はじめに
マイクロサービスが誕生してから約10年経っていますが、日本の大企業でのマイクロサービスの成功事例、特にレガシーな大規模システムからの移行事例についてはそこまで多くないかと思います。
大規模システムをマイクロサービス化することについて、考察してみたいと思います。
1. マイクロサービスとは
マイクロサービスは、2012年にJames Lewis氏が発表された"Microservices - Java, the Unix Way"が起源とされ1、並行処理技術が進展する中で、巨大IT企業で使用されていたアーキテクチャのことを後から名付けしたものです。
色々な定義がありますが、各クラウドベンダの定義を引用してみました。
小さな独立した複数のサービスでソフトウェアを構成する、ソフトウェア開発に対するアーキテクチャ的、組織的アプローチ(AWSの定義より) 2
複数の独立した小さなコンポーネントやサービスの組み合わせによりアプリケーションを開発する、クラウドネイティブなアプローチのアーキテクチャー(IBMの定義より) 3
私は、「アプリケーションを個別に開発した小さなサービスや機能」を構成するアーキテクチャと捉えています。そのため、サービスの中にはアプリ(機能)とデータベース(DB)を内包しています。
他のデータに対する更新時には、担当サービスに対してAPIやメッセージキュー等により処理を依頼(委譲)する形を取ります。
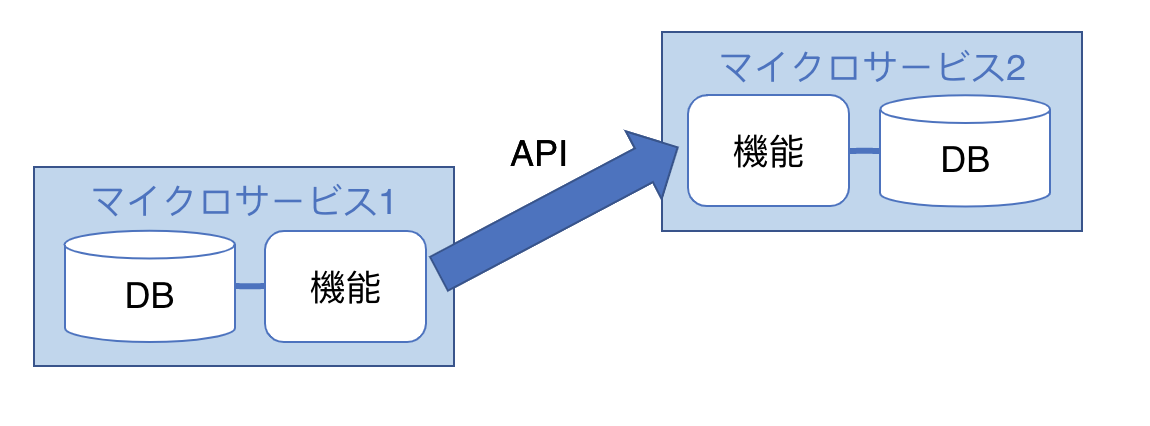
2. 登場の背景
このようなマイクロサービスアーキテクチャですが、私は、DBをスケールアウトできる構成を取れるアーキテクチャと理解しています。
すなわち、導入の効果としては、
- 膨大なトランザクションを処理可能になるようにスケールアウトしやすくすること
- サービス提供時の可用性確保
の2点があると思います。
通常、データベースはスケールアウトが難しい製品です。
データベースには、2002年に提唱された「CAPの定理」という制約があります。
分散システムにおいて、DBMSに関する下記3つの特徴のうち、最大2つまでしか満たすことができないというものです。
CAPの定理
- Consistency(一貫性):全ノードが同時に同じデータを見える
- Availability(可用性):一部ノードで障害が起きても処理継続可
- Partitions(分断耐性):ノード間が分断されても正しく動作
RDBMSでは、一貫性と可用性をできるだけ保証する代わりに、ネットワークの分断耐性を犠牲にしており、ノード間が分断されてしまうと動かなくなってしまいます。
ですので、DBサーバを1サーバに集約させ、性能を「スケールアップ」する必要がでてきます。
ですが、増強としても限界がありますし、そもそも、この1サーバがダウンしてしまったらシステム全体が動かなくなってしまったら問題です。
そのため、このようなシステムでは、複数サーバでデータベースを稼働させる一方で、サーバ間のデータの一貫性をある程度見切ることが必要になります。
その結果、データを分割して配置するということで、たとえ密結合のデータであってもデータ一貫性を厳密に守らなくて良いデータは、データソースを分けることでDBサーバの負荷分散を図るようになり、マイクロサービスのような考え方が生まれたと考えられます。
言い換えますと、大規模で各ドメインが複雑に関連し合っているシステムには、最初からマイクロサービスアーキテクチャは向かないとも言えます。
3. よくある誤解
今まで、マイクロサービスについて述べてきましたが、この説明だと、もしかしたら想像していたものとだいぶ違うと思われる方もいらっしゃるかと思います。
事実、マイクロサービスは、その語感から様々な誤解を招いていると思います。いくつか例を挙げてみます。
【誤解1】マイクロサービスは、サービスの粒度を非常に小さくする必要が有る
Martin Fowlerは、
『マイクロサービス』と言う言葉はラベルであり、説明ではない」
と言っています1。
マイクロサービスは「マイクロ」である必要は無いということです。
中身を把握可能な単位で、他チームとの連携を最小限に抑えた小規模チームで開発できることが最も生産性を高くできる状態であって、細か過ぎると分割損の方が大きくなります。
【誤解2】マイクロサービスでないと、疎結合を実現できない
マイクロサービス=疎結合と捉えていらっしゃる方も多い気がしております。
プログラム間・モジュール間を疎結合にすることはとても重要で、今も昔も変わりません。
ただ、マイクロサービスでなくても、ソフトウェアの疎結合は実現できます。例えば、レイヤードアーキテクチャの考え方を導入することです。
「マイクロサービス」という言葉を「ソフトウェアレイヤーで疎結合を実現するアーキテクチャ」と捉え、とりあえず「マイクロサービス化」すべきと上司から指示されてしまうと、指示を受けた部下がマイクロサービスを狭義で捉えてデータソースの分割が必要と考えてしまう恐れがあります。その際、後述する「データソースの切り出し」に苦労されるプロジェクトもあるのではないでしょうか。
【誤解3】マイクロサービスの採用の利点は「再利用性」
こちらも以前は大原則として考えられていました。
- 同じロジックを複数箇所に書かない
- 二重開発させない
というのは、多くのシステムで採用されている方針かと思います。
ですが、再利用性を考慮するライブラリができ、多くのシステムから利用されるようになると、それだけステークホルダーが多くなり、ライブラリの改訂にあたり、調整先がかなり膨れ上がります。
そのため、マイクロサービス採用時には、改訂への影響を極小化するため、サブルーチンをあえて共用せず、プログラムを複製して使用したり、それぞれのマイクロサービスで開発したりする選択肢もあるかと思います。
4. 既存システムへの導入方法
最初にご説明した通り、既に出来上がっているシステムに対してマイクロサービスを導入するには、データソースを切り出す必要があります。
(1) モジュール間の依存関係の整理
①CRUD図作成
DBの分割にあたってよく利用される手法は、機能×DB操作のCRUD図を作成することです。
CRUD図
- C: Create(INSERT) 作成
- R: Reference(SELECT) 参照
- U: Update (UPDATE) 更新
- D: Delete (DELETE) 削除
例えば、下図のようなものです。
| テーブルA | テーブルB | テーブルC | テーブルD | |
|---|---|---|---|---|
| 機能1 | CUD | |||
| 機能2 | R | CRUD | R | R |
| 機能3 | CUD | CUD |
この例の場合、機能1はテーブルAしか更新しません。
となると、機能1は機能2や機能3に依存せずに構築することが可能です。
このようなものはマイクロサービスとして外出し可能です。
一方で、下図の場合はどうでしょうか。
| テーブルA | テーブルB | テーブルC | テーブルD | |
|---|---|---|---|---|
| 機能1 | CUD | UD | UD | |
| 機能2 | R | CRUD | R | R |
| 機能3 | CUD | CUD |
機能1を実現するためにはテーブルA、テーブルC、テーブルDに対する変更が必要です。
一方で、テーブルC、テーブルDは機能3でも使用されます。
となると、機能1・機能3が複雑に絡み合って密結合になっており、マイクロサービスとして切り出しづらいということになります。
②機能間依存関係の整理
上記はDB×機能でしたが、機能×機能、すなわち機能間の依存関係でも同じ議論ができます。
(A) シンプルかつ一方通行な依存関係
(B) 複雑で相互で呼び出し合う関係
例えば、機能1を直したいとします。
(A)の場合は機能1を使用している他機能はありません。
従って、外部インターフェースの仕様さえ変えなければ、機能1は独立して修正可能であり、
機能1単独でマイクロサービス化することは比較的容易なはずです。
一方、(B)の場合はどうでしょうか?
機能1は、機能2からも機能3からも呼ばれています。
そうなると、機能1は機能2や機能3に対してインターフェースを変えないようしないといけませんし、仮に変えなかったとしても、機能2・機能3を通して使用するようなシナリオテストを実施しないと不安になってしまいます。
すると、機能1は機能2・機能3と分割できず、マイクロサービス化しづらいと言えます。
(2) トランザクション一貫性の見直し
また、CRUD図に話を戻します。CRUD図を実際に書いてみると、エンタープライズシステムの場合、一つの機能がたくさんのテーブルに対して更新をかけるケースが多いかと思います。
そうなると、マイクロサービス化できない、となりかねないですが、もう一段深い考察をしてみる価値があります。
それは、それらテーブルを本当に1トランザクションで同時に更新しないといけないか?について考えること、DBのACID属性で言うと「Atomicity(原子性)」「Consistency(一貫性)」が本当に必要かについて考えることです。
例えば、Webのメールサービスとスマートフォンのメールサービスがあるときに、
スマートフォンでメールを削除した直後にWebサービスを見ても、削除処理が反映されていない場合があるかもしれません。
これは、WebのメールサービスのDBと、スマートフォンのメールサービスのDBが同期を取られていないことで発生しています。
ただ、それで日常困るか?というと、さして困らず、サービス側で後から削除してもらう、言い換えると「良きに計らってもらえれば」OKです。
このように、データソース間で同期を取らなくても良いケースがあります。
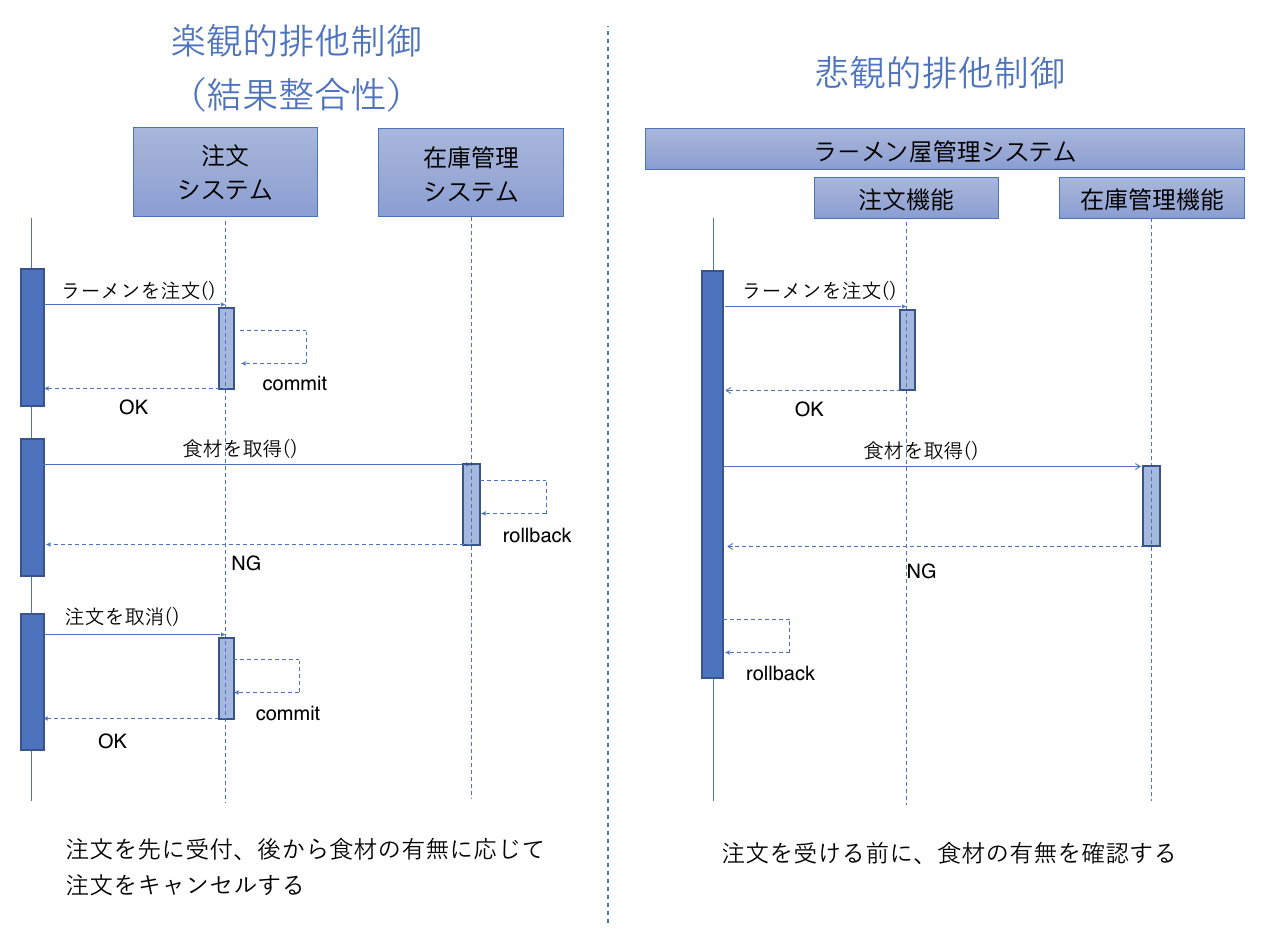
DBのACID属性を担保している悲観的排他制御に対して、このケースを楽観的排他制御と言ったり、結果整合性という表現をします。結果的に整合性が取れていればOKとできる場合、それぞれを別システム・別DBに分離することができます。
Sagaパターン
この結果整合性ですが、処理が正常の場合はあまり気にすることはありません。
ですが、処理が異常終了する場合、面倒なことになります。
ラーメン屋さんを例にとって説明します。注文受けた後に、麺が品切れしていたと仮定しましょう。
| システム | 対象 | 数量 |
|---|---|---|
| 注文 | ラーメン | +1 |
| 在庫管理 | 麺 | -1 |
| 〃 | スープ | -1 |
| 〃 | 具 | -1 |
悲観的排他制御の場合は、上表の4レコードを同時にcommitします。
そのためアプリ的には、麺が品切れ状態か、コミットする前に先にチェックしますが、アプリケーション側でチェックしなくても、麺を-1しようとして、品切れであることにDBのチェック制約が気付いてエラーを返し、全レコードRollbackすることができます。
一方、結果整合性の場合は、注文システムで一回commitを発行してしまいます。
その後、在庫管理システムで食材の確認をしたときに品切れに気づくため、注文を取り消す必要が出てきます。
そのため、注文を取り消すという取消電文を注文システムに対して発行することになります。
この取消電文のことを一般的に補償トランザクションと言い、
また、このような補償トランザクションによりシステム間のデータ整合性を担保する仕組みをSagaパターンと言います。
言い方を変えると、悲観的排他制御は、DBMSが「Rollback機能」により補償トランザクションが実装されており、アプリ開発者側がRollback要件を気にしなくて良くなっているとも言えます。
楽観的排他制御の場合、補償トランザクションを自ら開発する必要があるというわけで、ここがマイクロサービス化導入にあたって、追加で必要になります。
(3) その他技術との融合
マイクロサービスはスケールアウトもしやすいアーキテクチャという特徴があることをお話しました。
スケールアウトを実現するために、主だった技術としては、
- コンテナ
- サーバレス/FaaS(Function as a Service)
等があります。少しだけご説明させていただきます。
①コンテナ
RedHatの説明では、コンテナ(Container)とは、下記のとおり説明されています。
アプリケーションとランタイム環境全体、つまり実行に必要なすべてのファイルをパッケージ化し、分離させるテクノロジーです。これにより、コンテナ内のアプリケーションを、すべての機能を維持したまま複数の環境 (開発、テスト、本番環境など) の間で容易に移行することができます (RedHat) 4
VM(Virtual Machine)のイメージでも、同じことはできるかもしれません。
ですが、コンテナの方がより楽にデプロイできることと、kubernetesのようなコンテナオーケストレーション製品を使用すると、Podと呼ばれるサービスの数を簡単に増減すること、すなわちスケールアウト・スケールダウンが容易に可能です。
但し、コンテナを導入するとしても、既存のアプリケーションが対応できない場合があります。
典型的な例は、ステートレスなアーキテクチャになっていない場合です。
話題がだいぶ膨らんでしまうので本記事では割愛しますが、APサーバにセッション情報を管理している場合、
他のAPサーバ(Pod)に移った場合、セッション情報が無く処理ができなくなることがあります。
このようなステートフルなアーキテクチャの場合は、その処理方式を見直す必要が出て来ます。
②サーバレス/FaaS
サーバレスアーキテクチャは、
本当にサーバが無いという意味では無くて、サーバを管理・意識せずにアプリケーションを実行できるような構成のことを指しています。有名なサービスとしてはAWSのLambda5があります。
APサーバのクラウドサービス(AWSの場合、AWS Elastic Beanstalk6)もありますが、
これらのサービスと比較すると、
- スケールアウトがやりやすい(これはこの章のテーマなので当然ですが)
- OS等の環境設定が不要(Elastic Beanstalkの場合、EC2(オンプレミスではVMに相当)の環境構築が必要)
- 何よりも低コスト
というメリットがあります。こちらも、ステートレスなアーキテクチャになっていることは必須です。
他にも、サービスメッシュやCI/CDの導入等、マイクロサービスの導入効果を出すためには様々な周辺技術の導入が必要になります。
5. 大規模システムに対してマイクロサービスは不要か?
今まで見てきた通り、既存システムをマイクロサービス化するには険しい道のりがあります。
そこまでしてエンタープライズシステムをマイクロサービス化する必要があるのでしょうか?
マイクロサービス化にはいくつかメリットがありますが、大きく
- スケーラビリティ
- アジリティ(俊敏性・柔軟性)
の2点があるかと思います。
【効果1】スケーラビリティ
こちらは、これまでもかなり説明してきました。
特定処理だけスケールアウトしたいというケースは多く出てくるかと思います。15年以上前であれば、APサーバに対して多重スレッドで実行する処理方式を採用することもあったかと思いますが、マルチスレッドのコーディングは難易度が高いです。
処理量が多い機能のみ外出ししてマイクロサービス化しておくことで、インフラ面の多重度を上げることができ、必要最小限のコストで効率的に処理スピードをあげられます。クラウドであればリザーブドサーバを活用できますし、オンプレであってもコンテナで実装することでスケールアウトが可能です。
【効果2】アジリティ
アジリティ観点でもマイクロサービスの導入は効果的で、いくつかメリットが考えられます。
- アジャイル開発がしやすい
- CI/CDが入れやすい ⇒開発の自動化が可能に
- 他システムとは独立して仕様を決められる
アジリティを上げるためには、例えばビルドに1時間かかっていたり、仕様を決める際に、関連サブシステム間で多くの調整が発生するようなアーキテクチャでは難しいです。
正に、マイクロサービスのようなアーキテクチャで、少人数が自律的に開発できるように、システム間の境界を決める必要があります。
Stranglerパターン
この2点のいずれかを満たしたい機能があるとき、マイクロサービス化を検討するに値します。
その際、システム全体をマイクロサービス化するのではなく、その機能のみをマイクロサービス化します。
これがStranglerパターンと呼ばれる方法です。
こちらも、別途ご説明させていただこうと思います。
6. まとめ
マイクロサービスを日本のエンタープライズシステムに適用できるか、について考察してみました。
改めて考えると新規システム開発にとっては素晴らしい概念ですが、既存システムをマイクロサービス化するとなると大変難しいです。導入に当たっては色々な障壁があります。
と言いながらも、必ず必要となる局面は出てくると思います。
この障壁を乗り越えられれば、理想的なシステム開発に近づくことは間違いありません。
効果を上げるためには、必要なサービス・機能に絞って導入することが肝要と感じました。
参考
Martin Fowler氏のブログ
AWS:マイクロサービスの概要
IBM: マイクロサービスとは
書籍「実践的システムデザインのためのコード解説」 マイクロサービスパターン (Chirs Richardson著 長尾 高弘 訳/インプレス社) (2020/3発行)
マイクロサービス化のプロセスをJavaのプログラムコードで解説しているため、非常にイメージが沸き易い本です。
書籍「モノリスからマイクロサービスへ -モノリスを進化させる実践移行ガイド」(Sam Newman 著 島田 浩二 翻訳/オライリージャパン)(2020/12発行)
本文では、データソース分割に真っ向から挑みましたが、やはり難易度が高いことが多いです。この書籍では、マイクロサービス側にVIEWとして見せたり、マイクロサービス側のDBとモノシス側のDB間の同期を取ったり、様々な工夫が掲載されています。
サーガ(Saga)パターンについても紙面を割いて説明しています。