(len(path_tmp)))
path_gen = path_tmp[rand_index]
for i in range(100):
img = cv2.imread('./dataset/0_gen_pic/' + path_gen[i])
if i == 0:print(path_gen[i],img.shape)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
if i == 0:print(path_gen[i],img.shape)
img_gen.append(img)
for i in range(100):
img = cv2.imread('./dataset/2_doc_pic/' + path_doc[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img = cv2.resize(img, (50,50))
img_doc.append(img)
X = np.array(img_gen + img_doc)
y = np.array([0]*len(img_gen) + [1]*len(img_doc))
# 一般画像ファイル
# ドキュメント画像ファイル
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
print(vgg16.output)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dense(1, activation='sigmoid'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# 19層目までの重みをfor文を用いて固定する
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(learning_rate=1e-4, momentum=0.9),
metrics=['accuracy'])
#model.summary()
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=32, epochs=10)
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# 学習過程
# Pandas 形式
result = pd.DataFrame(history.history)
# 目的関数の値
#result[['loss', 'val_loss']].plot();
# 正解率
#result[['accuracy', 'val_accuracy']].plot();
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
学習結果は以下のとおり。
Test loss: 7.939404342294232e-13
Test accuracy: 1.0
作成したプログラム②アプリ(サーバサイド)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '1'
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
image_size = 50
UPLOAD_FOLDER = "./uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
app.secret_key = "12345"
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
#学習済みモデルをロード
model = load_model('./model.h5', compile=False)
# request.method == 'POST'であるとき、これから後に続くコードが実行される
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
# 今回モデルはグレースケール指定ではないため、color_mode="grayscale"無指定
org_img = image.load_img(filepath, target_size=(image_size,image_size))
img = image.img_to_array(org_img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
if(result[0] < 0.5):
pred_answer = "これは 一般画像 です"
else:
pred_answer = "これは ドキュメント画像 です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
# app.run()
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
作成したプログラム③アプリ(クライアントサイド)
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Image Classifier</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">Image Classifier</a>
</header>
<div class="main">
<h2> 画像の種類を識別します(風景や人物など一般的な画像/文書などを撮影したドキュメント画像)</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2019 Aidemy, inc.</small>
</footer>
</body>
</html>
アプリ
上記で作成したアプリはこちら
任意の画像ファイルを送信し、種類を識別し、「一般画像/ドキュメント画像/アート画像」のいずれかに該当する結果を文字列で返却し画面に表示する。
※サーバが重すぎて答えが返ってくるのに大変時間がかかる。
結果・まとめ
学習に使用したデータセットから、ランダムに抽出した画像イメージでテストを行った結果は以下のとおり。
一般画像は「General Image」、ドキュメント画像は「Document Image」として予測結果が出力されている。
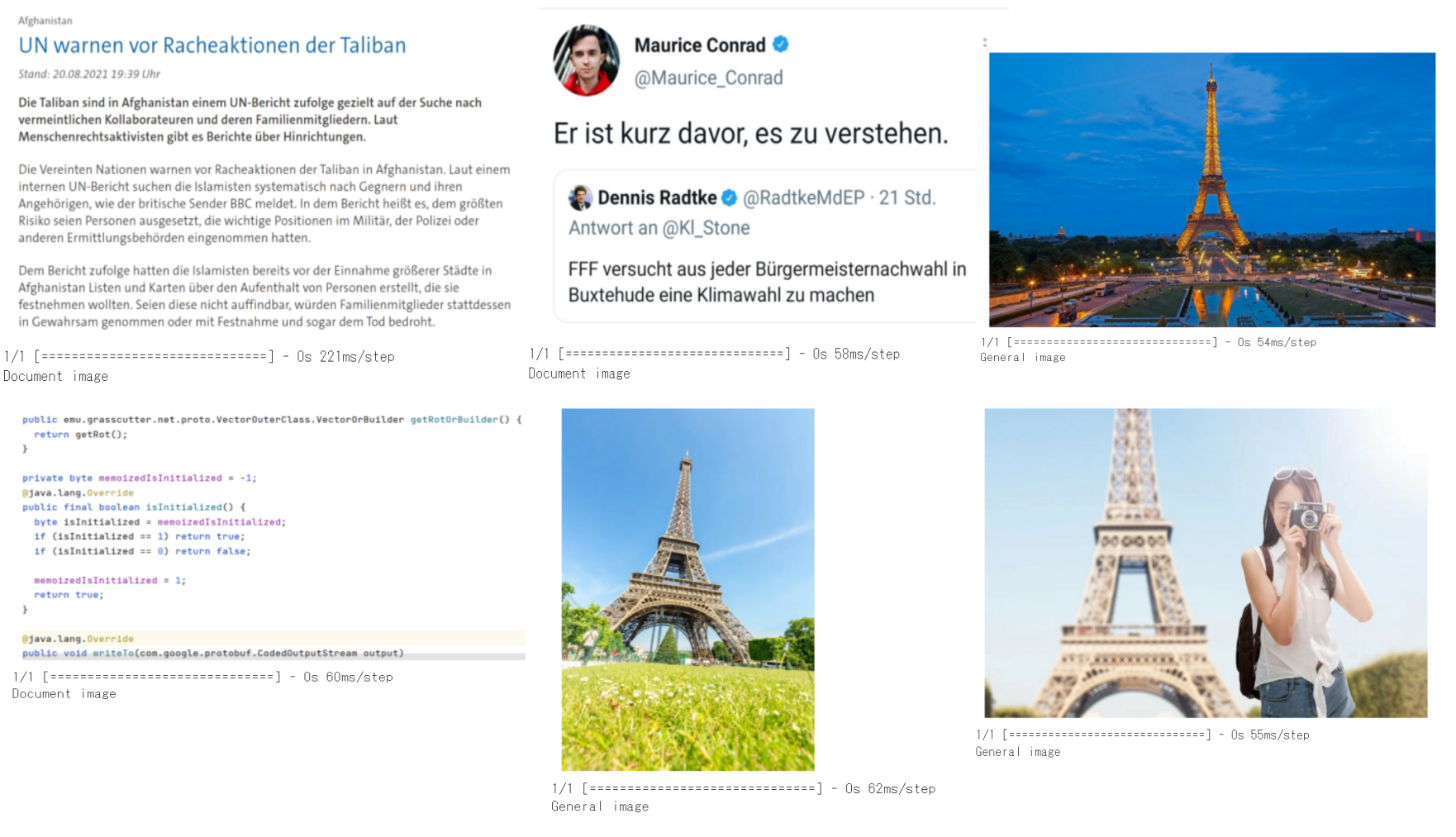
用意したテスト画像に対しては、100%の的中率となった。
といっても、これが特に優れたモデルだという訳ではなく、単に明確な差異がある材料に対し、適切なモデルを設定した結果であるという点を明記しておきたい。
もしも色や形などにはっきりとした違いのある「二つのもの」を区別したい場合には、このモデルを活用することができる。ただし、人の目にもあまり明らかでないような微細な違いを判別するためには、学習材料であるデータセットの量を増やしたり、学習のパラメータやCNNの階層を工夫したりする必要があるだろう。
-
原作者のクレジットを表示し、かつ非営利目的に限り、また改変を行った際には元の作品と同じ組み合わせのライセンスで公開することを主な条件に、改変したり再配布したりすることができるライセンス。 ↩