本記事では、AuroraServerlessとLambdaとDataAPI(beta版)を使ってシンプルなSlackBotを作ってみたいと思います。
AuroraServerlessはサーバーレスのRDBで、インスタンスを管理する必要がなく、データ容量とIOでの課金です。そのため、低頻度で断続的な使用用途の場合はかなりのコスト削減になります。
Amazon Aurora サーバーレスの詳細はこちらを参照してください
また、今まで、AuroraServerlessは、Lambdaとは相性が悪いと言われていました。ところが、2018/11/21にDataAPI for AuroraServerless(beta版)が発表され、今までにあったLambdaとの相性が悪いと言われる理由となる様々な問題が解決されることが期待されています。
AuroraServerlessとLambdaのやり取りでDataAPIを使う利点はこちらを参照してください
Botのような単発で低頻度なアプリケーションで、かつRDBの機能を使いたい場合は有効活用できそうです。今回は、シンプルなBotでAuroraServerlessとDataAPIとLambdaの使い勝手を試してみます。また、GoのAWS SDKでDataAPIを用いた記事がまだ存在していなかったので、そちらについても書こうと思います。
注意
- 米国東部 (バージニア北部)のみDataAPIに対応
- DataAPIはベータ版のため、仕様が変更される可能性があり
(2019/04/08時点)
目次
- AuroraServerlessを設定する
- AuroraServerlessにDataAPIの設定をする
- GoのAWS SDKを使ってDataAPIにLambdaからアクセスする
AuroraServerlessを設定する
今回は、デフォルトVPCではなく、自分で作成したVPCの中にAuroraServerlessを立てていきたいと思います。
また、基本的にAuroraServerlessのDBクラスターにパブリックなIPアドレスを割り当てることはできず、VPC内からしかアクセスできません。
なので、AuroraServerlessに初期のデータをインポートする際など、コンソールに直接入って操作したい場合はおなじVPC内にEC2を立ててAuroraServerlessに接続します。
基本的なCRUD操作はDataAPIで可能なので、DataAPIのみの使用で十分という場合は不要です。
手順
- VPCの作成
- サブネットの作成
- インターネットゲートウェイの設定
- EC2インスタンスの作成
- AuroraServerlessの作成
- セキュリティグループの設定
1. VPCの作成
VPCを作成します。
2. サブネットの作成
今回は、EC2を配置するパブリックサブネットと、AuroraServerlessを配置するプライベートサブネットを2AZずつ、3つのサブネットを作成します。(パブリック1, プライベート2)
AuroraServerlessは、2AZをまたがるマルチリージョンにしか設定できないため、必ず2AZ分のサブネットを用意する必要があります。
サブネットを作成したら、各サブネットに新規のルートテーブルを紐づけます。
3. インターネットゲートウェイの設定
インターネットゲートウェイを1つ作成し、1で作成したVPCにアタッチします。2で作成したPublicサブネットのルートテーブルに作成したインターネットゲートウェイを設定します。
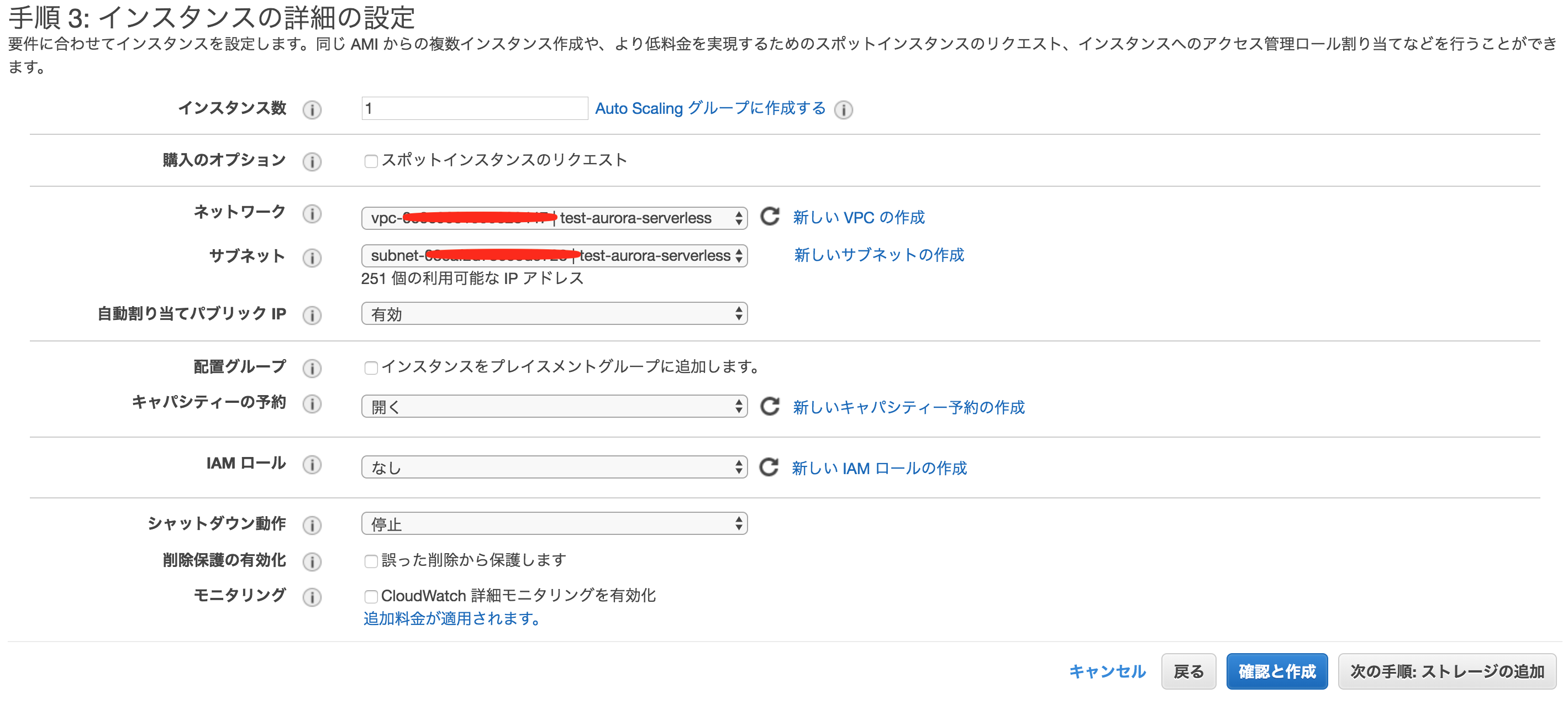
4. EC2インスタンスの作成
VPCの欄には先程作成したVPCを設定し、publicサブネットを選んで設定します。今回は、EC2にsshしたいので、パブリックIPの自動割当を有効にしておきます。
5. AuroraServerlessの作成
上述したように、AuroraServerlessは2AZをまたいだマルチリージョンの上にしか設定する事ができません。
なので、まずはじめに先程作成したプライベートサブネットの2AZ分を束ねるサブネットグループを作成しておきます。
サブネットグループを作成したら、データベースの作成から下記の画面にいき、Auroraを選択します。



また、AuroraServerlessのDB認証用のuser名とpasswordもこのタイミングで設定します。VPCとサブネットグループに関しても設定が必要なので、前段階で設定したものを選びましょう。
6. セキュリティグループの設定
最後に、EC2インスタンスから接続できるように、AuroraServerlessに設定されているセキュリティグループのインバウンド設定に、EC2インスタンスに紐付いているセキュリティグループからの3306ポートのアクセスを許可します。

これで、AuroraServerlessを立ち上げることができました。EC2にsshして、AuroraServerlessのコンソールにアクセスする場合は、EC2にmysqlをインストールします。
sudo yum install -y mysql
mysql -h `auroraサーバーレスの共通エンドポイント` -u username -p
AuroraServerlessは、一定時間使用しないと停止されるため、立ち上がっていない状態からpassowrdを打つとコンソールに入るまでの時間がめちゃくちゃかかります。サーバーにデータストアをアタッチするのに時間がかかっているようで、かかるときには25秒くらいかかるようです。
こちら のやりとりには、立ち上がりが遅いためバックグラウンド処理やバッチ処理などに用途が限定されるといっています。
DataAPIの設定
次に、AuroraServerlessにDataAPIの設定をします。
手順
- DataAPIの設定を有効にする
- SecretManagerにpasswordを登録する
- IAMの設定をする
1. DataAPIの設定を有効にする
まず、DataAPIの設定を有効にします。
設定はとても簡単で、先程設定したAuroraServerlessの設定、 ネットワークとセキュリティ のところのDataAPI項目にチェックを付けるだけです。

次へを押して、変更スケジュールのすぐに適用を押してクラスターの変更をします。
これで、DataAPIの設定は完了です。
AuroraServerlessの詳細画面にはDataAPIの設定が有効になっているのか否かの記述がないため不安になりますが、これだけでちゃんと適用できます。
2. SecretManagerにpasswordを登録する
DataAPIでは、認証もAWS SecretManagerで行うため、DBにアクセスする際のuser名、passwordの入力の認証をする手間を取りません。
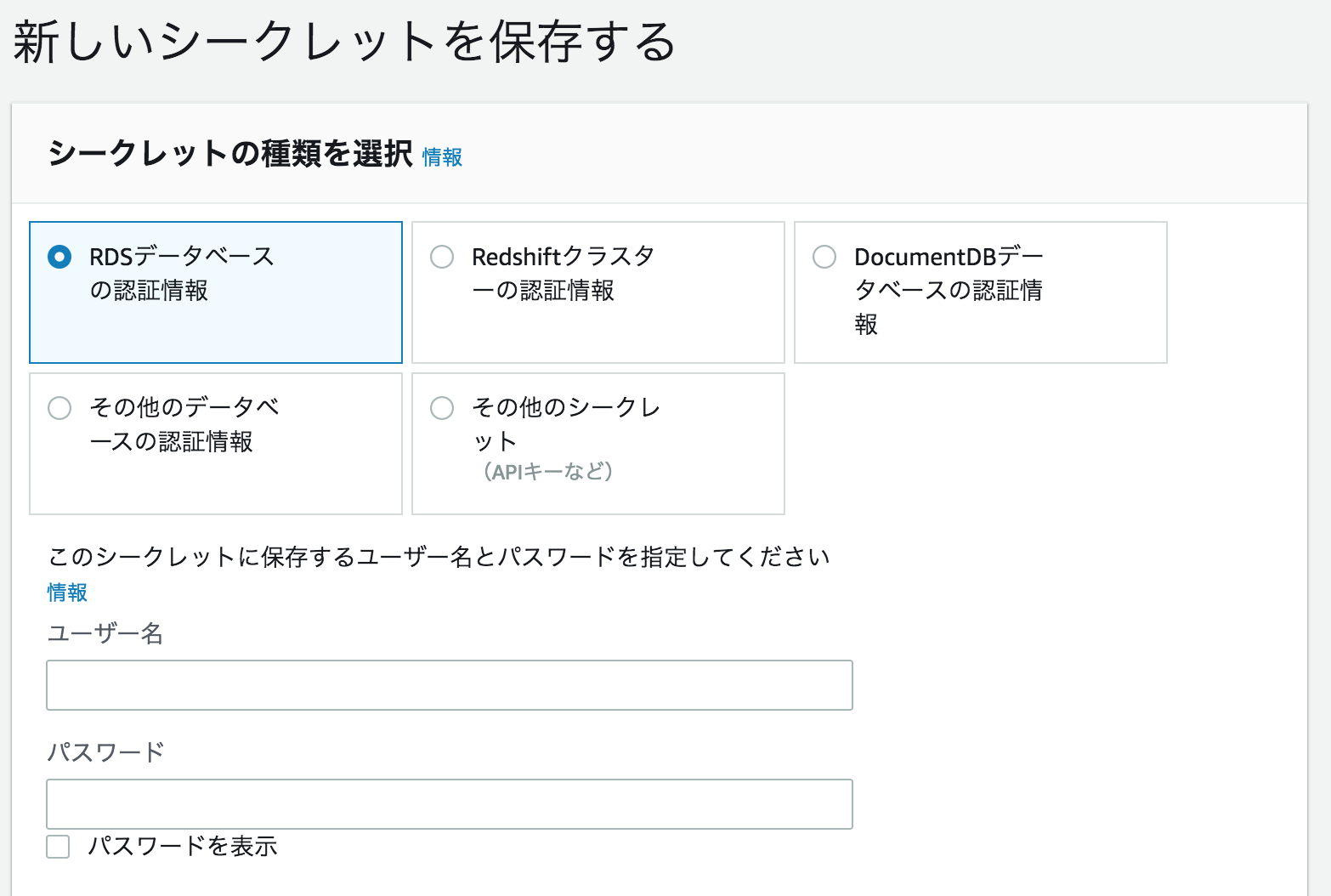
また、ローテーション機能もあり、こちらを有効にすると認証情報が自動でローテされてしまうので注意してください。

3. IAMの設定をする
最後に、実行ユーザーにDataAPIを操作するためのIAMを設定します。
DataAPIを使うために必要な権限は下記です。
secretsmanager:*
rds-data:ExecuteSql
上記の流れで、aws cliを使って下記のように接続することができます。
また、aws cliのバージョンが古く、rds-dataに対応していない場合はアップグレードする必要があります。
aws rds-data execute-sql \
--aws-secret-store-arn arn:aws:secretsmanager:us-east-1:dummydummydummy:secret:dummy/dummydummy/dummy \
--db-cluster-or-instance-arn arn:aws:rds:us-east-1:dummydummydummy:cluster:dummydummydummydummy \
--sql-statements "SELECT * FROM test_db.test_table ORDER BY RAND() LIMIT 1;" \
--region us-east-1 \
--profile yourprofilename
GoのAWS SDKを使ってDataAPIにLambdaからアクセスする
現在(2019/04/08時点)、Pythonなどの言語でDataAPIを使用するには、Lambdaで使用する標準SDKのバージョンより新しいものを意図的に使用しなければ使えません※1。よって、LambdaLayersなどを使ってAWS SDKのバージョンを変更する必要があります。
Goでは好きなSDKのバージョンを手元でビルドして使えるため、現時点では他の言語より手間がなくDataAPIを使うことができます。
せっかくLambdaのサンプルプログラムを書くのでスヌーピーの名言SlackBotを作っていきます。
仕様としては、AuroraServerlessに文言が入っているテーブルを作り、ランダムに1レコードを選択して文言をslackに投げるというものです。
(テーブルのデータ構造)
| key | 内容 |
|---|---|
| id | primary key |
| formed_text | 文言 |
| name | 発言者 |
| name_ja | 発言者(日本語) |
こちらがGoでAWS SDKを用いてDataAPI経由でAuroraServerlessにアクセスする際のSlackBotのソースコードです。
package main
import (
"encoding/json"
"errors"
"log"
"syscall"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-lambda-go/lambda"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/rdsdataservice"
"github.com/nlopes/slack"
)
type SnoopyWord struct {
FormedText string `json:"formed_text"`
Name string `json:"name"`
NameJa string `json:"name_ja"`
}
func handleGetEnvironments(env_name string) (value string, err error) {
value, found := syscall.Getenv(env_name)
if !found {
log.Print("Required Environment not found")
err = errors.New("Required Environment not found")
}
return
}
func handleGetRandomSnoopyWordByAuroraServerless() (snoopyWord *SnoopyWord, err error) {
secretStoreArn, err := handleGetEnvironments("SECRET_STORE_ARN")
dbClusterOrInstanceArn, err := handleGetEnvironments("DB_CLUSTER_OR_INSTANCE_ARN")
svc := rdsdataservice.New(session.New(), aws.NewConfig().WithRegion("us-east-1"))
sqlInput := &rdsdataservice.ExecuteSqlInput{
AwsSecretStoreArn: aws.String(secretStoreArn),
Database: aws.String("snoopy_bot"),
DbClusterOrInstanceArn: aws.String(dbClusterOrInstanceArn),
SqlStatements: aws.String("SELECT formed_text, name, name_ja FROM snoopy_bot.snoopy_words ORDER BY RAND() LIMIT 1;"),
}
output, err := svc.ExecuteSql(sqlInput)
// レコードの内容
record := output.SqlStatementResults[0].ResultFrame.Records[0]
// カラム情報
columnMetaData := output.SqlStatementResults[0].ResultFrame.ResultSetMetadata.ColumnMetadata
snoopyWord = mapToStruct(record, columnMetaData)
return
}
func mapToStruct(record *rdsdataservice.Record, columnMetaData []*rdsdataservice.ColumnMetadata) (snoopyWord *SnoopyWord) {
attributeMap := map[string]string{}
values := record.Values
for ind, value := range values {
attributeMap[aws.StringValue(columnMetaData[ind].Name)] = aws.StringValue(value.StringValue)
}
tmp, err := json.Marshal(attributeMap)
if err != nil {
panic(err)
}
err = json.Unmarshal(tmp, &snoopyWord)
if err != nil {
panic(err)
}
return
}
func handleSendPayload() error {
snoopyWord, err := handleGetRandomSnoopyWordByAuroraServerless()
if err != nil {
panic(err)
}
url := "あなたのwebhook url"
webhookMessage := &slack.WebhookMessage{
Channel: "あなたのチャンネルID",
IconEmoji: ":" + snoopyWord.Name + ":",
Username: snoopyWord.NameJa,
Text: snoopyWord.FormedText,
}
if err := slack.PostWebhook(url, webhookMessage); err != nil {
return err
}
return nil
}
func main() {
lambda.Start(handleSendPayload())
}
今回は、DataAPIの結果を自前で構造体にマッピングしています。
DynamoDBを操作するときは、DynamoDBAttributesというSDKのサービスがあり、DynamoDBのカラムをGoの構造体にUnmarshalするという機能があるのですが、残念ながらまだそのような便利機能はないようです。
DataAPIを呼び出すSDKの関数であるExecuteSqlの返り値のデータ構造は結構複雑で、カラムのデータと値が別々のkeyで返ってきます。(詳しくはドキュメントを参照ください。)
こちらのコードでは、まずはカラムと値をmapに直してから、一度jsonにして構造体にマッピングしています。
AWS SDK for Go API Reference (rdsdataservice)
結果



今回は、DynamoDBでやろうとすると意外と面倒なRandom()関数を使えるところがささやかなRDBの利点でした。
まとめ
とにかくAuroraServerlessは起動にとても時間がかかります。
なので、AuroraServerless/DataAPIは、低頻度なアクセスで、ある程度速度が許容できるものに関して利用するのをお勧めします。
今回のようなBotに使う際には全く問題はありませんでした。
Dynamodbでは、sortやjoin、ランダム関数などが提供されておらず、機能に限界があります。RDBを使うことができれば、その分できることが増えるので用途によってはこちらを使ってみてはいかがでしょうか。
※1 PythonのLambdaの標準のAWS SDKのバージョンは、現時点(2019/04/08)で 1.9.42 でした。RDSDataServiceが入っているSDKのバージョンは 1.9.49 からのため、もしかしたらすでに使えるかもしれません。