こちらの記事は、AWS Analytics Advent Calendar 2024 の 3 日目のエントリーです。
2024年10月30日、Amazon Redshift の新機能として、Amazon Redshift ML integration with Amazon Bedrock が発表されました。
ざっくりどういったものか?
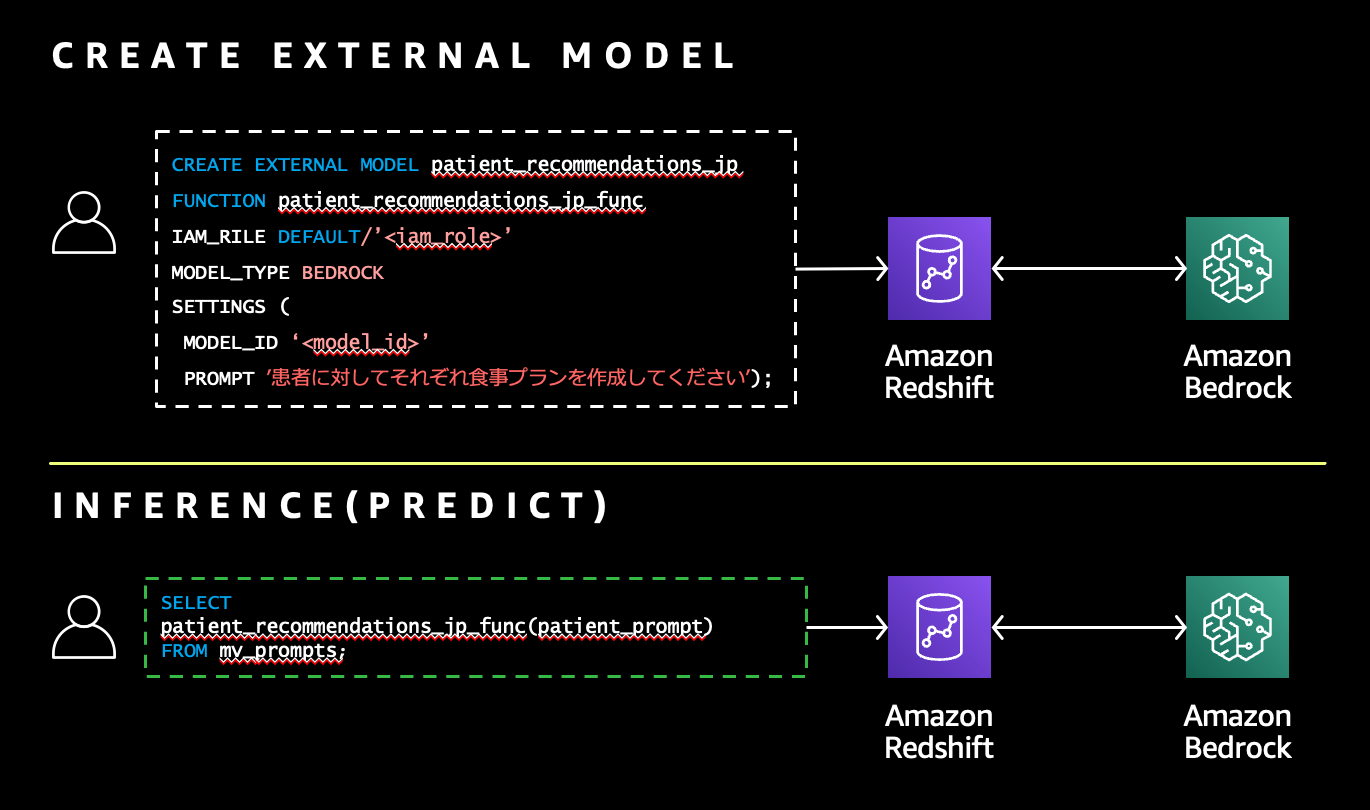
この機能は、Amazon Redshift 上のデータに Amazon Bedrock のサポートする LLM を活用して生成 AI 的タスク (言語翻訳、テキスト生成、要約、顧客分類、感情分析など) を SQL で実行可能とするものです。
具体的には、以下のステップで利用します。
- CREATE EXTERNAL MODEL 構文にて、Bedrock 上で有効化済の任意の LLM の Model ID と、与えたいプロンプトを定義した Function (推論関数) を作成する
- 作成された Function を用いて、テーブルデータを引数として与え、結果を出力する
いわば、Redshift に SQL ベースの生成 AI アプリケーションが組み込まれているともいえるでしょう。
今回は、機能リリースと同時期に AWS BigData Blog に Publish された以下のブログの記事を参考にしながら、日本語データを用いてこの機能がどのように利用できるかサクッと試してみます。
事前準備
-
Redshift クラスターを用意
今回は、バージニアリージョン (us-east-1) にデフォルト設定で立ち上げ済の Redshift Serverless を使用します。
-
Redshift Serverless にアタッチする IAM role に Bedrock のポリシーを追加
Redshift から Bedrock にアクセスができるように、Redshift Serverless 名前空間にアタッチされている IAM Role である AmazonRedshift-CommandsAccessRole-xxx に、AmazonBedrockFullAccessの許可ポリシーを追加します。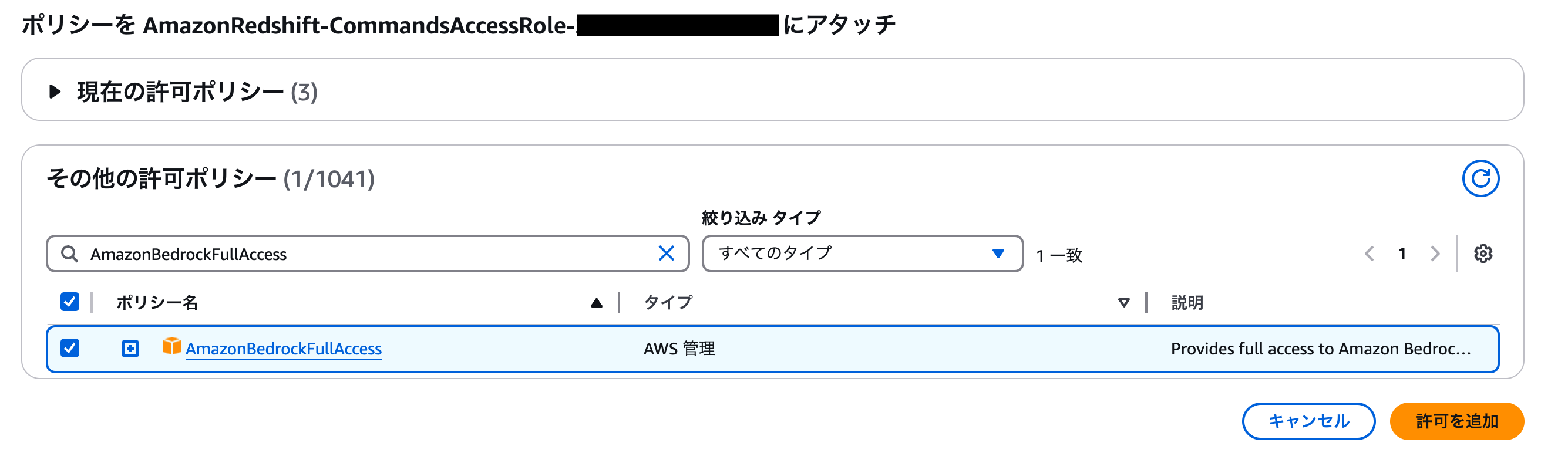
-
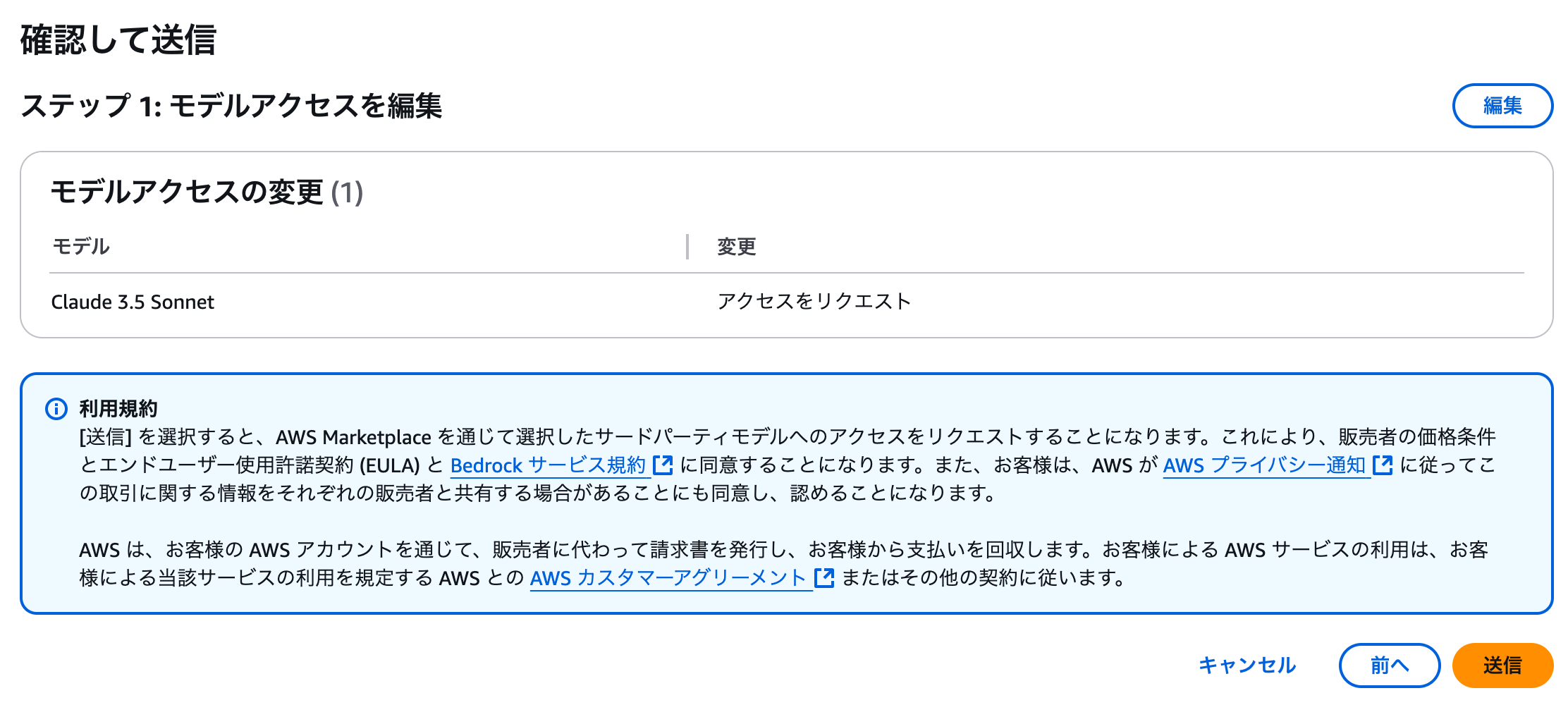
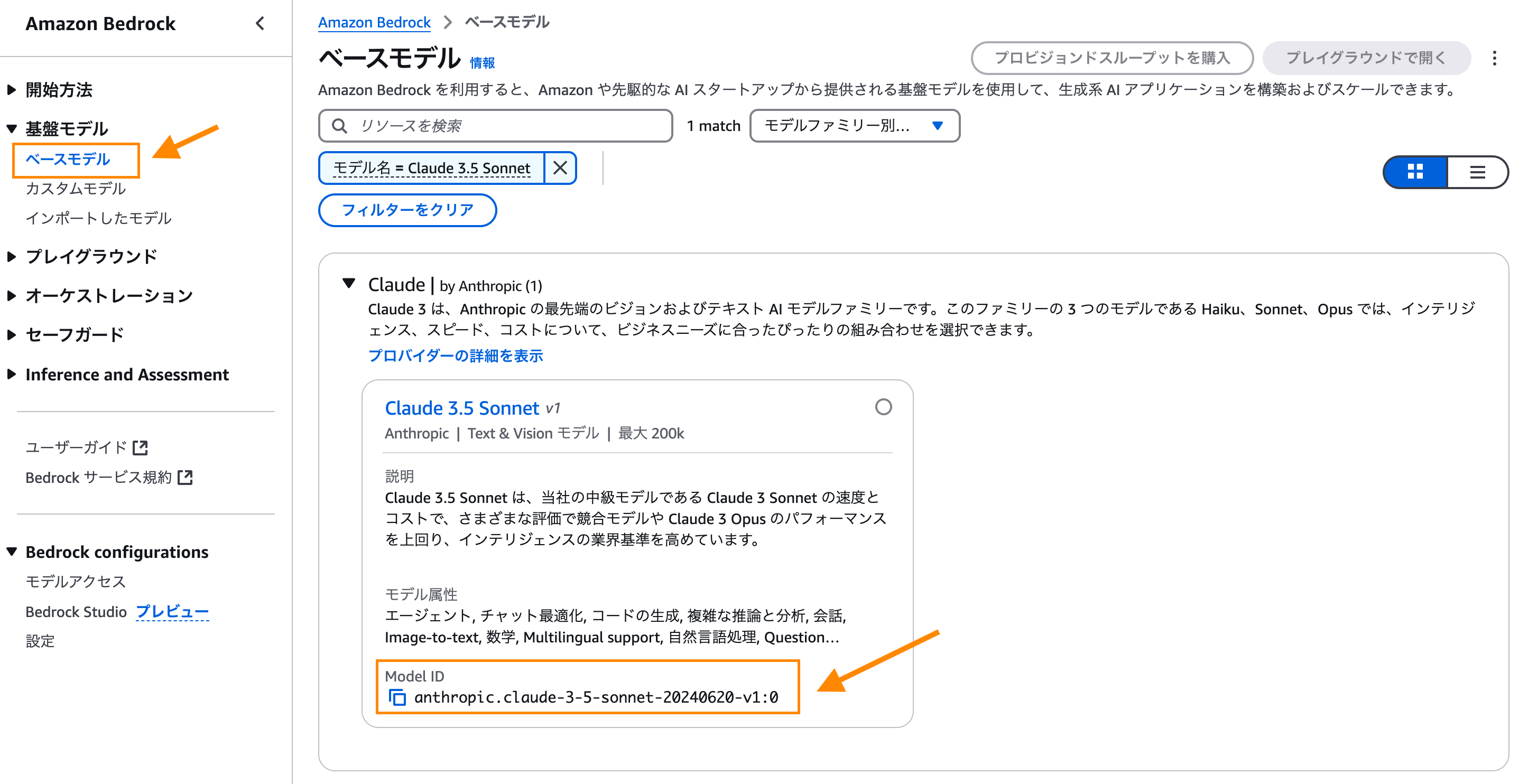
Bedrock で利用するモデルアクセスを有効化
Redshift から呼び出す LLM のモデルアクセスを有効化します。

今回は、
Claude 3.5 Sonnetを利用しようと思うので、さっそく有効化を進めます。


有効化された Claude 3.5 Sonnet の Model ID:
anthropic.claude-3-sonnet-20240229-v1:0を後段で使用します。
以上で事前準備は完了です。
How it works
患者の名前と症状、処方についての情報が入った Redshift 上のテーブルを読み込んで、「それぞれの患者に最適な食事プラン」を出すような推論処理を SQL で実行したいと思います。
ここからは、Redshift のクエリエディタ v2 を使用して操作をしていきます。

テーブルの作成
患者の名前と症状、処方についての情報が入ったテーブルを作成します。
CREATE TABLE patientsinfo_jp (
pid integer ENCODE az64,
pname varchar(100),
condition character varying(100) ENCODE lzo,
medication character varying(100) ENCODE lzo
);
[結果サンプル]

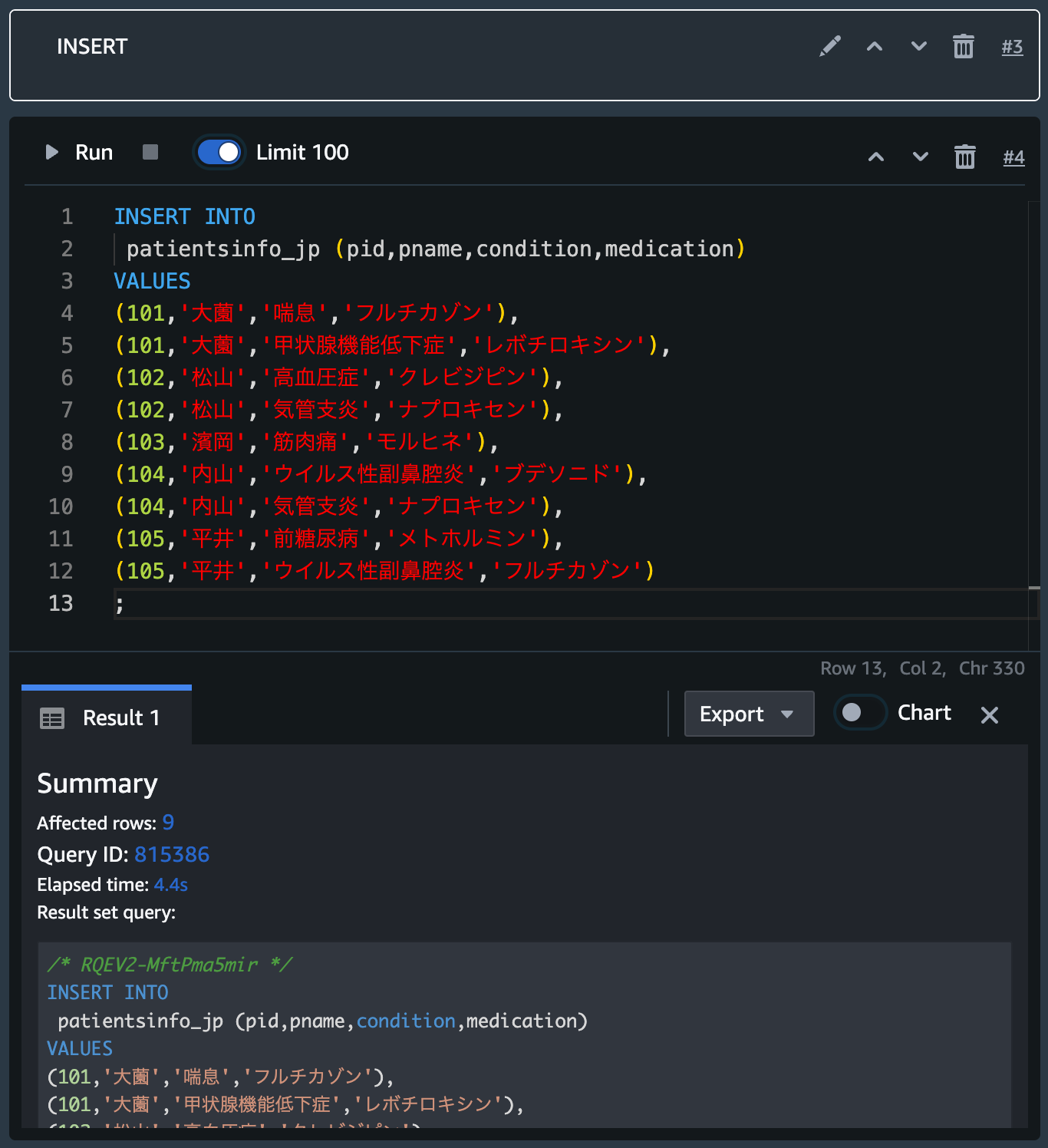
データの挿入
サンプルデータを挿入します。
INSERT INTO
patientsinfo_jp (pid,pname,condition,medication)
VALUES
(101,'大薗','喘息','フルチカゾン'),
(101,'大薗','甲状腺機能低下症','レボチロキシン'),
(102,'松山','高血圧症','クレビジピン'),
(102,'松山','気管支炎','ナプロキセン'),
(103,'濱岡','筋肉痛','モルヒネ'),
(104,'内山','ウイルス性副鼻腔炎','ブデソニド'),
(104,'内山','気管支炎','ナプロキセン'),
(105,'平井','前糖尿病','メトホルミン'),
(105,'平井','ウイルス性副鼻腔炎','フルチカゾン')
;
[結果サンプル]
データの確認
SELECT * FROM patientsinfo_jp;
[結果サンプル]

テーブルデータを自然言語に加工
このテーブルの各列の情報を使って、Bedrock へのプロンプト入力用の自然言語を作成し、データとして保持したいと思います。
一つの VARCHAR などにテキストが格納されているような列があるわけではないので、各列を連結してその行が表すデータの意味をなんとか自然言語にしたいと思います。
各列の値を連結するには、LISTAGG 関数が便利です。
LISTAGG を駆使した加工 SQL を作ってマテリアライズドビューを作成したいと思いますが、作成前に加工内容を確認してみます。
SELECT
pname || 'は' || conditions || 'のため' || medications || 'を服用しています' as patient_prompt
FROM (
SELECT pname,
listagg(distinct condition,'と') within group (order by pid) over (partition by pid) as conditions,
listagg(distinct medication,'と') within group (order by pid) over (partition by pid) as medications
FROM patientsinfo_jp)
GROUP BY 1;
[結果サンプル]
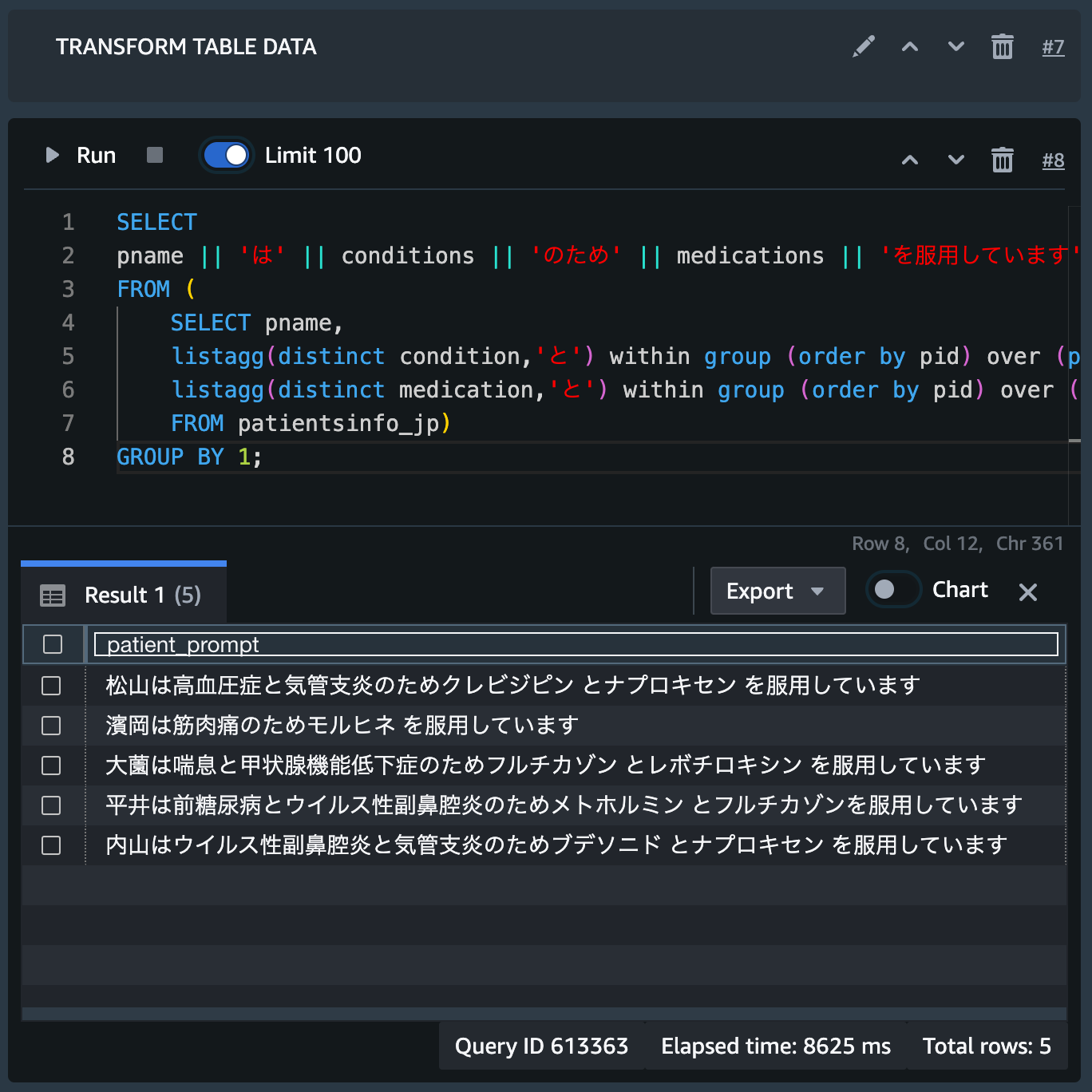
たとえば、「大薗さんが喘息と甲状腺機能低下症のためフルチカゾンとレボチロキシンを服用している」という自然言語ができました(※フィクションです)
データとしてはよさそうなので、このデータを Bedrock に引き渡すために、専用のマテリアライズドビューを作成したいと思います。
マテリアライズドビューの作成
AS 句以降に先程の SQL を指定し、CREATE MATERIALIZED VIEW を実行します。
※ Incremental refresh がサポートされない構文である旨の Warning が出ますが、無視して問題ありません。
CREATE MATERIALIZED VIEW mv_prompts_jp AUTO REFRESH YES
AS
(
SELECT pid,
pname || 'は' || conditions || 'のため' || medications || 'を服用しています' as patient_prompt
FROM (
SELECT pname, pid,
listagg(distinct condition,'と') within group (order by pid) over (partition by pid) as conditions,
listagg(distinct medication,'と') within group (order by pid) over (partition by pid) as medications
FROM patientsinfo_jp)
GROUP BY 1,2
);
[結果サンプル]
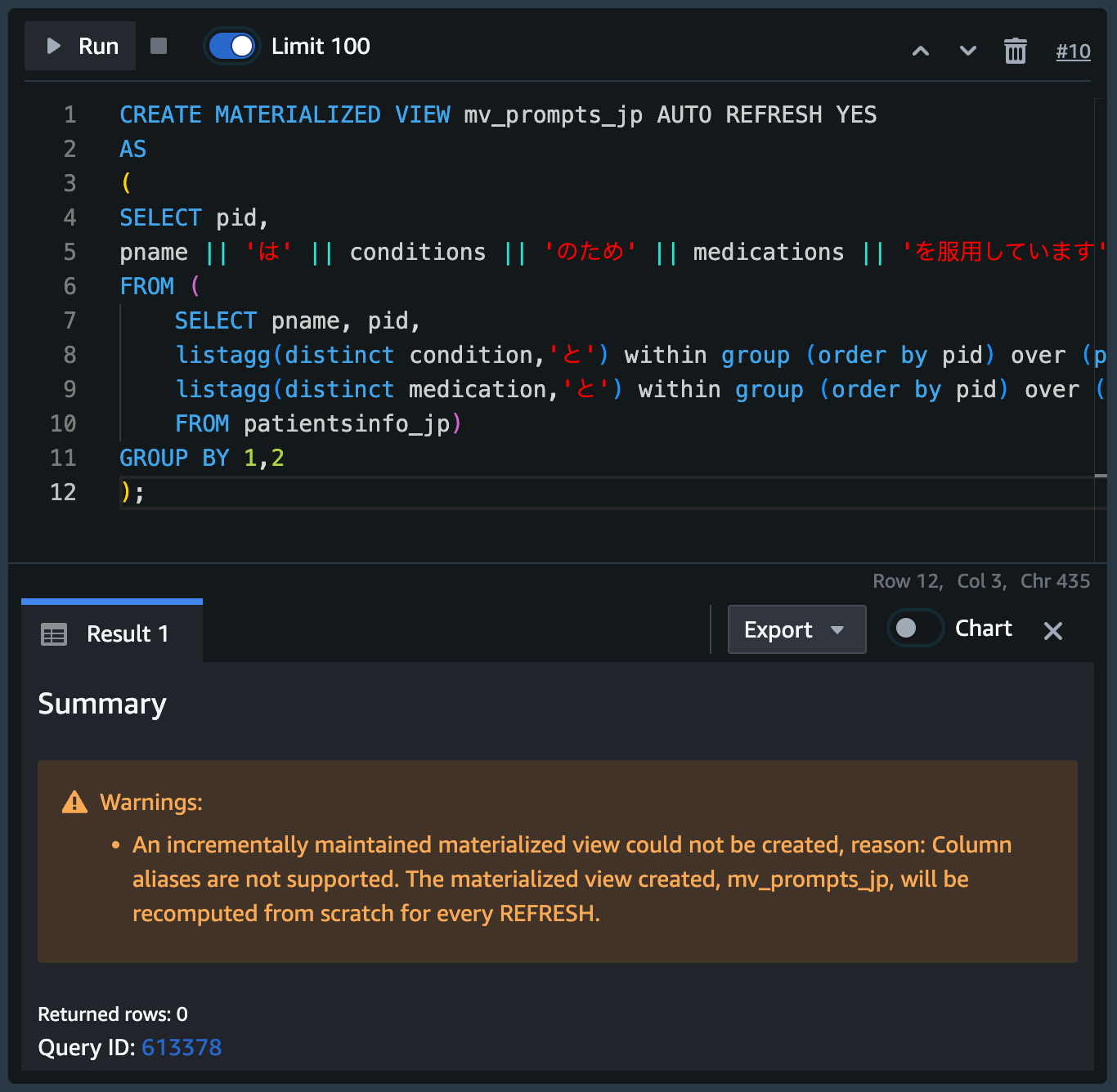
これで、ベーステーブルが更新されたらこちらも自動でリフレッシュされるようになります。
Bedrock の LLM を Call する External Model を作成
ようやくここまできました。
CREATE EXTERNAL MODEL を実行します。
Model ID には事前準備で確認した Claude 3.5 Sonnet の Model ID を指定します。
プロンプトとして、"患者に対してそれぞれ食事プランを作成してください" と指定します。
CREATE EXTERNAL MODEL patient_recommendations_jp
FUNCTION patient_recommendations_jp_func
IAM_ROLE DEFAULT
MODEL_TYPE BEDROCK
SETTINGS (
MODEL_ID 'anthropic.claude-3-sonnet-20240229-v1:0',
PROMPT '患者に対してそれぞれ食事プランを作成してください:');
[結果サンプル]

この結果、モデル patient_recommendations_jp および推論関数 patient_recommendations_jp_func が作成されます。
推論関数の実行
推論関数を実行し、Bedrock の LLM を呼び出してそれぞれの患者の食事プランを作成してもらいます。
やっていることは、CREATE EXTERNAL MODEL で作成した 推論関数 patient_recommendations_jp_func の引数にマテリアライズドビューのカラム情報 patient_prompt を渡すだけです。
SELECT patient_recommendations_jp_func(patient_prompt)
FROM mv_prompts_jp ;
[結果サンプル]
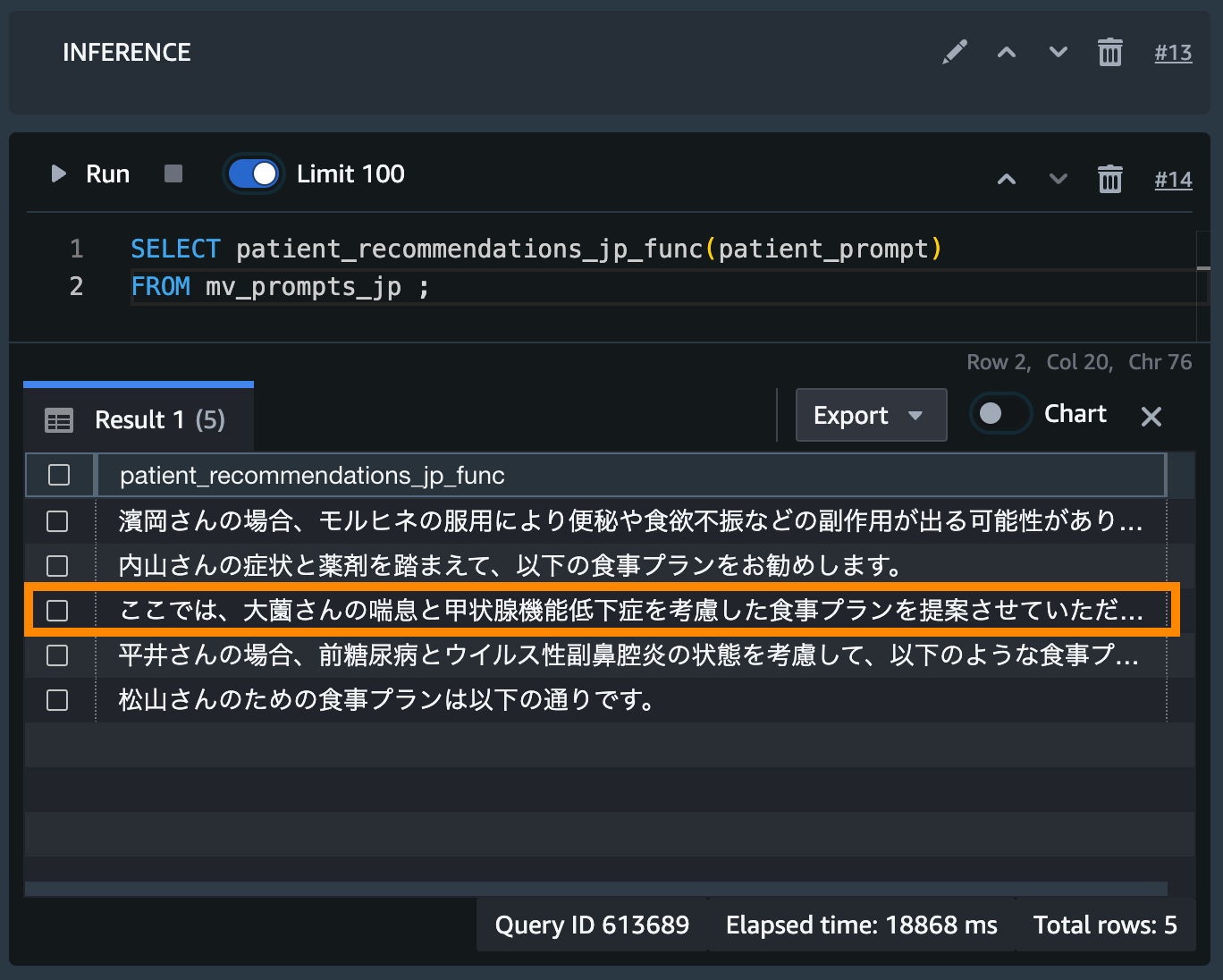
クエリエディタ上では見切れてしまうため、CSV に Export して、中身を確認してみます。
ここでは、大薗さんの喘息と甲状腺機能低下症を考慮した食事プランを提案させていただきます。
1. 抗炎症食材を積極的に取り入れる
・魚介類(EPA、DHAが豊富)
・緑黄色野菜(ビタミンC、カロテノイドが豊富)
・大豆製品(イソフラボンが豊富)
・オリーブオイル(オレイン酸が豊富)
2. ヨウ素を多く含む食材を意識する
・海藻類(わかめ、昆布など)
・卵
・乳製品
3. 食物繊維を意識する
・野菜
・果物
・全粒穀物
4. 刺激物は控えめに
・香辛料、アルコールは控えめ
5. 適度な運動と十分な休息
このように、抗炎症作用のある食材を中心に、ヨウ素と食物繊維も意識した食事プランを立てることが大切です。併せて適度な運動と休息をとり、ストレス管理にも気をつけましょう。
大薗さんの状況に合わせて、とても素晴らしい食事プランを提案してくれていることが分かります!
まとめ
- Amazon Redshift ML integration with Amazon Bedrock は、Bedrock がサポートする LLM を呼び出すモデルと関数を Redshift SQL で簡単に作成できます。
- Redshift 上のテーブルデータを Bedrock に連携し、生成 AI 的タスクを SQL で実行できます。
- 当然ですが生成 AI 的な処理は Bedrock 側で行っているため、日本語の取り回しもバッチリでした。