この記事は「エムスリー Advent Calendar 2016」の 19日目の記事です。
はじめに
社外に出せないプロダクトの実装例として社内勉強会で発表した内容ですが、気に入ったのでまとめなおしました。要はlazy loadなのですが、RxJSとIntersectionObserverとその組み合わせで、最強のlazy loadを構築した話です。
ところで、強さとは優しさのことですね。世界を平和に導く最強のlazy loadを構築した話とはつまり、みんなにやさしいlazy loadを構築したという話です。
みんなにやさしい
みんなとは
- ブラウザ
- サーバー
- ユーザー
のことを指します。つまり、ブラウザにもサーバーにもユーザーにもやさしくなければいけません。どれか1つが欠けてもだめです。
目指すもの
これが完成形のデモです。中身は意味のないものですが、要素技術や機能は実際のプロダクトと同じものです。
https://run.plnkr.co/EDqCiJ2tKLGNEZfG/
(jsxを毎回コンパイルしていて時間がかかるのか、plunkrが機能しない場合がありますが、読込に失敗する場合は何回かリロードすれば読み込めるはず)
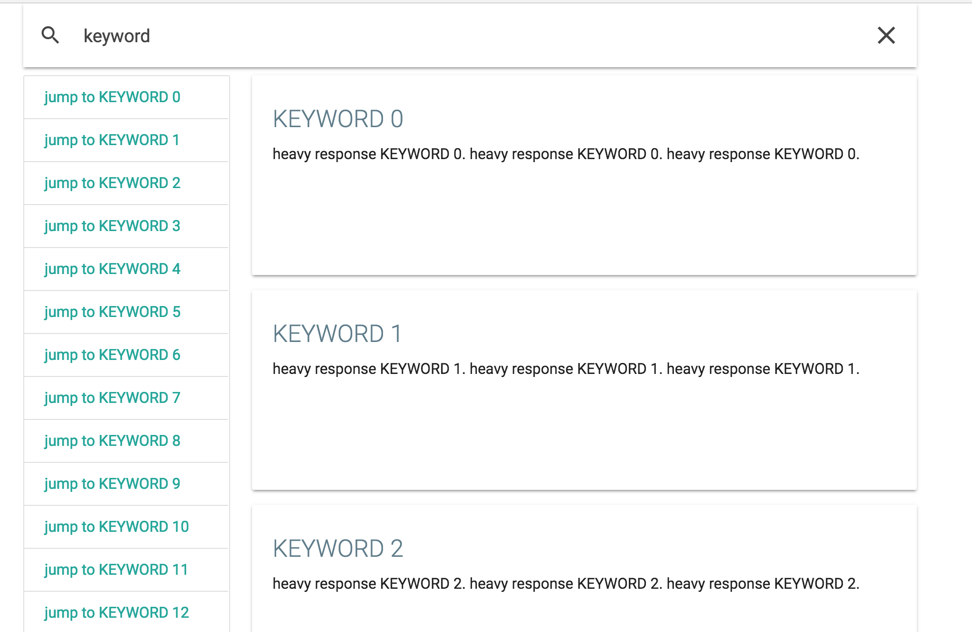
機能
- 検索キーワードを入れるとそれに応じた索引を取得、左側に表示
- 索引をクリックすると右側の該当項目に飛ぶ
- 右側はスクロールできる
機能のポイント
- 以前は、左側の索引をクリックするとその項目を1つだけ右側に表示するという、単純なSPAらしい機能でした。この詳細をスクロールで見たいという話になったのがきっかけ。
- 一覧をクリックすると該当項目にジャンプできる。これが曲者で、単純な無限スクロールと相性が非常に悪い。
- (実際のプロダクトで) 各項目のロードはかなり重い。これは根が深くすぐには直せない。
すぐ思いついたのは無限スクロールだったのですが、上方向への無限スクロールが曲者で、ジャンプ機能と相性が悪いので不採用。今回はlazy loadを採用しました。
上方向への無限スクロールをガタつかずに綺麗にやるやり方をわかる方、あるいはもっとこういうのがイケてるとかあれば教えてください。
実装
https://plnkr.co/edit/YjruCGWHPQFOe8drqHaw?p=preview
(editorのpreviewではなぜか動きが怪しいので、別窓でのプレビューがオススメです)
各コンポーネントの概要
以下のような構成になっています。
-
LazyLoadableアプリケーション全体のcontainer component-
SearchBarキーワード入力フォーム -
Index左カラムの索引 -
Items右カラムの詳細一覧-
Item個別の詳細
-
-
では、上記の機能をどうやってみんなにやさしいやり方で実装したか、それぞれ見ていきます。
ブラウザにやさしい
TL;DR
IntersectionObserverを使う
解説
lazy loadの肝、DOMが表示されたことの判定に、 IntersectionObserverを使います。
従来この手のイベントを取得するためには、呼び出し頻度の高いonscrollでレイアウト処理を必要とするoffsetTopを呼ぶなど、layout thrashingを起こしやすい高負荷な処理でした。
これを上手いこと非同期でユースケースに特化した用途に使えるAPIとして登場したのがIntersectionObserverです。あるDOMとあるDOMやview portとの重なりを検知するAPIになっていて、lazy loadにはうってつけな他、広告画像の表示判定にも使えるようです。ブラウザのネイティブAPIとして非同期に呼ばれるため、従来のようなヘビーな処理になりづらくなっています。ブラウザにやさしいですね。
このへんの話はふろしきさんのこの記事に経緯等含めよくまとまっています。なお、まだExperimentalで実装されていないブラウザも多いので、WICGから出ているpolyfillを当てておくのが無難でしょう。
デモ実装では、Items#newObserverでIntersectionObserverを作成し、個別のItem#componentDidMountで個別のItem(のDOM)をobserveしています。
class Items extends React.Component {
...
newObserver() {
// コンストラクタに、接触/離脱(?)時に呼ばれるコールバックを指定する。
return new IntersectionObserver(entries => {
// 一回のバッチ処理で、衝突/離脱したDOM同士をIntersectionObserverEntryとして、リストが引数に渡される。
entries.forEach(entry => {
const target = entry.target;
// entry.intersectionRatio が衝突割合。0 なら離脱した。
if (0 < entry.intersectionRatio) {
target.dispatchEvent(new Event('appeared'));
} else {
target.dispatchEvent(new Event('disappeared'));
}
});
}, {
root: ReactDOM.findDOMNode(this),
// rootMarginを指定することで、衝突範囲を従来のDOMより大きくできる。
rootMargin: '100px'
});
}
...
observe(target) {
this.state.observer.observe(target);
}
...
}
class Item extends React.PureComponent {
...
componentDidMount() {
const el = ReactDOM.findDOMNode(this);
el.addEventListener('appeared', () => this.onAppeared());
el.addEventListener('disappeared', () => this.onDisappeared());
// このonComponentDidMountで`observe`している。
this.props.onComponentDidMount(el);
}
...
}
実装していて1つあまり綺麗にいかなかった部分が、observeするタイミングではDOMしか渡せず、個別のコールバックを指定できないことです。コールバックをIntersectionObserverのインスタンス作成時にしか指定できないので、observeの対象毎に挙動を変えられません。つまり、ItemAが衝突したときにItemAのlazy loadを開始するという処理が素直に書けませんでした。
デモではこれの回避策として、衝突時にDOMにイベントを流して各ItemがaddEventListenerすることで間接的にコールバックを実行しています。
なお、実際のプロダクトでは各Item毎にIntersectionObserverのインスタンスを作ることで個別のコールバックを実装しています。
// 個別のItem内で
const el = domOfThisItem();
const io = new IntersectionObserver(entries => {
entries.forEach(entry => {
// このコールバックはこのItem限定
});
}, {
root: el.parentNode
});
io.observe(el);
前者は謎のおれおれイベントを流すことになり、後者は素直にコールバックが書けますが、rootが同じIntersectionObserverが複数存在し、1つしかありえないのに複数想定のentriesを扱うなど微妙な部分があります。
どうしたら綺麗になるんだろう?良いアイデアあれば教えて頂きたいです。
まとめ
-
IntersectionObserverを使うことで、従来のスクロールでのコールバックで発生していた負荷を低減しました。 - ただしAPIは若干小回りが効かないので、今後の改善に期待。
サーバーにやさしい
TL;DR
Rxの以下のオペレータを使う
-
debounceTimeでインクリメンタルサーチを制御する -
mergeMapで非同期通信を制御する - switchMapで綺麗に片付ける。
解説
複数言語で実装されているストリームライブラリとして有名なRxを使います。
Rxのことは説明しだすと長くなるので、細かいことはあまり説明しません。私なりに一言で説明すると、非同期に流れるデータを、ストリームとして上手いことパイプ処理できるライブラリです1。
Rxの世界のストリーム2に対して、例えば「2つのストリームを合成して1つのストリームにする」などといった操作(operatorと呼びます)を行うことで複雑な非同期処理を綺麗に扱うことができます。
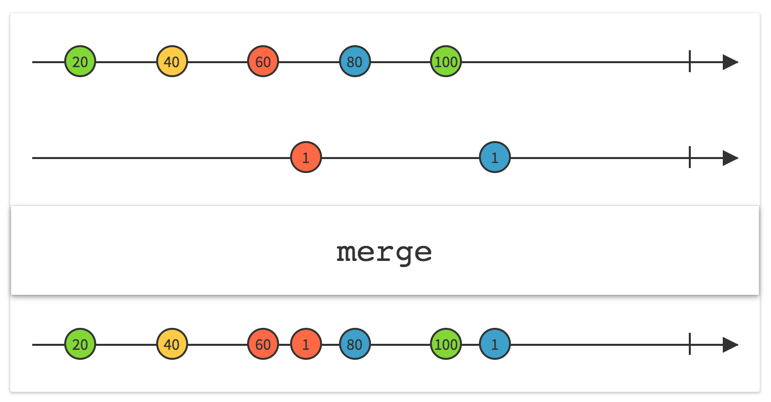
(2つのストリームを1つに合成するmergeの図 http://reactivex.io/documentation/operators/merge.html)
Rxやリアクティブプログラミングのイメージをつかむには以下の記事がオススメです。
【翻訳】あなたが求めていたリアクティブプログラミング入門(http://ninjinkun.hatenablog.com/entry/introrxja)
なお、現在最新のRxJSはrxjs5 (https://github.com/ReactiveX/rxjs) として別リポジトリで管理されており、使用するオペレータ等の名前に旧来のものから一部変更があります。デモでは最新のrxjsを使用しています。
デモでは、Rxの使用は全てLazyLoadableというcontainer componentに閉じています。ここにサーバーにやさしい様々な処理が詰まっているのですが、この記事では以下の3つのオペレータに注目して、詳しく見ていきます。
- debounceTime
- mergeMap
- switchMap
では、個別に見ていきます。
(補足: デモ実装では、Rxのストリームを表す変数に$というsuffixをつけています。これはCycle.jsというRxと相性の良いライブラリで使用しているルールで、Streamの"S"で$だそうです。ぱっと見でストリームを識別しやすいので、同じ命名を採用しています。
debounceTime (旧 debounce)
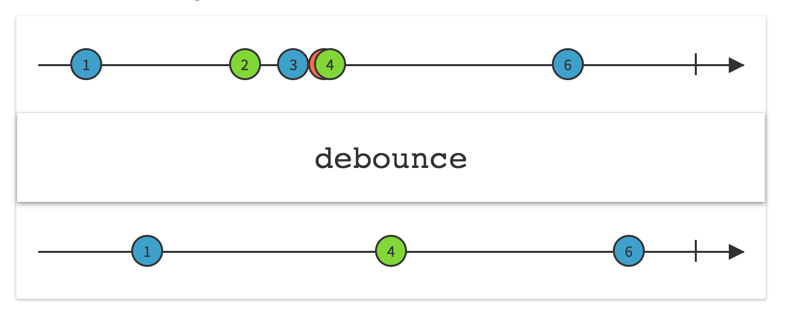
http://reactivex.io/documentation/operators/debounce.html
まずはわかりやすいところから。debounceTimeです。これは、ストリームを流れる連続したぐちゃっとした要素の最後だけを使用するオペレータです。デモではキーワード入力に対してdebounceTimeを使用しています。
class LazyLoadable extends React.Component {
...
newItems$(keyword$) {
...
// 300msの間に次の値が流れてきた場合、それを無視する。
this.keyword$.debounceTime(300).switchMap(keyword => {
...
}
...
}
デモでは、キーワード入力に反応してリアルタイムに索引が変更されますが、この索引は非同期通信を想定しています。例えばキーワードにcatと入力したときに、実際にはc, ca, catというonChangeイベントが3つ飛んでしまいますよね。ユーザーからしたら、最後のcatの検索結果しか必要ないのにこの3つすべてに対してAPIコールを行うのは無駄にサーバーへのリクエストを増やすことになります。catくらいだったら良いですが、jsldfkjs;kdjfa;kejfo;aiwjef;lskjdfと無茶苦茶にキーボードを叩かれると、ユーザーには悪意がなくてもDOS攻撃のようになってしまいます。debounceTimeを使うことで、指定したms以下の間隔であればどれだけ打っても最終的なキーワードだけを使用することができます。
mergeMap (旧 flatMapWithMaxConcurrency)
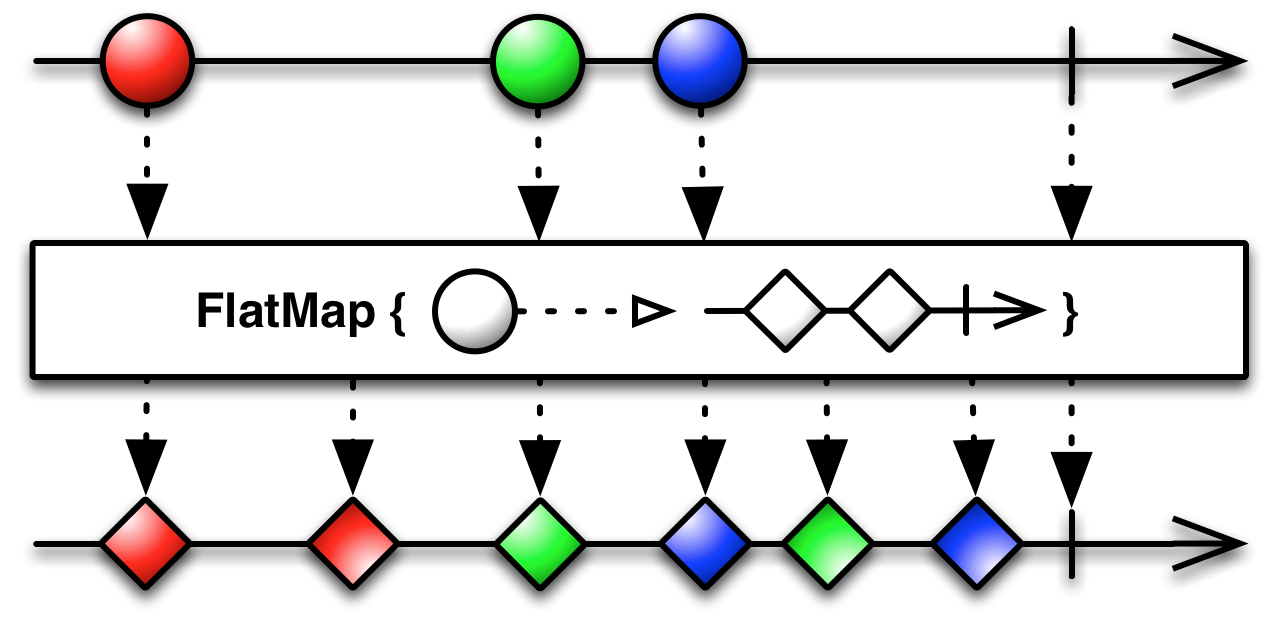
ストリームの中を流れるストリームの値をflatにして返す、いわゆるflatMapな処理をしてくれます。rxjs5ではmergeMapという名前になりました。
これを使って、複数のajaxコールなどの非同期処理(それぞれが独立したストリーム)の結果を1まとめに扱うことができます。このオペレータの素晴らしいところは、concurrencyを引数で指定できることです。つまり、ajaxコールの並列実行数を指定するようなことができるのです。
class LazyLoadable extends React.Component {
...
newItems$(keyword$) {
// 4並列を想定
const concurrency = 4;
...
// { $key: data } の形のMapが都度流れるストリーム
const keyToData$ = lazyLoad$
// this.fetchItem$() の戻り値は、[key, response]が流れるRxのストリームになっています。
// ストリームのストリームになるので、mergeMap を使うことで直列化。
// concurrencyを引数で指定します。
.mergeMap(key => this.fetchItem$(key), concurrency)
// fetchItem$ の結果が [key, response] の形で流れて来るので、{ $key: response }のMapになるように畳み込んでいきます。
// scanはreduceやfoldのような畳み込み処理を行うオペレータ。
.scan((map, [key, data]) => map.set(key, data), new Map())
// ここのshareは超重要ですが、今回は関係ないので説明を省略します。
// 「このストリームは複数箇所で使われる」くらいに思っておいてください。
.share();
...
}
...
}
今回、索引から個別項目にジャンプできる機能があることによって、未ロード状態の個別項目も、中身は空ですが全て最初から表示されています。いわゆる無限スクロールのように段階的に表示させることができないため、これをconcurrencyなどの制御なしに一気にスクロールしたらすごい数の項目が表示、ロードされる可能性があり、これもまた無邪気なDOS攻撃になってしまう恐れがあります。どんなに無茶苦茶なスクロールをしても最大のconcurrencyを引数だけで指定できる安心感は、エンジニアにもやさしいですね。
switchMap (旧 flatMapLatest)
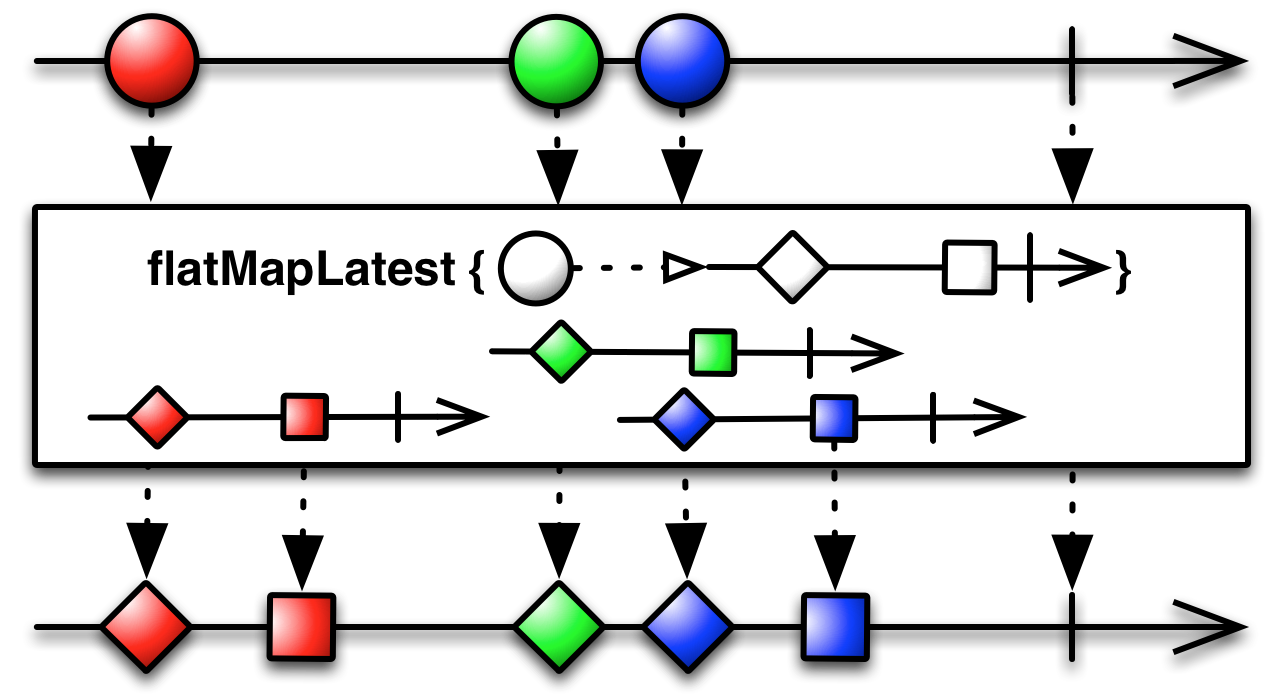
http://reactivex.io/documentation/operators/flatmap.html
先程のmergeMap(flatMap)に似ていますが、親ストリームのうち、最後の子ストリームに流れる値だけを使うように、文字通りswitchするのがswitchMapです。これもRxらしい非常に強力なオペレータです。まずは使っている箇所を見ていましょう。
class LazyLoadable extends React.Component {
...
newItems$(keyword$) {
...
return keyword$.debounceTime(300).switchMap(keyword => {
...
// このkeywordでのitemsのストリームを返す
const itemsForKeyword$ = ...
return itemsForKeyword$;
};
...
}
画面下部の索引・項目の詳細リストはキーワードに依存しているため、キーワードが変更された際は古いキーワードでの結果は不要になります。しかし、例えば以下のような実装をしていると、タイミングによっては古い結果で新しい結果を上書きしてしまうことがあります。
onKeywordChange(keyword) {
fetchByKeyword(keyword).then(items => this.setState({ items: items }));
}
// 1. onKeywordChange('old') を実行
// 2. onKeywordChange('new') を実行
// 3. 2.の結果が返ってくる => newItems をsetState
// 4. 1.の結果が返ってくる => oldItems をsetState <= 古い結果で上書いてしまう
switchMapをデモのように使うことで、新しいキーワードでのストリームが始まった段階で古いストリームを破棄し、新しいストリームにswitchしてくれます。このように「非同期処理の結果が混ざらない」という強力な機能を簡単に実現できるのですが、今回はそこだけでなく、サーバーにやさしい機能として古いストリームを破棄するということに注目します。
Rxはストリームを破棄することに命をかけているといっても過言ではないくらい、不要になったストリームのdispose処理が得意です。このデモでもswitchMapによって不要になった古いストリームはことごとく破棄されるため、concurrencyの制限のために読込待ちになっているfetch処理も、キーワードが変わった段階で読込を行う前に破棄してくれます。
このような恩恵を得るために、中で行われているfetchのような非同期処理もRxのストリームに包む必要があります。これは制限のようですが、これを徹底することで以下のように入力と出力をはっきり分けて考えることができるメリットもあります。
入力 (キーワード, 項目が画面内に表示されたイベント)
↓
Rxの世界
↓
出力 (項目一覧)
Rxの世界では、Rxが状態や時間といった純粋でない世界の事象を扱ってくれるため、Rxを利用するエンジニアが記述する箇所はかなり純粋に記述することができます。複雑に見えますが、追っていくとLazyLoadable#newItems$がthisの状態に依存もしてなければ変更も加えないことがわかると思います。
まとめ
Rxを使って以下のようにサーバー負荷をフロントから低減しました。
-
debounceTimeを使用することで、キーワード入力のような途中経過が不要なAPIコールを削減。 -
mergeMapを使用することでAPIコールのconcurrencyを制御。 -
switchMapを使用して、不要な古い処理を一気に破棄。
ユーザーにやさしい
TL;DR
-
IntersectionObserverとRxJSdebounceTimeを使って、スクロール途中で一瞬しか表示されなかったItemは読み込まない。 - これによってユーザーが見たい箇所のみが読込待ちの状態になり、素早くロードされる。
解説
サーバーにやさしいの章で書いたようにAPIコールのconcurrencyを制限していて、かつ今回のようにAPIの読込が非常に重い状況だと、上から下まで一気にスクロールしたときに、今度は読込待ちのキューが溜まってしまい、ユーザーが見ている箇所がいつまでたっても表示されない、というようなことが起こりえます。
今回はこの問題に以下のような方針で対応しました。
- スクロール中、画面内に表示されたが、すぐに画面外までさらにスクロールして見えなくなった項目は読み込まない。
これは、スクロールで飛ばしている項目はユーザーの興味が薄いという仮説に基づいて、ユーザーがスクロールを緩めた(=興味のある)項目のlazy loadをすぐに始めるための工夫です。
この実装は以下の2つのパートに分解できます。
- 「表示された」「隠れた」のイベントを発火できるようにする。
- 「隠れた」が発火されずに一定時間「表示された」項目のlazy loadを始める。
それぞれ実装を見ていきます。
「表示された」「隠れた」のイベントを発火できるようにする。
ブラウザにやさしいの項目で説明したIntersectionObserverを使ってどちらのタイミングも取得できます。
class Items extends React.Component {
newObserver() {
...
return new IntersectionObserver(entries => {
entries.forEach(entry => {
const target = entry.target;
if (0 < entry.intersectionRatio) {
// 「表示された」
target.dispatchEvent(new Event('appeared'));
} else {
// 「隠れた」
target.dispatchEvent(new Event('disappeared'));
}
});
...
}
}
「隠れた」が発火されずに一定時間「表示された」項目のlazy loadを始める。
サーバーにやさしいの項目で説明したdebounceTimeの出番ですね。
class LazyLoadable extends React.Component {
...
newItem$(key, keyToData$, lazyLoad$) {
...
// scheduleLazyLoad$は、表示されたらtrue,隠れたらfalseが流れます。
// 見やすくするため、console.logを吐いている箇所を削除しています。
const lazyLoadStarted$ = scheduleLazyLoad$
// 500ms以内にtrue -> falseが流れてきた場合はfalseのみを通します。
.debounceTime(500)
// filterは名前のイメージ通り、コールバックの戻り値がtrue相当の場合のみ後続のストリームにつなげます。
// ここまでのストリームで、「500ms以上表示されていた場合」に流れるストリームになります。
.filter(fixed => fixed)
// 一度lazy loadを始めたら2回読み込む必要はないので、firstで始めの1つだけ取得します。
.first()
// lazyLoad$を開始します。(concurrencyによってすぐにはfetchが始まらない場合があります。)
.do(() => lazyLoad$.next(key))
...
debounceTimeは値を間引くだけでなく、このように一定時間内に処理をやめるような使い方もできます。
これをふまえて、デモで適当に下のほうまで一気にスクロールしてみてください。途中読み込んでいない項目があること、スクロールを緩めた箇所はすぐlazy loadが始まるのがわかると思います。ユーザーにやさしいだけでなく、不要な読込処理が減ってサーバーにもやさしいですね。
まとめ
下記の組み合わせで、ユーザーの興味があると思われる箇所だけを読み込むようにすることで、読込待ちの時間を削減しました。
-
IntersectionObserverで「表示」/「隠れた」どちらも取れる - Rxの
debounceTimeを使うことで、一瞬しか表示されなかった項目のlazy loadをキャンセル。
全体のまとめ
今回は、
- 一覧から該当項目にジャンプができる
- スクロールもできる
- 現状の読込がすごく重い
といったやや特殊な要件でのlazy loadを、ブラウザ、サーバー、ユーザーみんなにやさしいやりかたでの実装を目指しました。今回の解決策が全てのケースに当てはまるとは思いませんが、それぞれの要素の一つでも何かのヒントになれば幸いです。
(おまけ)Rxについて
本当はここにエンジニアにもやさしいを追加したいところですが、IntersectionObserverはともかくとして、Rxは正直かなり敷居が高いと思っています。
-
そもそもRxがなんなのかわかる必要がある。
- なんで使わなければいけないのかもわからず使う必要はありません。
- ただしこの記事が少しでもRxの効果を実感する手助けになれば嬉しいです。
-
謎のオペレータ郡をわかる必要がある。
- rxjs5で名前が変わってさらに大混乱。
-
リアクティブプログラミング的な記述に慣れる必要がある。
- そもそもテキストで記述するのには向いていないパラダイムだと個人的には思っているので、慣れの問題じゃない可能性も。
またこの記事では触れていませんが、Hot Observable/Cold Observableの話やエラーハンドリング、RxJSはそこまで気にすることはないですがschedulerなど重要な箇所にも癖があり、とにかくちゃんとわかるまでに時間がかかります。そして、いい加減な理解のまま使うとボロがでやすいという性質もあると思っています。
と、脅しのようになってしまいましたが、きちんと理解すれば強力な武器になります。
- 非同期処理、特に時間が関係する非同期処理を堅牢に記述できる。
- バグりやすい状態管理を一部担ってくれる。
- 入力と出力を意識しやすくなる。
特に時間が関係する非同期処理は最近のフロントならどこにでもある問題にも関わらず自力で管理するのは面倒かつ再現しづらいバグを生みやすい箇所なので、これをRxのようにきちんとメンテされているライブラリに任せられるのはエンジニアとして非常に心強いです。switchMapと唱えるだけで非同期処理が混ざらないなんて夢のようですね!
参考
- Intersection Observer API - Web APIs | MDN (https://developer.mozilla.org/en-US/docs/Web/API/Intersection_Observer_API)
- この1年、Webのパフォーマンスで変わったことは?──HTML5 Conference 2016 (https://html5experts.jp/furoshiki/21501/)
- 【翻訳】あなたが求めていたリアクティブプログラミング入門(http://ninjinkun.hatenablog.com/entry/introrxja)
- ReactiveX - Operators (http://reactivex.io/documentation/operators.html)