機械学習のジャンル
機械学習を一から始めてます。勉強で自分なりに解釈をしております。間違っているところがありましたらお伝えしてくださると幸いです。
教師あり学習
入力と出力のペア群から学習するアルゴリズムである。なぜ教師となるかというと学習のために与えられる入出力ペア群がある意味先生となるからである。アルゴリズムは入力から望ましい出力を生成する方法を発見する。
封筒に書かれた手書きから郵便番号を読み取るのも入力から望ましい出力を生成する方法を見つけて照合する事によって可能になる。
教師なし学習
入力データだけが与えられていて出力データはアルゴリズムに与えられない。だからこれと言った答えが導かれないようなものである。
例えば顧客をグループに分けるときもジャンルはある程度決まっているものもあるが新しいユーザが来るたびにジャンルは更新していくというように正確な答えというものはあまりない。
まとめ
教師あり・なしに関わらず入力データを計算きが理解できる形で表現することが重要である。
データ(=テーブル)と考え、それぞれのデータポイント(個々のメール、個々の顧客)が行となり、データポイントを記述する個々の特性は列(顧客の年齢、トランザクションが行われた場所とか)となる。この時この行に当たる部分をサンプル(=データポイント)と呼び、列を特徴量という風に呼ぶ。
扱っているデータと解決しようとしている問題とデータとの関係を理解することだ。適当にアルゴリズムを選んでデータを投げ込むというようなことをしては望んでいるような結果が適当にやっているわけであるから良い値が返ってこない。
必要なライブラリとツールについて
Jupyter Notebookについて
使い方について説明する。
(1)Anacondaのアプリを開く
(2)Jupyter NotebookのLaunchをタップする
(3)右上にある新規をタップしてPython3をタップする
それで完了となる
操作方法
入力
入力の横にある細長い空欄をタップして自分の実行するしたいコードを入力できる
再生ボタン
入力としたものを実行したいときはこのボタンを押すと可能になる。
Numpyについて
Numpyは大学とか高校で使うようなレベルの高い数学を使うことができる。よくNumpyをインポートするときにはいちいちNumpyと打ち込むのは面倒なのでnpとしてやっていく。一つの例として三角関数について説明していく。他にもいっぱいあるのでぜひNumpyと調べてみてください!
import numpy as np
list_1 = np.array([[1, 2, 3], [4, 5, 6]])
print(list_1)
# 実行結果
[[1 2 3] [4 5 6]]
三角関数
import numpy as np
np.sin(0)
# 実行結果
1
np.sin(45)
# 実行結果
0.8509035245341184
Scipy
線形代数ルーチンや数が奇関数の最適化、統計分布などを行う。こちらでは例として積分をやってみたいと思う。
結果, 誤差 = integrate.quad(積分したい関数, x, y(x~yが積分区間))
from scipy import integrate
def math_func1(x):
return x**3 + x + 3
result, missing = integrate.quad(math_func1, 0, 1)
print("結果は", result, "誤差は", missing)
# 実行結果
結果は 3.75 誤差は 4.163336342344337e-14
matplotlib
このライブラリはグラフを書くことができる。要はデータを可視化することができるのだ。%matplotlib inlineを用いることによって図をブラウザに直接図示することが可能になる。今回は先ほどしました関数を図示する感じで使ってみる
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-1000, 1000, 100000)
def math_func1(x):
return x**3 + x + 3
y = math_func1(x)
plt.plot(x, y, marker="x")
実行結果はこのようになるであろう。このようにして図示することができるため非常に便利なツールである。

pandas
データを変換したり解析したりするためのツールである。この中で代表的なライブラリとしてDateFrameというものが存在する。これは表のようなものであり、テーブルを変更する関数などの手法が掲載してある。pandasの長所としては列ごとに異なる型でも良い。小数と整数というペアも可能になる。また、エクセルのファイルやSQLのデータベース、CSVファイルからデータを取り込むことが可能であるところも長所の一つである。
import pandas as pd
from IPython.display import display
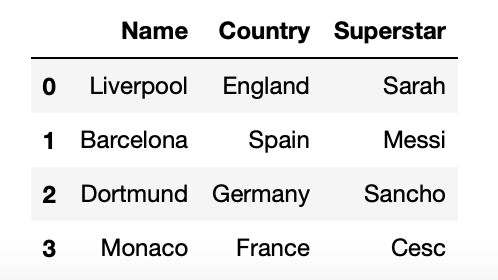
soccer_information = {'Name':['Liverpool', 'Barcelona', 'Dortmund', 'Monaco'],
'Country':['England', 'Spain', 'Germany', 'France'],
'Superstar':['Sarah', 'Messi', 'Sancho', 'Cesc']}
soccer = pd.DataFrame(soccer_information)
display(soccer)
mglearn
こちらに関してはグラフの絵やデータのロードを読みにくくならないようにするものである。
詳細については調べてくださると幸いです
この記事は「Pythonで始める機械学習」から一部引用しております。
こちらの本は参考になるのでもし宜しかったらご購入を検討してみてください!
また順番においてもこちらの書籍を参考にしております。