プロデルでウェブブラウザ部品を使ってウェブページの特定の情報を取り出すツールを作ってみました。Webメールやオークションサイトなどで自分が欲しい情報だけを定期的に取り出して自分だけのツールを作ることができます。
ウェブスクレイピングは個人利用で
ウェブスクレイピングは、自分の欲しい情報だけを定期的に得る方法としてとても便利ですが、意図しない方法で利用されることや大量の機械的なリクエストで負荷が掛かることを望まない提供者もいて、抽出することを禁止しているサイトもあります。サイトによっては公式APIが提供されていることもありますので、原則としてAPI関数を通じて情報を取得するべきです。また大量のウェブページからこの記事の方法でウェブスクレイピングすることはおすすめしません。プロデルでのウェブスクレイピングは個人利用でお願いします。
ウェブスクレイピングする際には次のような記事をご覧になると良いかと思います。
ウェブブラウザ部品を使う
プロデルには、IE互換のウェブブラウザ部品が用意されています。
ウェブブラウザ部品を使ってウェブページから情報を抽出してみようと思います。
「HTTP」種類を使ってHTMLソースをダウンロードし正規表現で目的の情報を抽出する方法もありますが
- HTMLの解析が面倒(HTML要素がネストする場合などで正規表現で書けない)
- ログインしてアクセスできるページではセッション(クッキー)を管理しないといけない
という点があるので、HTMLの解析やクッキーの管理をウェブブラウザに任せて、DOMをプロデルから操作して必要な情報を取り出してみることにしました。HTMLやDOMの知識があれば、その方が簡単です。
wikipadiaから「今日の出来事」を抽出する
まずは、特定のウェブページから必要な情報だけをスクレイピング(抽出)してみます。
wikipadiaのメインページには「今日の出来事」というカラムがあり、過去の同じ日の出来事をみることができます。
https://ja.wikipedia.org/wiki/メインページ
次のような作業をしてプログラムを作っていきます。
- 事前に抽出する場所(HTML要素)を調べる
- ウェブブラウザ部品で目的のアドレスにアクセスする
- ページ読み込み後のDOMから内容を抽出する
抽出する場所を調べる
ウェブページから特定の場所の内容を抽出するには、抽出する箇所がHTMLのどの場所に当たるかを調べておく必要があります。抽出する箇所を調べるには、「開発者ツール(デベロッパーツール)」([F12]キー)を使って、目的の場所のHTML要素を調べます。
例えば、wikipadiaから「今日の出来事」の場合は次の場所にあります。
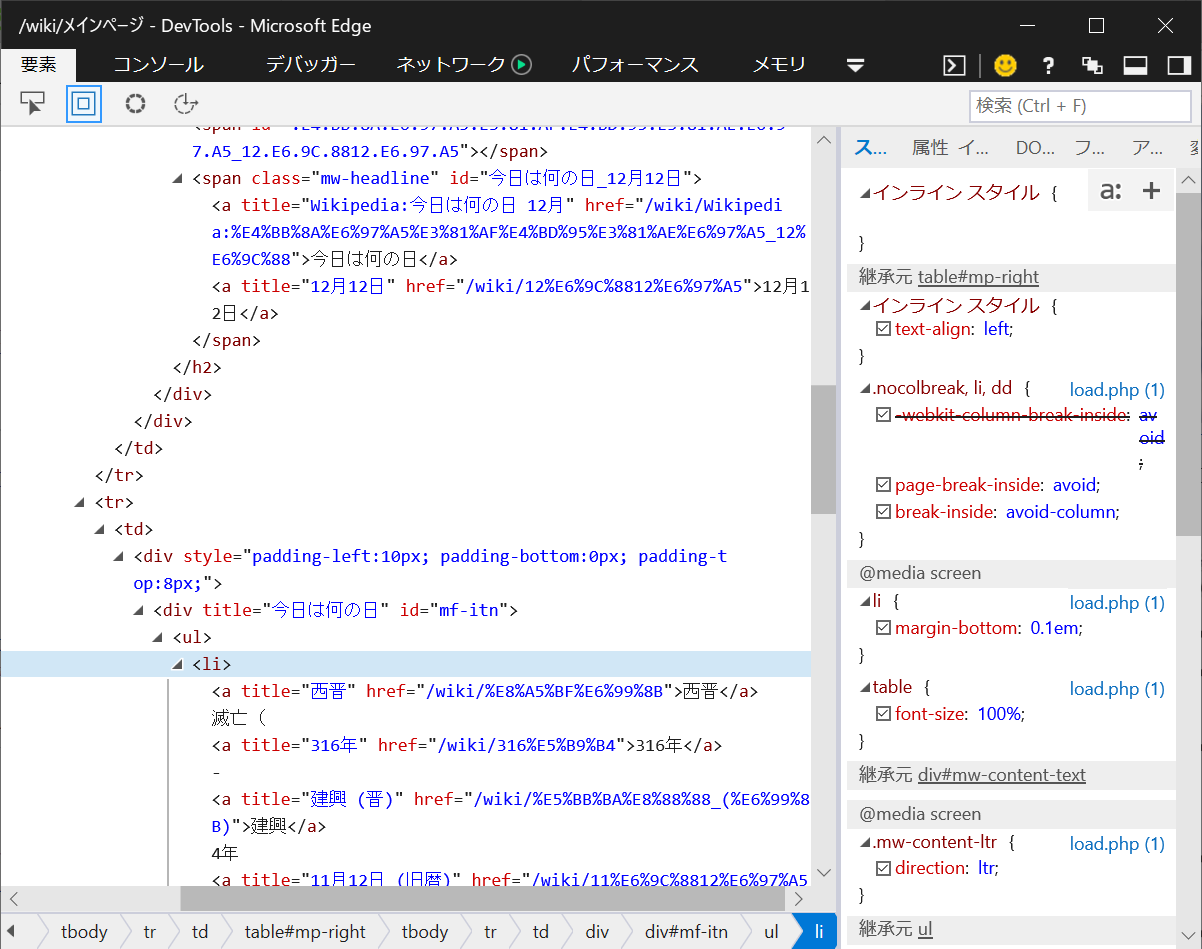
このページでは、<div title="今日は何の日">あたりが手がかりにできそうです。
なおここで調べた場所は、ウェブサイトのリニューアルなどで変わることがあります。ウェブサイトが新しくなった場合は、再度抽出する箇所のHTMLを調べておく必要があります。
抽出する際は、目印にあるHTML要素や属性値があることを確認します。
- id属性(ユニークな名前なので探しやすい)
- class属性(大抵はユニークなクラス名が指定されていることが多い)
- 特殊なHTML要素(<ul>や<nav>など特徴的なHTML要素をヒントにする)
- 要素の登場順(抽出の難易度が高い)
などです。このあたりについては、抽出したいウェブサイトのHTMLソースの特徴を理解しないといけないので、開発者ツールを使って、抽出の手がかりになるHTML要素を探してください。
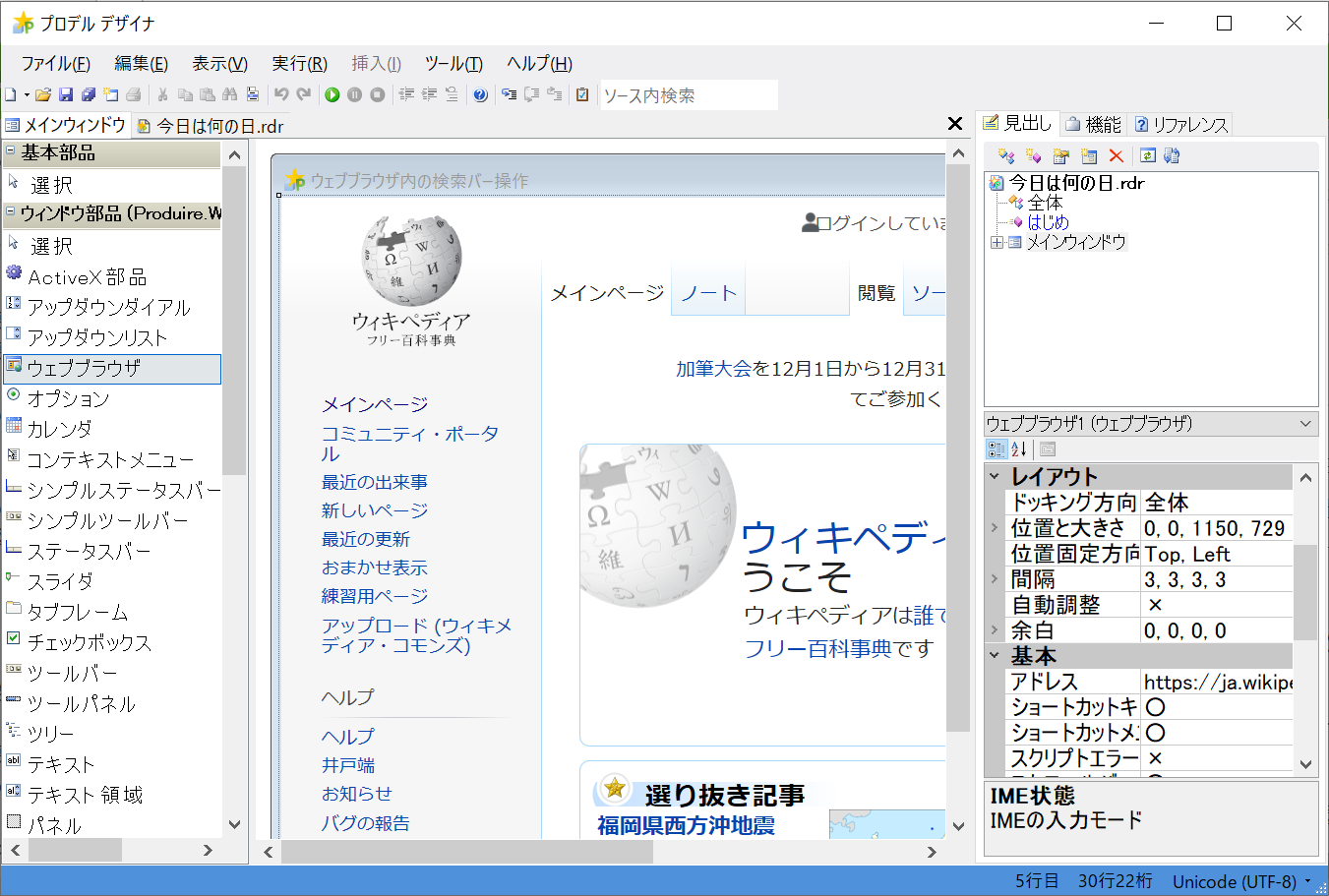
ウェブブラウザ部品を貼り付ける
メイン画面を作ります。プロデルの開発環境であるプロデルデザイナにはフォームデザイナが搭載されていますので、マウス操作で部品を貼り付けられます。
ページ読み込み後の処理を作る
ウェブブラウザでアドレスを指定しても、すぐに表示されません。サーバにアクセスしてページをダウンロードするまでにタイムラグがあるためです。
そのため、「ページが完全に読み込み終わった時」に、HTMLの抽出処理を実行するように作り込む必要があります。
//ウェブブラウザ内の検索バー操作
メインウィンドウを表示する
待機する
メインウィンドウとは
ウィンドウを継承する
はじめの手順
初期化する
ーー貼り付けた部品に対する操作をここに書きます
終わり
初期化する手順
ーー自動生成された手順です。ここにプログラムを書き加えても消える場合があります
この実質大きさを{1150,729}に変える
この内容を「wikipadiaから今日の出来事」に変える
このドラッグドロップを○に変える
初期化開始する
ウェブブラウザ1というウェブブラウザを作る
その位置と大きさを{0,0,1150,729}に変える
そのアドレスを「https://ja.wikipedia.org/wiki/メインページ」に変える
そのドッキング方向を「全体」に変える
初期化終了する
この設計スケール比率を{144,144}に変える
終わり
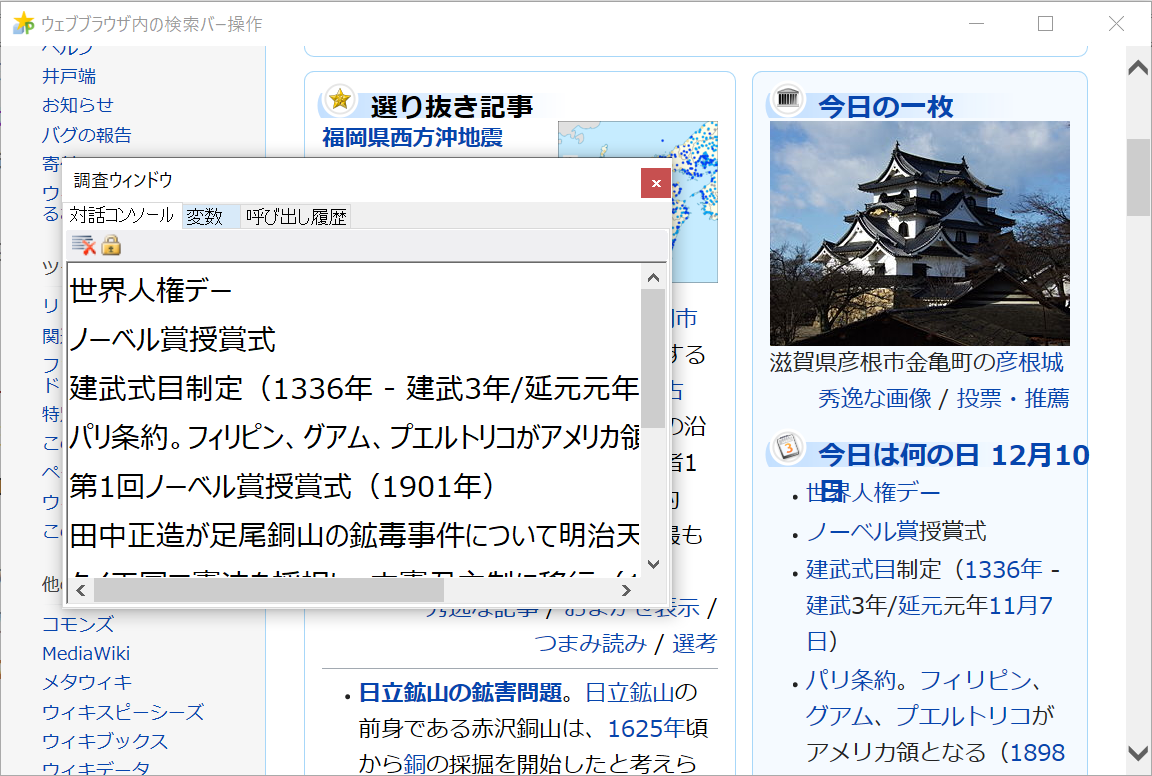
ウェブブラウザ1のページが読み込まれた時の手順
//2019年11月現在は次の通りで検索バーから検索できます。
対象要素は、ウェブブラウザ1のページ
対象要素から「div」という要素を取得したもののすべてのdiv要素についてそれぞれ繰り返す
もしdiv要素から「title」という属性値を取得したものが「今日は何の日」なら
div要素の内容を報告する
繰り返しから抜け出す
もし終わり
繰り返し終わり
終わり
終わり
Yahoo!検索を自動化する
次はフォーム要素を操作させてみます。ウェブブラウザ部品ではDOM要素中のフォーム要素の値を変更することもできます。これを応用して、キーワードを入力して検索ボタンをクリックする操作を自動化できます。
//ウェブブラウザ内の検索バー操作
メインウィンドウを表示する
待機する
メインウィンドウとは
ウィンドウを継承する
はじめの手順
初期化する
ーー貼り付けた部品に対する操作をここに書きます
終わり
初期化する手順
ーー自動生成された手順です。ここにプログラムを書き加えても消える場合があります
この実質大きさを{1150,729}に変える
この内容を「Yahoo!検索を自動化する」に変える
このドラッグドロップを○に変える
初期化開始する
ウェブブラウザ1というウェブブラウザを作る
その位置と大きさを{0,0,1150,729}に変える
そのアドレスを「https://search.yahoo.co.jp/」に変える
そのドッキング方向を「全体」に変える
初期化終了する
この設計スケール比率を{144,144}に変える
終わり
ウェブブラウザ1のページが読み込まれた時の手順
もしウェブブラウザ1のアドレスが「https://search.yahoo.co.jp/」でなければ返す
//2019年11月現在は次の通りで検索バーから検索できます。
対象要素は、ウェブブラウザ1のページ
対象要素から「form」という要素を取得したもののすべてのform要素についてそれぞれ繰り返す
もしform要素から「role」という属性値を取得したものが「search」なら
form要素の「p」へ「プロデル」という値を設定する
form要素を送信する
繰り返しから抜け出す
もし終わり
繰り返し終わり
終わり
終わり
ログイン後のページから抽出する
Yahoo!ショッピングでお気に入りに登録した商品一覧を取得するプログラムを作ってみます。
お気に入りリストは、Yahoo!にログインしないと見られません。そこで、ログイン画面に遷移したら、IDとパスワードを設定してログインボタンをクリックするプログラムを作ってみます。
次のようなロジックで作ってみます。
- Yahoo!内の閲覧したいアドレスへアクセスする
- ログインしていない場合、Yahoo!ログイン画面( https://login.yahoo.co.jp/ )へ自動的に遷移するので、ログイン画面へ遷移したら、ID,パスワードを自動入力して送信ボタンを押す
- 目的のページへ自動的に遷移するので、そのページから欲しい情報を抽出する
基本的には、検索フォームでキーワード検索させるのと同じ方法でIDとパスワードを埋めていきます。ただ2019年12月時点のYahoo!のログイン画面は、IDを入力で[次へ]ボタンをクリックし、パスワードを入力してログインするという2段階のボタン操作が必要ですので、操作するべきHTML要素がたくさんあります。
こちらでテストした時は、正しくログインできることを確認しましたが、2段階認証を設定している場合や、画像認証が必要な場合などは、今回の方法ではログインできません。あらかじめ手動でログインしておく必要があります。
YahooID=「」
Yahooパスワード=「」
//自動ログイン
メインウィンドウを表示する
待機する
メインウィンドウとは
ウィンドウを継承する
はじめの手順
初期化する
ーー貼り付けた部品に対する操作をここに書きます
終わり
初期化する手順
ーー自動生成された手順です。ここにプログラムを書き加えても消える場合があります
この実質大きさを{1150,729}に変える
この内容を「Yahoo!の自動ログイン」に変える
このドラッグドロップを○に変える
初期化開始する
ウェブブラウザ1というウェブブラウザを作る
その位置と大きさを{0,0,1150,729}に変える
そのスクリプトエラー表示を○に変える
そのアドレスを「https://shopping.yahoo.co.jp/my/wishlist/item/」に変える
そのドッキング方向を「全体」に変える
初期化終了する
この設計スケール比率を{144,144}に変える
終わり
ウェブブラウザ1のページが読み込まれた時の手順
対象ページは、ウェブブラウザ1のページ
もしウェブブラウザ1のアドレスが「https://login.yahoo.co.jp/」で始まるなら
//2019年12月現在は次の方法でYahoo!にログインできます
//ユーザ名
対象ページから「username」というID要素を取得してユーザ名要素とする
もしユーザ名要素が無なら返す
ユーザ名要素の値は、YahooID
//次へ
対象ページから「btnNext」というID要素を取得して【次へボタン要素】とする
次へボタン要素をクリックする
対象ページから「inpUsernameBox」というID要素を取得して入力ユーザ名要素とする
繰り返す
0.1秒待つ
もし入力ユーザ名要素の内容が「」でなければ繰り返しから抜け出す
繰り返し終わり
//パスワード
対象ページから「passwd」というID要素を取得してパスワード要素とする
パスワード要素の値は、Yahooパスワード
//送信
対象ページから「btnSubmit」というID要素を取得して送信ボタン要素とする
送信ボタン要素をクリックする
そうでなければ
//Yahoo!ショッピングのお気に入り一覧を調べる
対象ページから「favitem」というID要素を取得して【お気に入り要素】とする
もしお気に入り要素が無でないなら
ウェブブラウザ1のアドレスを報告
お気に入り要素から「a」という要素を取得したもののすべてのa要素についてそれぞれ繰り返す
a要素の内容を報告する
繰り返し終わり
もし終わり
もし終わり
終わり
終わり
他のWebブラウザを使えないか
残念ながらプロデルではIEのレンダリングエンジンを使ったコンポーネントを利用しているため、IE9相当の表示となります。レジストリを変更するとで、IE11相当に切り替えることもできますが、IEを全く考慮していないサイトではうまく抽出できないかもしれません。
なおプロデルEdgeプラグインを使うことで、EdgeHTMLのレンダリングエンジンを利用できるので、個人利用であればこちらがおすすめです。
さらに、将来、Chromiumベースの次世代Edgeのコンポーネントが提供されれば、それらに対応できるかと思います。
まとめ
プロデルのウェブブラウザ部品を使って、ページの特定の要素を取得したり、フォームを自動操作する方法を紹介しました。プログラムを作る前に、目的のサイトのHTMLの構造を理解する必要がありますが、HTMLの解析処理やセッション管理のプログラムを書くことなく気軽にウェブスクレイピングすることができるかと思います。