独自の物体検出モデルがほしい
物体検出モデルYolov5をかんたんにトレーニングできる
自分で用意したデータを学習させることで、好きな物体を検出できます。
手順
データを用意する
データは
・画像
・画像に対応するアノテーション・テキスト・ファイル
を画像フォルダとテキスト・フォルダに分けて、同じ名前で用意します。
例えば、image1.jpgに対応するimage1.txtというアノテーション・テキスト・ファイルを作ります。
アノテーション・テキスト・ファイルには、オブジェクトごとに1行ずつ、以下を記述します。
class x_center y_center width height
ボックス座標は、正規化されたxywh形式(0〜1)である必要があります。
ボックスがピクセル単位の場合は、画像の幅と画像の高さで割ります。
クラス番号は0から始まります。
以下のようなアノテーション・サービスを使って画像のボックスとラベルをテキストにします。
アノテーションが終わったら、以下のようなディレクトリ構成にまとめます。
trainはトレーニングに使うデータ
valはモデルの学習状況の検証に使うデータ
で、8:2程度で全体のデータを振り分けるのが一般的だと思います。
my_dataset
|
|__images
| |__train
| | |__image1.jpg
| | |__image2.jpg
| | |__...
| |
| |_val
| |__val_image1.jpg
| |__val_image2.jpg
| |__...
|
|
|__labels
|
|__train
| |__image1.txt
| |__image2.txt
| |__...
|
|__val
|__val_image1.txt
|__val_image2.txt
|__...
データセットは、GoogleDriveなどをマウントして参照するより、トレーニングするマシンのローカルにおいておいた方が高速にトレーニングできるとのことです。
Configファイルの記述
トレーニングの構成を指示するファイルを作ります。.yaml ファイルに以下を記述します。
・画像パス
・クラス数
・クラス名の配列
を記述します。
path: ../datasets/my_dataset # データセットのルート・ディレクトリ
train: images/train # トレーニング画像ディレクトリ(上の"path"からの相対パス)
val: images/val # 検証画像ディレクトリ(上の"path"からの相対パス)
test: # テスト画像ディレクトリ(オプション)
# Classes
nc: 80 # number of classes
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ] # class names
Yolov5のインストール
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt
トレーニング
以下を指定してトレーニング・スクリプトを開始します。
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt
引数は以下のとおりです。
・画像サイズ(正方形の縦横)
・トレーニング・バッチ数(一度にモデルに入力するデータ数)
・エポック(何回トレーニング・ループを回すか)
・データ構成ファイル・パス(上記で作った構成ファイル)
・事前トレーニング済み重み(一般的なデータセットで学習された重みを用いる)
*事前トレーニング済みの重みを用いずに、1からランダムな重みでトレーニングするときは
--weights '' --cfg yolov5s.yaml
と引数を指定することもできますが、ランダムな重みからの学習は非推奨となっています。
事前トレーニング済みの重みは公式リポジトリから入手できます。
処理速度と精度とモデルサイズによって、いくつかのモデルから選べます。
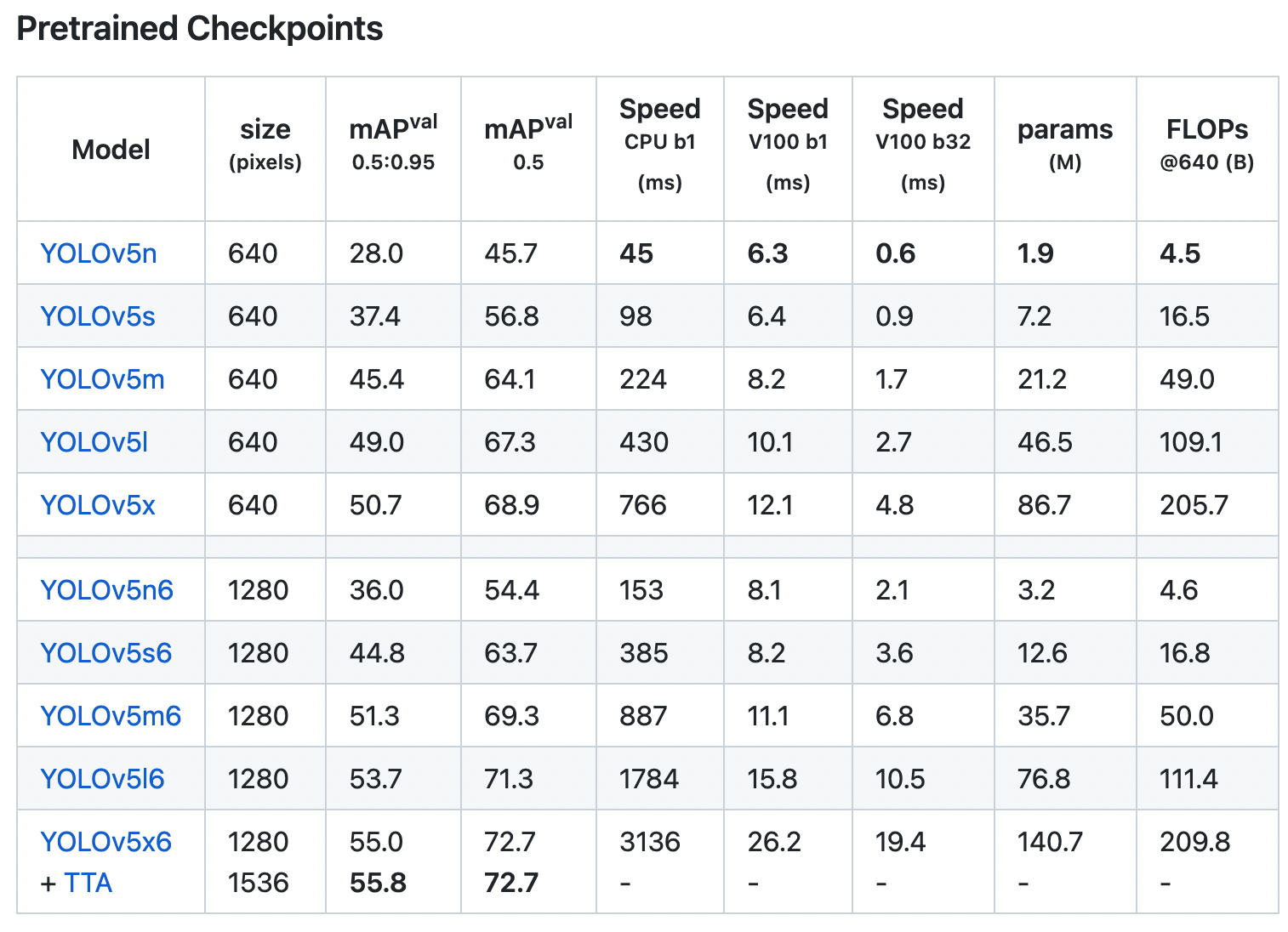
画像サイズは、任意の大きさを指定できますが(正方形)、モデルのデフォルト・サイズ(上記表のsize)に合わせてリサイズするのがいいようです(作者によると)。元の画像からスケールダウンしても、データ量が十分であれば妥当な結果を得られるとのことです。
Colabで10エポックなら数分で終わります。
十分なデータがあれば、これぐらいの学習量でうまく検出できます。
結果は
runs/train/exp
に記録されます。
ここに、
トレーニング済みのWeight
トレーニング・マトリックス(Precision、Recall、mAPなど)のログ
トレーニング・マトリックス(Precision、Recall、mAPなど)のグラフ
検証データの推論結果
などが保存されます。

*画像は公式リポジトリより引用しました。https://github.com/ultralytics/yolov5
推論
トレーニングしたモデルで推論を実行するには、以下のようにWeightを指定して推論スクリプトを実行します。
python path/to/detect.py --weights runs/train/exp/weights/best.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
CoreML
iOS用にエクスポートして使う手順は以下の記事。
🐣
フリーランスエンジニアです。
お仕事のご相談こちらまで
rockyshikoku@gmail.com
Core MLやARKitを使ったアプリを作っています。
機械学習/AR関連の情報を発信しています。